import pandas as pd
from completejourney_py import get_data
cj_data = get_data()
transactions = cj_data['transactions']
products = cj_data['products']
demographics = cj_data['demographics']
# Merge datasets to enrich transaction data
df = (transactions
.merge(products, on='product_id', how='left')
.merge(demographics, on='household_id', how='left'))13 Intro to Data Visualization with Pandas
Data visualization is a core skill in any data analyst’s toolkit. While numbers and statistics tell part of the story, charts and graphs help us understand patterns, uncover insights, and communicate findings more effectively. There are two primary use cases for visualization in data science:
- Exploratory Visualization – These are quick, often simple charts we create during analysis to help us explore our data. For example, histograms help reveal the shape of distributions, bar plots summarize group-level differences, and scatterplots surface relationships. These visualizations help answer questions like:
- “Is there an outlier in the data?”
- “Does spending vary by age group?”
- “Are there seasonal trends in sales?”
- Explanatory Visualization – These are polished, often customized visuals used to communicate findings to stakeholders. They help tell a story with data, emphasizing clarity, aesthetics, and focus. A good explanatory chart might show:
- The total revenue trend across quarters
- The customer segment driving most of the profit
- The success of a new marketing promotion
In this chapter, we focus on exploratory visualization using Pandas, a quick and powerful way to visually explore data and uncover insights — all within the same environment where your analysis lives. In future chapters, we’ll dive deeper into refining visualizations for explanatory purposes, showing how libraries like Matplotlib* and Bokeh can help you tell compelling, professional-grade data stories.
The Python visualization ecosystem is vast and can come across as daunting at first. In fact, PyViz is a website that was created for the sole purpose of helping users decide on the best open-source Python data visualization tools for their needs. I highly recommend you take some time to explore the resource.
By the end of this chapter, you will be able to:
- Create univariate plots based on Series
- Create bivariate plots based on DataFrames
Note📓 Follow Along in Colab!
As you read through this chapter, we encourage you to follow along using the companion notebook in Google Colab (or other editor of choice). This interactive notebook lets you run code examples covered in the chapter—and experiment with your own ideas.
👉 Open the Pandas Data Viz Notebook in Colab.
13.1 Prerequisites
We’ll use the completejourney_py data to analyze household shopping behavior. First, import the libraries and prepare your data:
13.2 The .plot Attribute
One of the most convenient aspects of using Pandas for data visualization is that Series and DataFrame objects come equipped with a built-in .plot attribute. This attribute serves as a simple wrapper around the powerful Matplotlib library (which we’ll discuss in the next chapter), enabling you to generate a wide range of plots with minimal code.
This .plot attribute is a little unique as you can call it as a method and specify the plot of interest using an argument:
df.plot(kind='scatter', ...)Or you can use it to access sub-methods:
df.plot.scatter(...)There are several plotting options via .plot, including but not limited to:
line: (default) for time series or continuous databar/barh: for categorical comparisonshist: for distributions of continuous variablesbox: for spotting outliers and summary statisticsscatter: for examining relationships between two numeric variables
Here’s a simple example of a histogram created from a Series:
df['sales_value'].plot.hist(bins=20, log=True)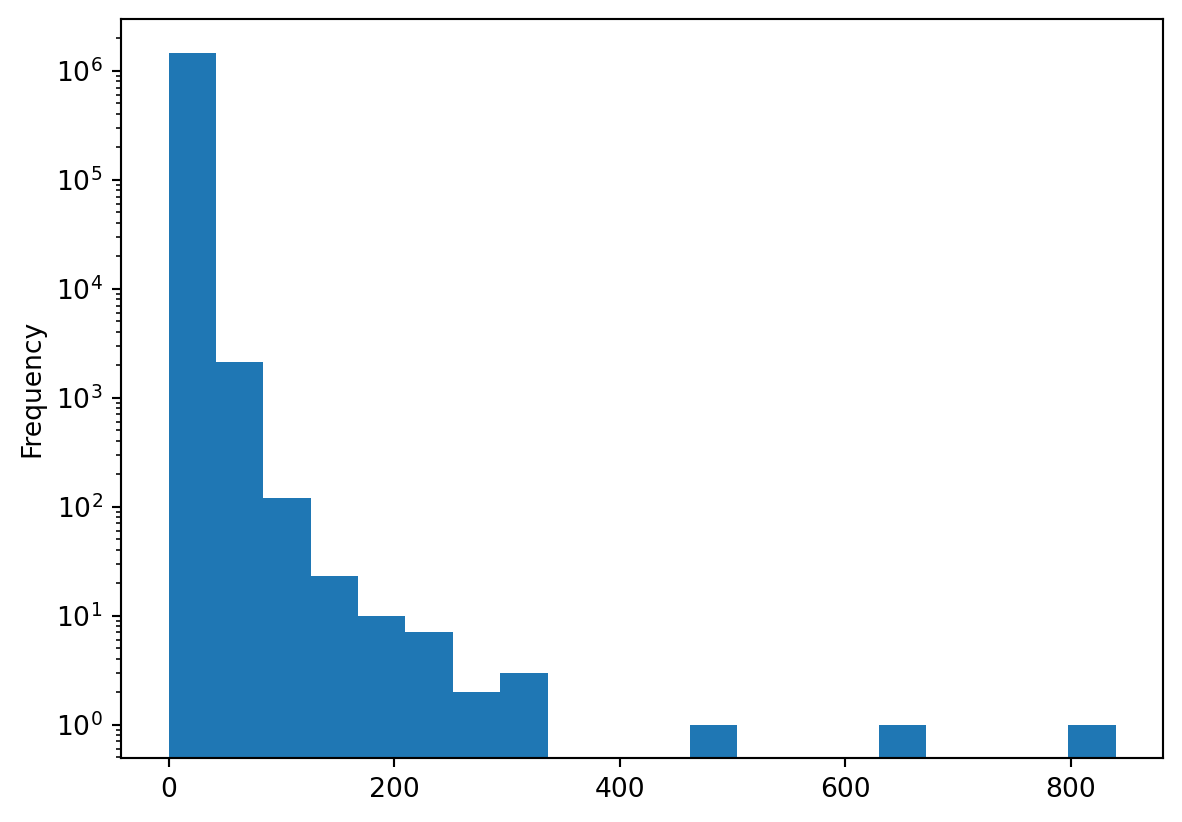
🔍 Knowledge Check
NoteDo This!
Check out the .plot documentation for Series and DataFrames.
- What parameter would you use to control the figure size?
- What parameter would you use to add a title?
- What parameter(s) would you use to log scale an x and/or y axis?
13.3 Visualizing Single Variables (Univariate Plots)
Univariate plots help us understand the distribution, range, and key characteristics of a single variable. These visualizations are especially useful during exploratory data analysis, where you want to:
- Spot patterns, such as skewness or multimodality
- Identify outliers or unusual values
- Compare distributions across different groups (later, with grouping)
Common types of univariate plots include:
- Histograms: Show the distribution of a numerical variable by dividing values into bins.
- Boxplots: Display the median, quartiles, and potential outliers in a compact format.
- Bar plots (for categorical variables): Visualize frequency or total values across discrete categories.
These plots are quick to generate and provide immediate insight into the shape and spread of your data. Let’s look at a couple of examples using the sales_value variable. We’ve already looked at some summary stats of our sales_value distribution…
df['sales_value'].describe()count 1.469307e+06
mean 3.128032e+00
std 4.290385e+00
min 0.000000e+00
25% 1.290000e+00
50% 2.000000e+00
75% 3.490000e+00
max 8.400000e+02
Name: sales_value, dtype: float64but we can understand more by visualizing this variable. But if we look at a basic histogram it doesn’t tell us a whole lot because we have several zero dollar transactions (i.e. returns) in our data plus this feature is heavily skewed towards low value transactions (measured by cents or single dollar values).
df['sales_value'].plot.hist()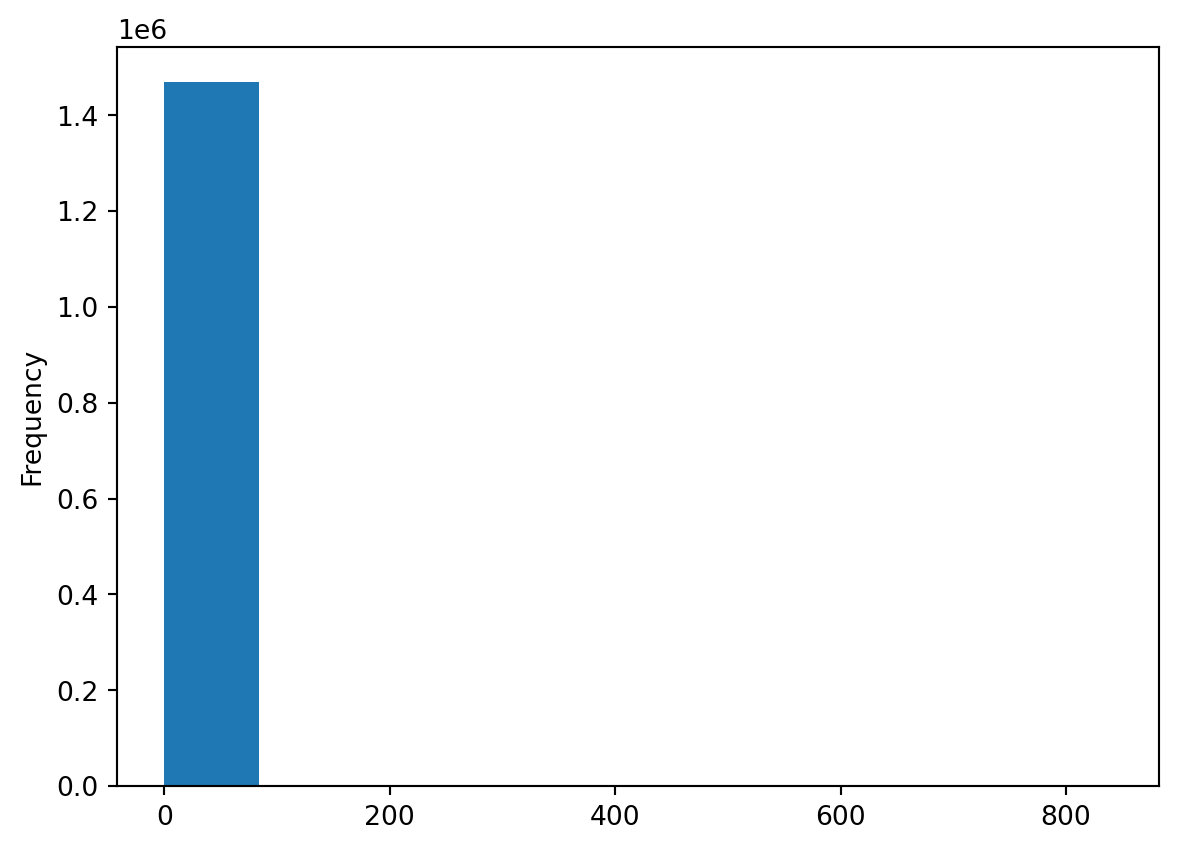
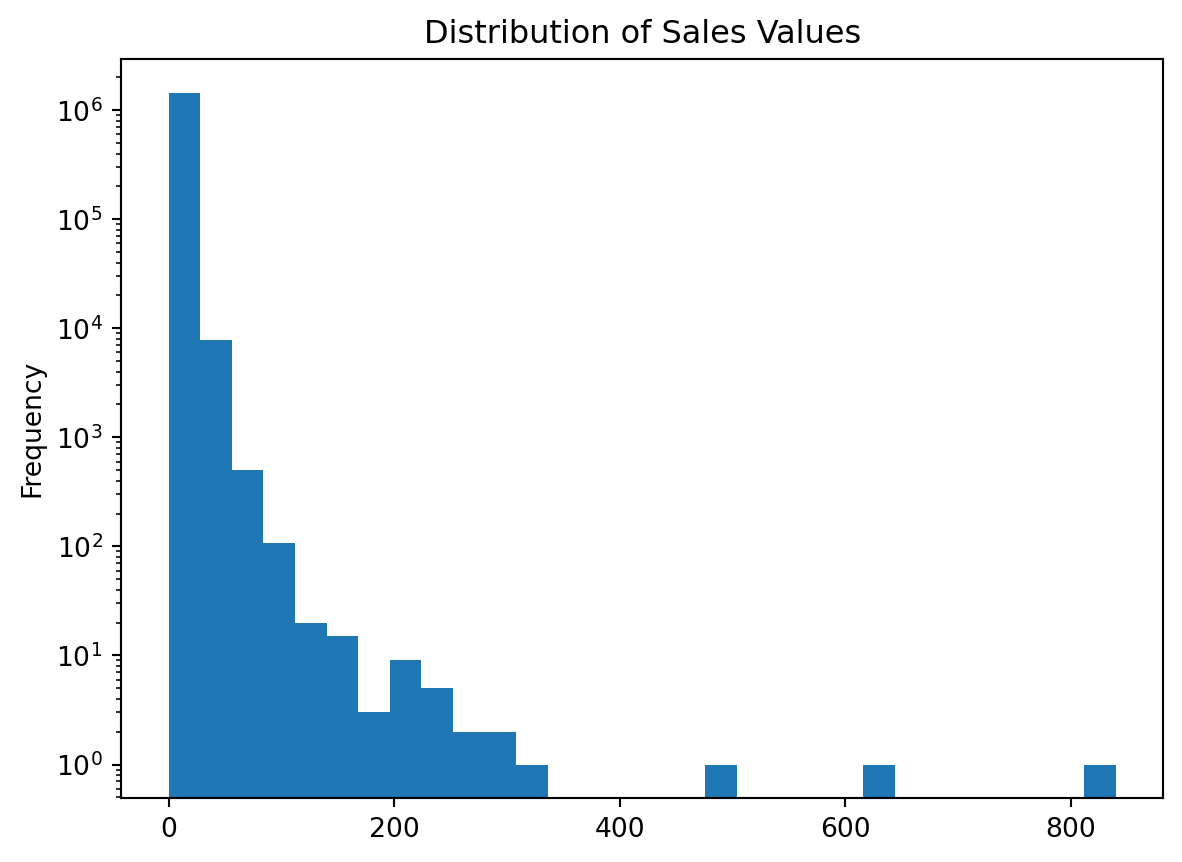
We can make some adjustments such as remove any zero dollar transactions, log transform our axis, and increase the number of bins. This helps to pull out additional insights in our sales_value distribution. For example, we see we have a lot of very low dollar transactions and the frequency decreases as the transaction dollar amount increases. However, we also see an increase in transactions right at the $200 mark but that decreases quickly. There are also a few outlier transaction values that are around the $600 and $800 value marks.
(
df.loc[df['sales_value'] > 0, 'sales_value']
.plot.hist(log=True, bins=30, title='Distribution of Sales Values')
);
Box plots and kernel density estimation (KDE) plots are an alternative way to view univariate distribtions. For example, let’s compute the total sales_value across all stores. The resulting sales_by_store object is a Series. A boxplot provides a lot of information (read about them here). We can see that the median (red line) is around \(10^2 = 100\) and the interquartile range is within the blue box. We also see we have some outliers on the upper end.
sales_by_store = df.groupby('store_id')['sales_value'].sum()
# boxplot
sales_by_store.plot.box(logy=True, title='Distribution of total sales across all stores');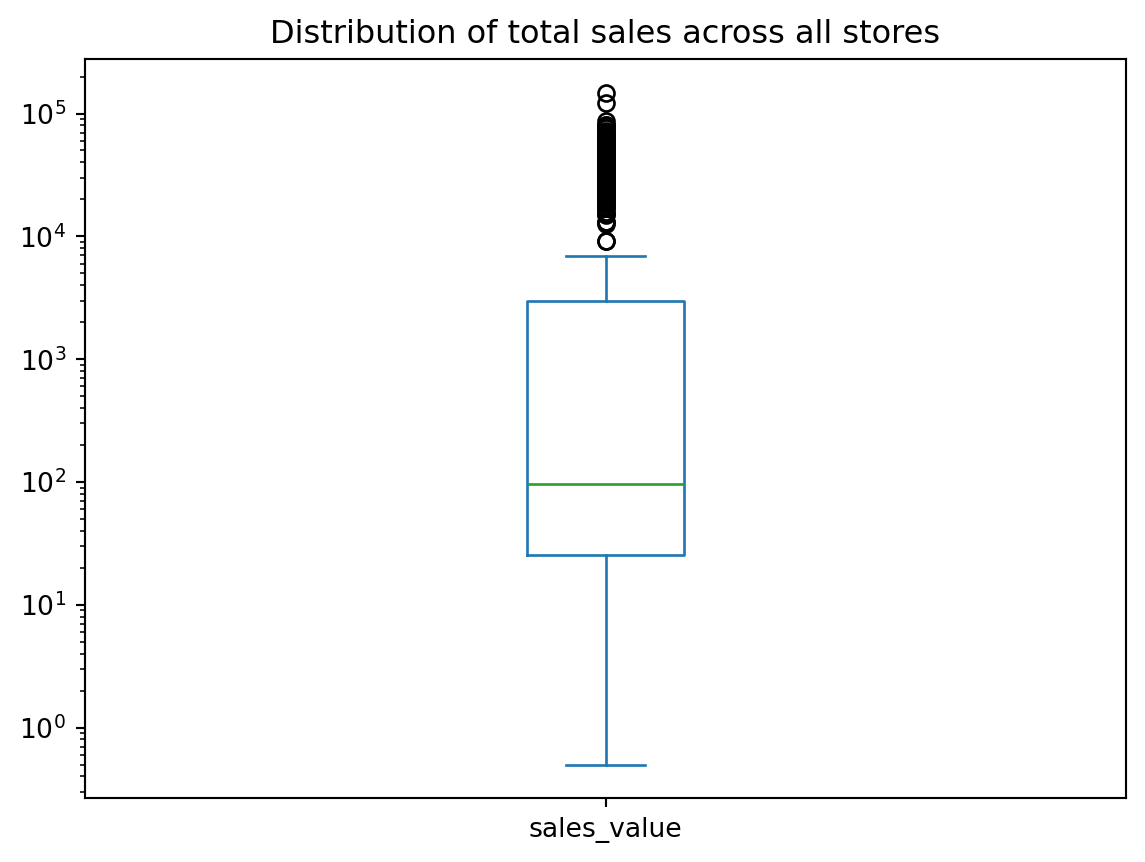
We can quickly compare our boxplot with our numeric distribution and we see our they are similar (median: 96, interquartile range: 25-2966).
sales_by_store.describe()count 457.000000
mean 10056.979387
std 20671.239346
min 0.500000
25% 25.390000
50% 95.590000
75% 2965.560000
max 148169.670000
Name: sales_value, dtype: float64The KDE plot (which is also produced with .plot.density()) provides a smoothed histogram.
sales_by_store.plot.kde(title='Distribution of total sales across all stores');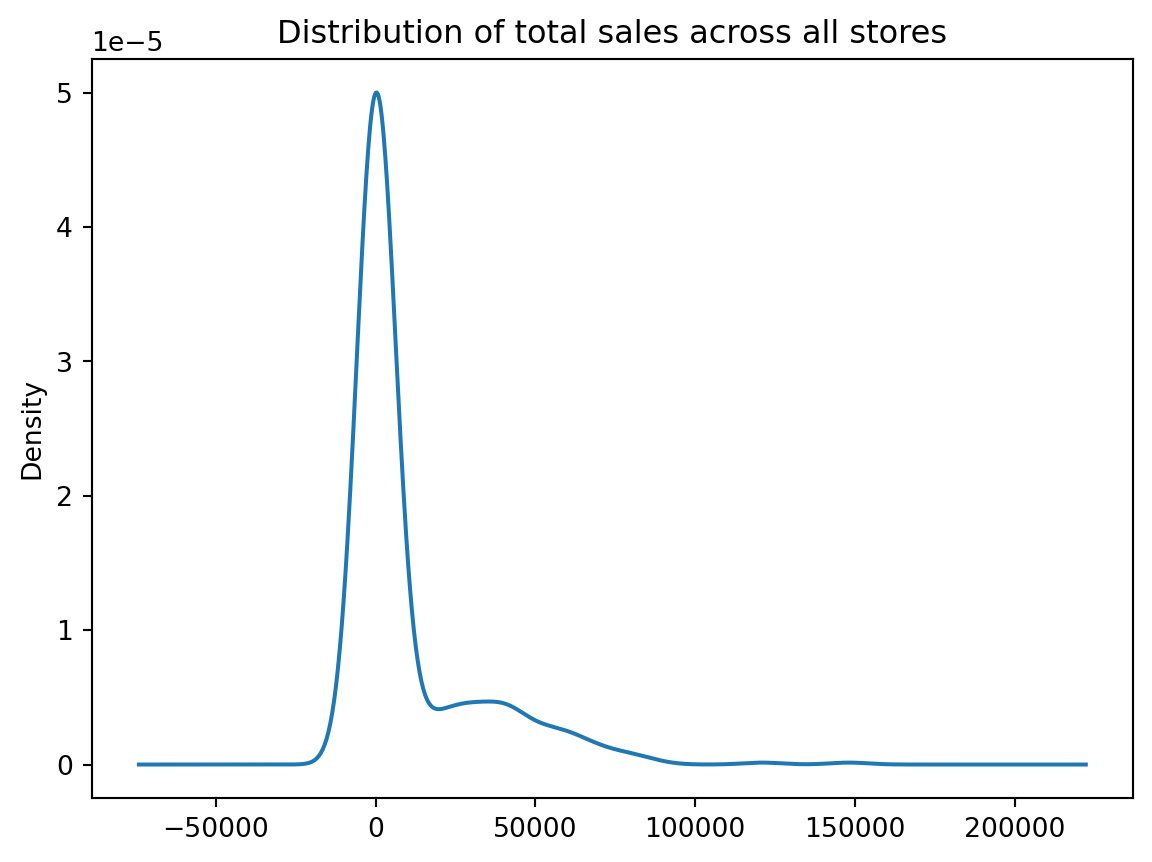
The .plot sub-methods work exceptionally well with time series data. To illustrate, let’s create a Series that contains the sales_value of each transaction with the transaction_timestamp as the index.
sales = df.set_index('transaction_timestamp')['sales_value']
sales.head()transaction_timestamp
2017-01-01 11:53:26 0.50
2017-01-01 12:10:28 0.99
2017-01-01 12:26:30 1.43
2017-01-01 12:30:27 1.50
2017-01-01 12:30:27 2.78
Name: sales_value, dtype: float64A handy method we have not talked about is resample() which allows us to easily convert time series data. For example, if we wanted to sum all sales_values by the hour we can use .resample('h') followed by .sum().
sales.resample('h').sum()transaction_timestamp
2017-01-01 11:00:00 0.50
2017-01-01 12:00:00 19.76
2017-01-01 13:00:00 41.92
2017-01-01 14:00:00 97.31
2017-01-01 15:00:00 769.62
...
2018-01-01 00:00:00 607.66
2018-01-01 01:00:00 524.89
2018-01-01 02:00:00 493.45
2018-01-01 03:00:00 256.74
2018-01-01 04:00:00 10.52
Freq: h, Name: sales_value, Length: 8754, dtype: float64If we followed this sequence of code with plot.line() we get a line plot of the total sales values on the y-axis and the date-time on the x-axis.
(
sales
.resample('h')
.sum()
.plot.line(figsize=(10,4))
);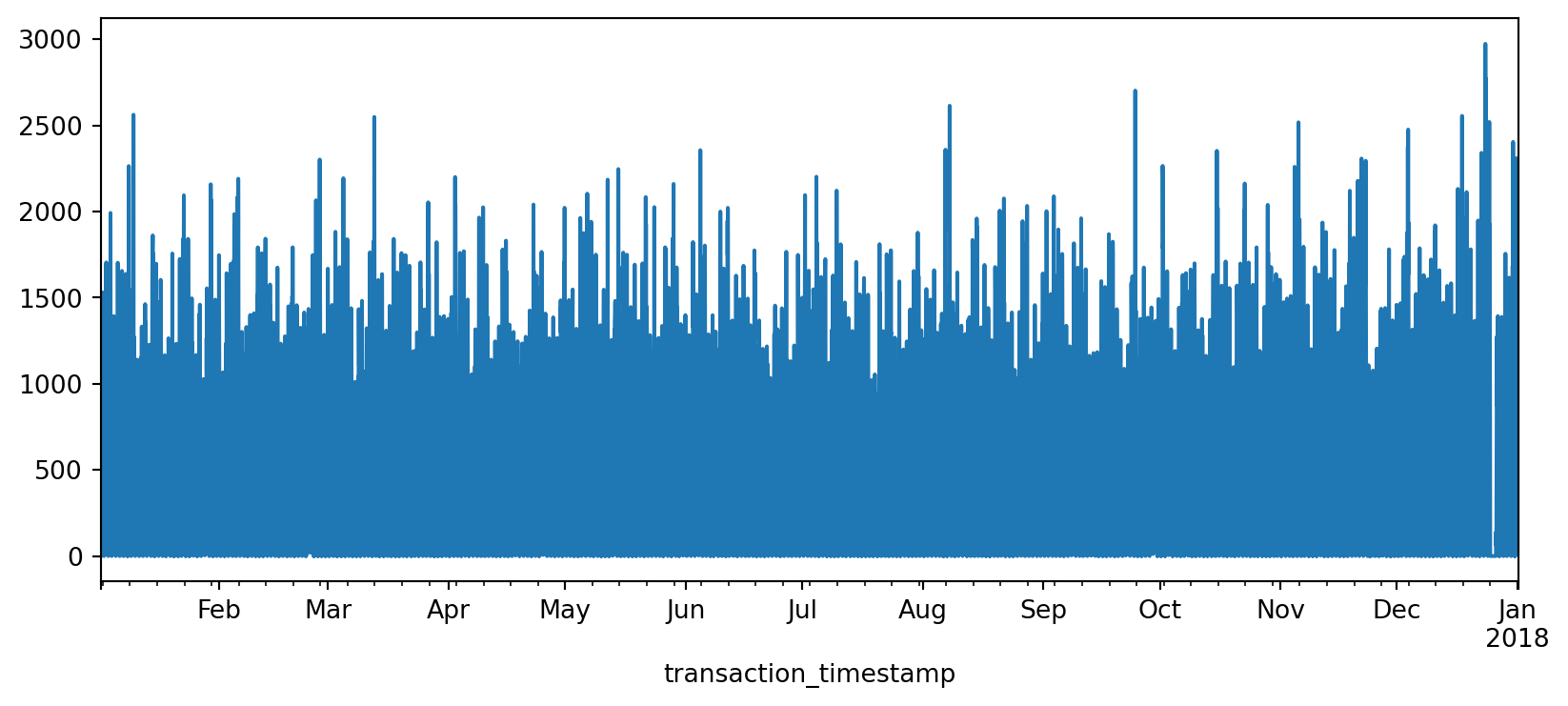
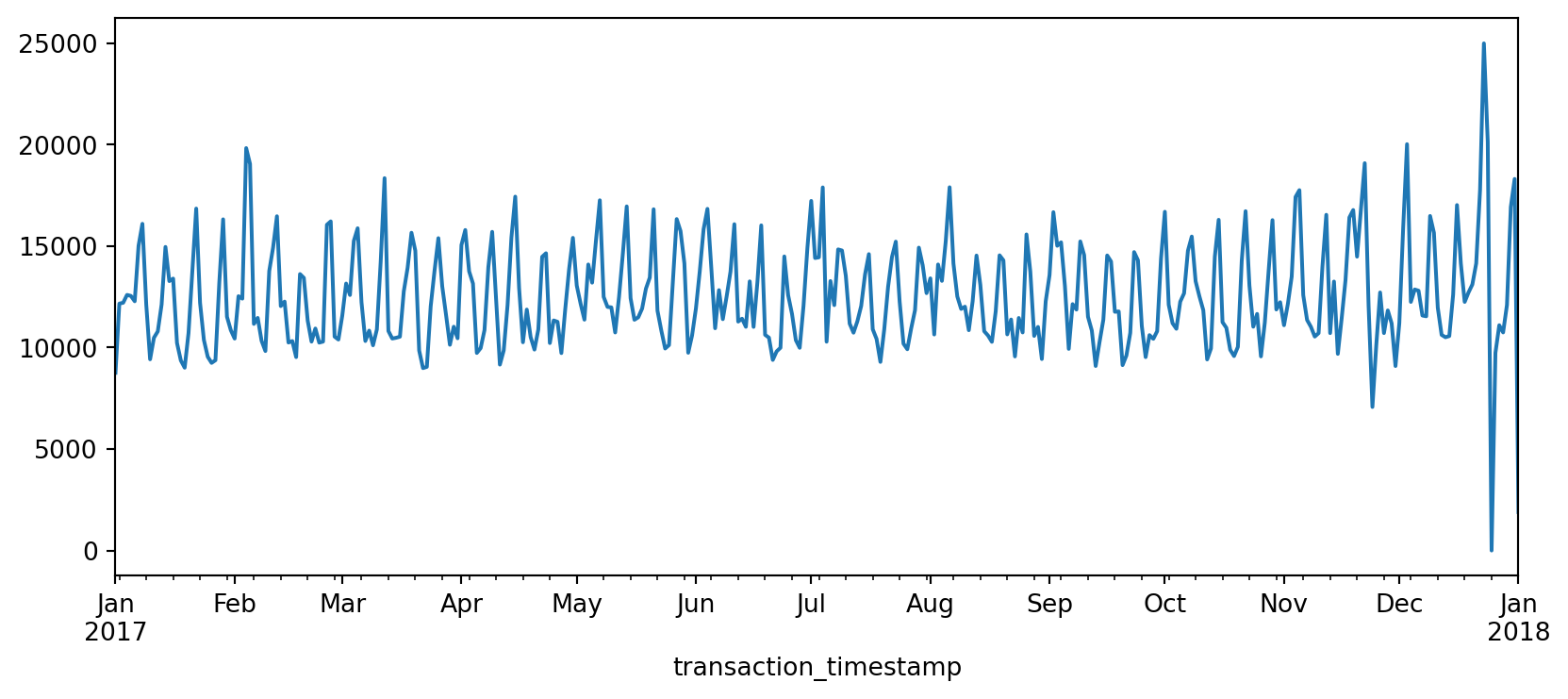
The above plot is a bit busy since we’re plotting values for every hour over the course of a year. Let’s reduce the frequency and, instead, sum the sales_values by day (.resample('D')). Now we see a bit more of a descriptive pattern. It looks like there is routinely higher sales transactions on particular days (probably certain days of the week such as weekends).
(
sales
.resample('D')
.sum()
.plot.line(figsize=(10,4))
);
Let’s validate our assumption above regarding the weekly shopping pattern. The below code chunk performs the same as above where we compute total daily sales across all days of the year but then we follow that up by extracting the name of the weekday from the date-timestamp and then grouping by the day of week and computing the median and interquartile range (IQR) for all daily sales for the year.
If you have not yet seen code that looks like lambda idx: idx.day_name() do not worry. These are called lambda (anonymous) functions and we’ll discuss them more in a future chapter.
We definitely see that Saturday and Sunday are the weekdays with the heaviest sales value transactions.
day_order = [ 'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
total_sales_by_weekday = (
sales
.resample('D') # resample by day
.sum() # compute total daily sales
.rename(lambda idx: idx.day_name()) # extract week day name from date-timestamp
.groupby('transaction_timestamp') # group by day of week
.quantile([.25, .5, .75]) # compute median and IQR of sales values
.unstack() # flatten output (results in a DataFrame)
.reindex(day_order) # force index to follow weekday order
)
total_sales_by_weekday.plot.line(title='Median and IQR of total sales by weekday', figsize=(10,4));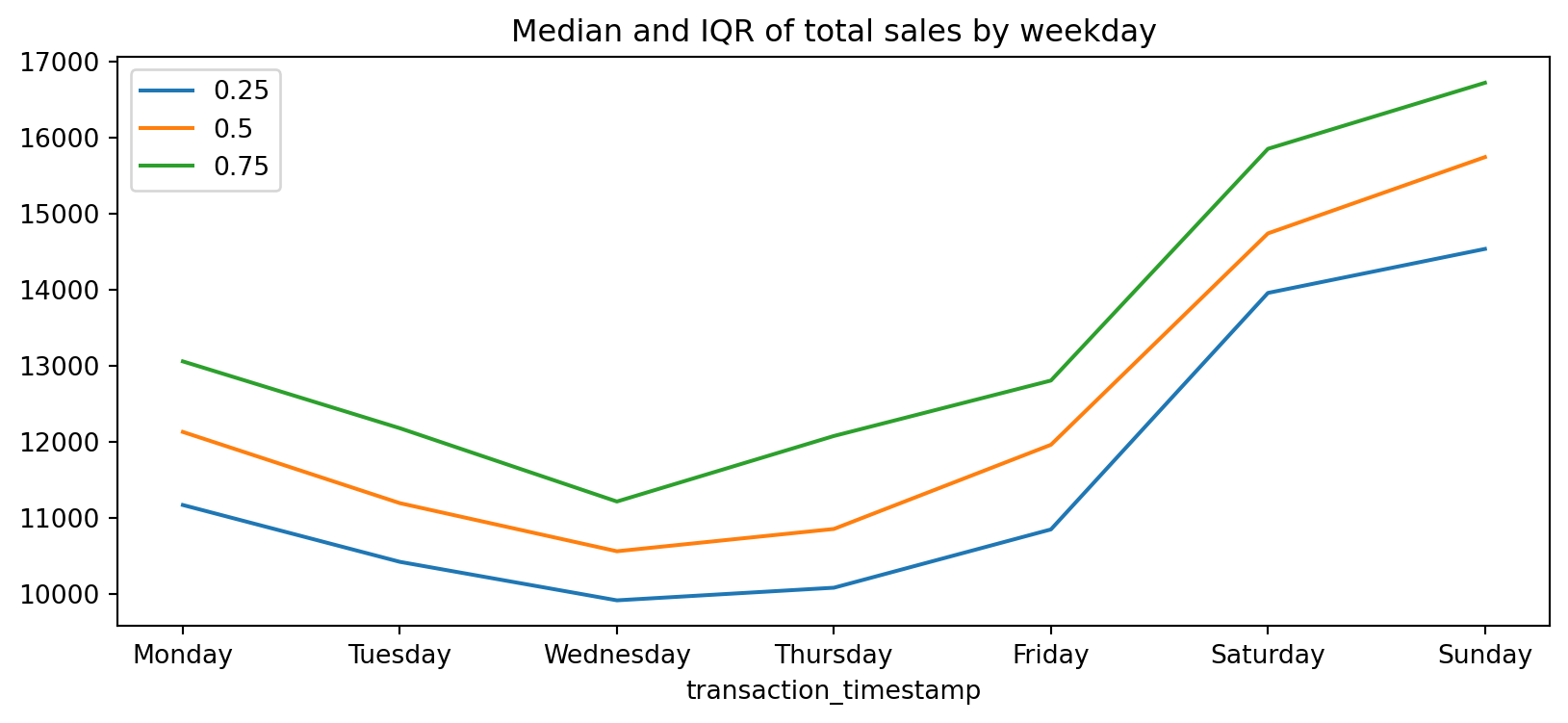
Another common plot for Series data is the bar plot. Let’s look at the median values from the analysis above. If we peak at the result we see we have a Series that contains the median total sales values for each weekday.
median_sales_by_weekday = total_sales_by_weekday[0.50]
median_sales_by_weekdaytransaction_timestamp
Monday 12129.070
Tuesday 11191.945
Wednesday 10558.995
Thursday 10852.630
Friday 11959.995
Saturday 14741.720
Sunday 15745.450
Name: 0.5, dtype: float64Rather than plot this as a line chart as we did above, we can use .plot.bar() to create a bar plot:
median_sales_by_weekday.plot.bar(title='Median total sales by weekday', figsize=(8,4));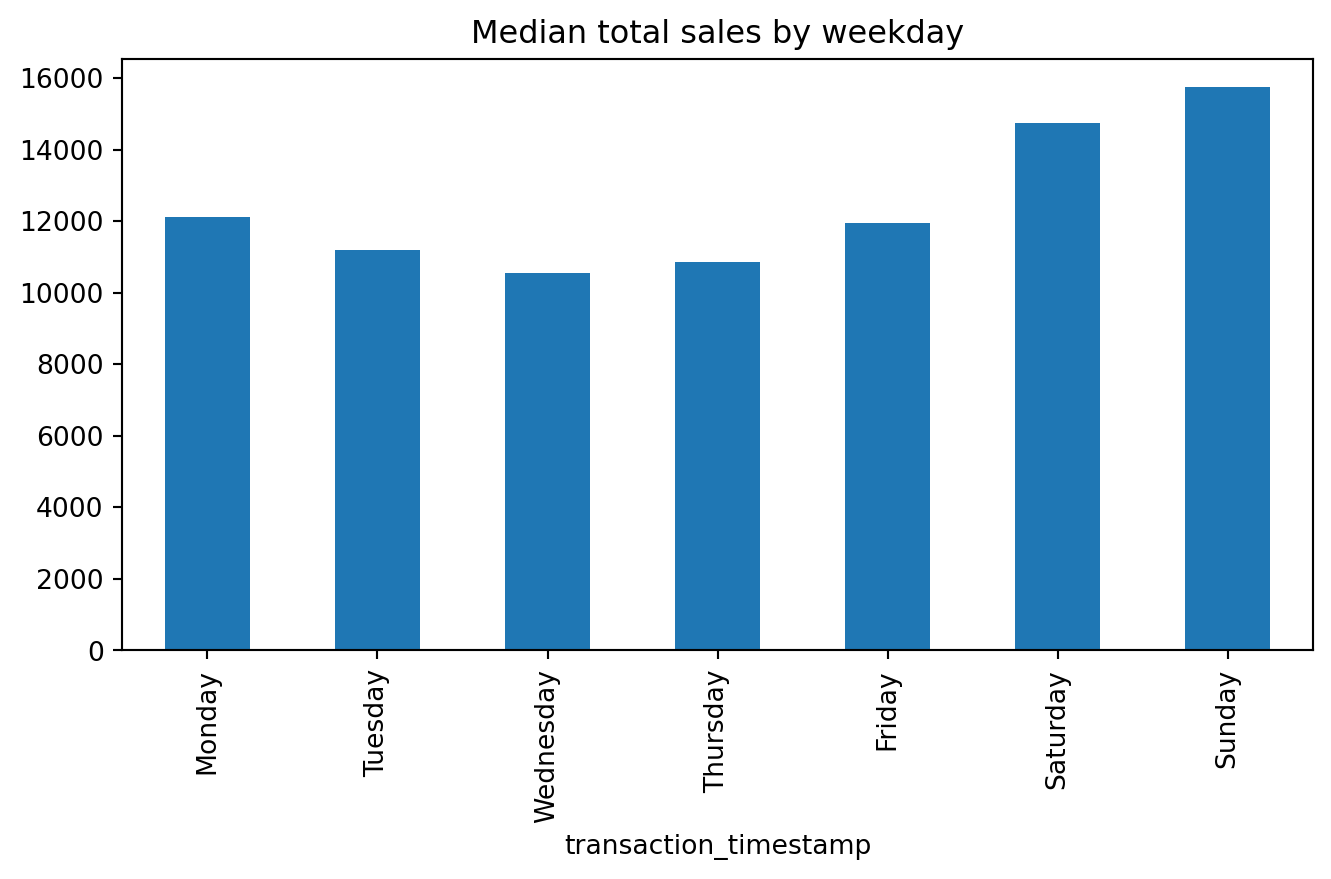
A common pattern you’ll use is to follow a .value_counts() method call with a bar plot. For example, say we want to assess the number of transactions in our data by department. We could easily get this with the following:
(
df['department']
.value_counts(ascending=True)
.plot.barh(title='Total transactions by department', figsize=(6,8))
);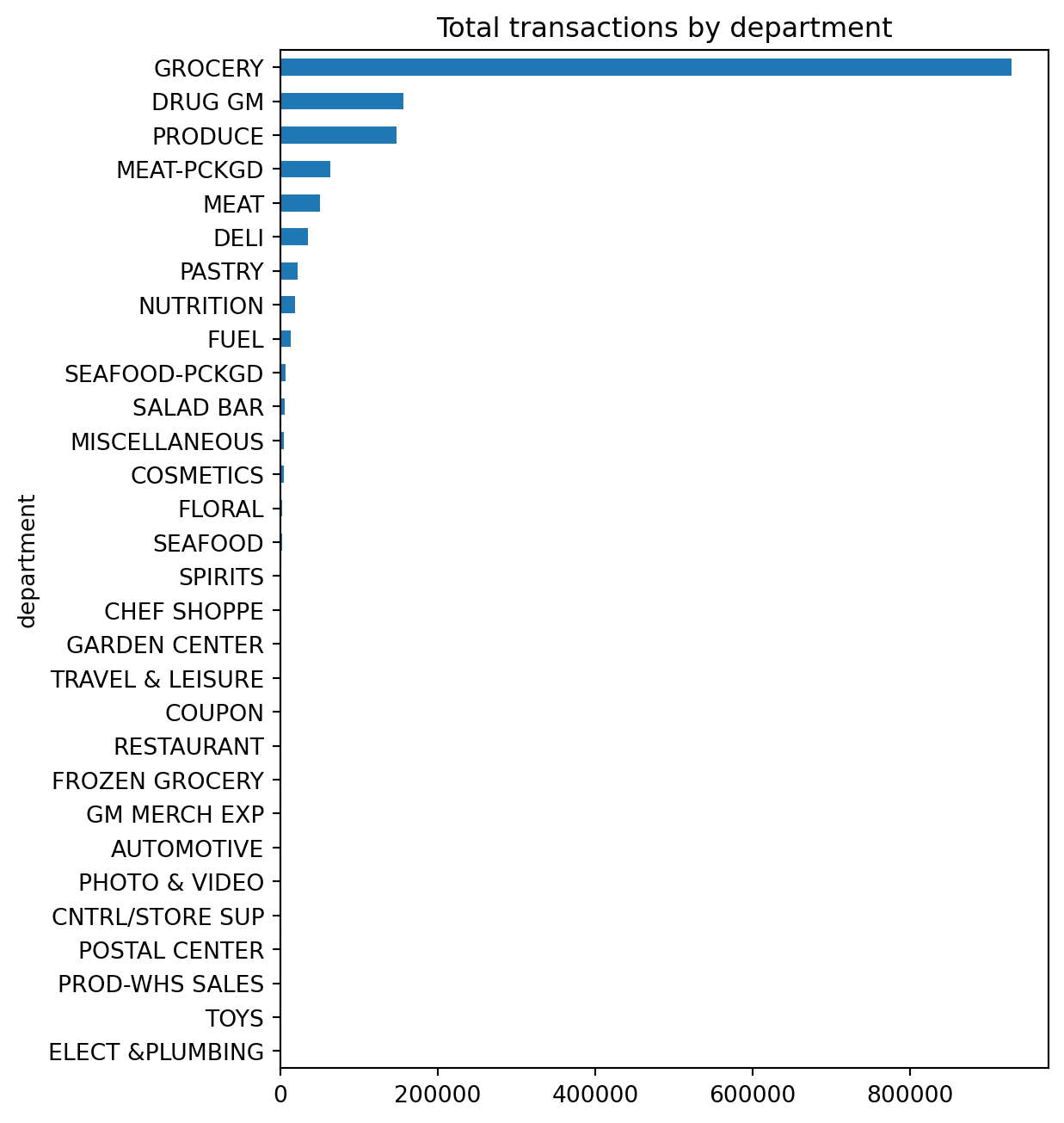
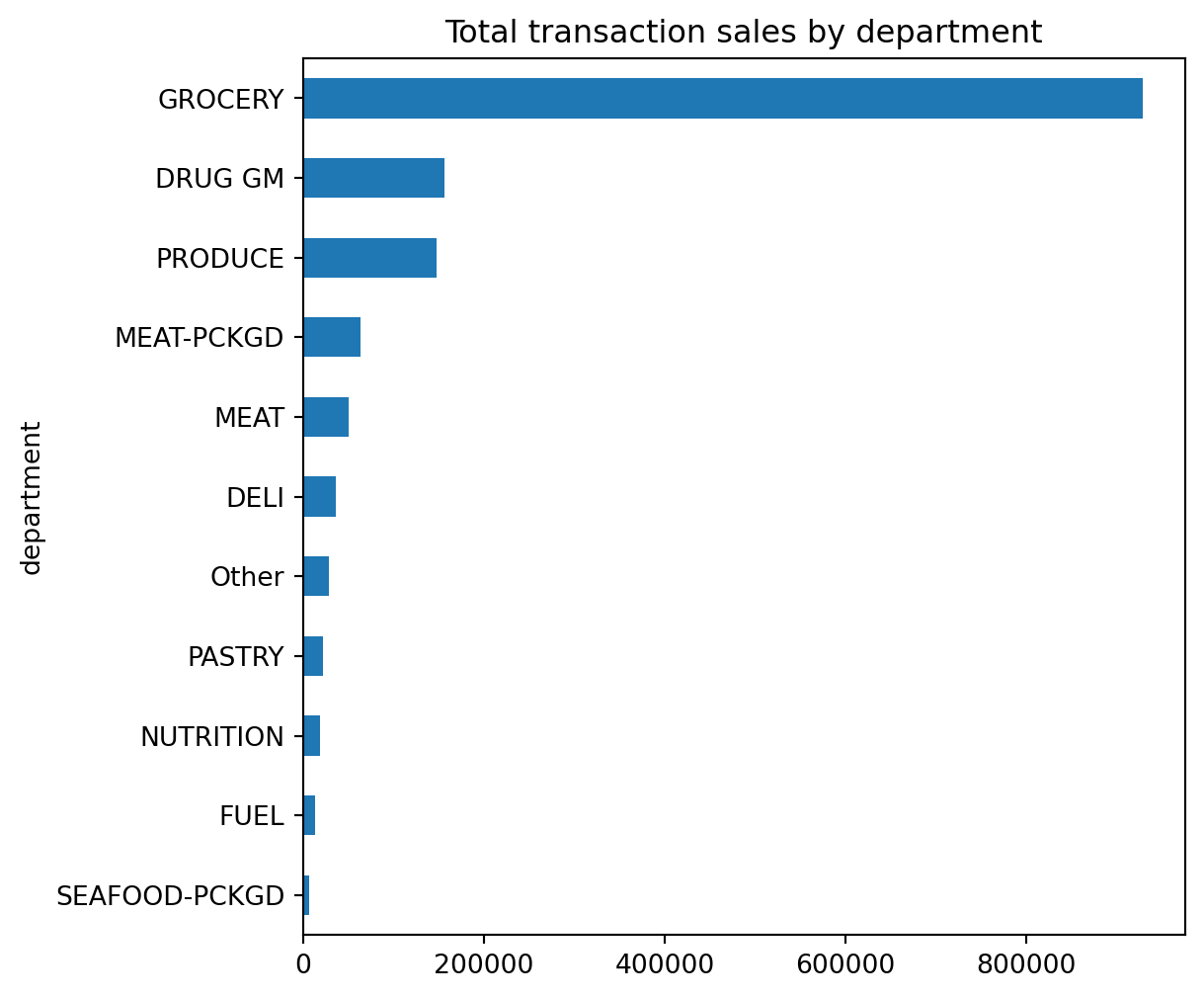
Unfortunately, we see a lot of very small values that overcrowds the plot. We can make some small adjustments to our code to leave all department values for those departments in the top 10 as is but for all departments not in the top 10 we can condense them down to an ‘Other’ category.
We will discuss the .where() method in a later module. For now just realize its a way to apply an if-else condition to a Series.
top10 = df['department'].value_counts().index[:10]
isin_top10 = df['department'].isin(top10)
(
df['department']
.where(isin_top10, 'Other')
.value_counts(ascending=True)
.plot.barh(title='Total transaction sales by department', figsize=(6,6))
);
🔍 Summary: Exploring Univariate Distributions Through Iteration
This section demonstrates how we can iteratively filter, aggregate, and visualize data to better understand the distribution and characteristics of a single variable — in this case, sales_value. Starting with basic summary statistics, we build deeper insights by:
- Filtering out uninformative records (e.g., $0 transactions)
- Aggregating data at relevant levels (e.g., by basket or store)
- Applying different types of univariate plots (histograms, boxplots, KDEs) to reveal patterns, outliers, and skew
Through this iterative approach, we move from basic descriptive stats to more nuanced visual understanding of sales behavior — helping us identify patterns like high-frequency low-dollar transactions or weekly sales cycles. The section also illustrates how to apply .plot sub-methods for time series and categorical visualizations, reinforcing how visual exploration and data transformation go hand-in-hand in exploratory data analysis.
Knowledge check
13.4 Visualizing Relationships Between Variables (Bivariate Plots)
In the previous section, we focused on understanding the distribution of a single variable — sales_value — using univariate plots. But as we explored patterns like how sales varied by day of the week or department, we were already stepping into the world of bivariate analysis: looking at how one variable (sales) changes in relation to another (like day or department).
This section builds on that by introducing formal approaches to bivariate visualization — using Pandas’ .plot() method with DataFrames to uncover relationships between two variables. These visualizations help answer questions like:
- How do total sales compare across demographic groups?
- Are some product categories driving more revenue than others?
- How does purchasing behavior change over time?
Let’s look at some examples of bar plots, line plots, and scatter plots to explore bivariate comparisons and trends — reinforcing how visualizing relationships is key to discovering insights in your data.
Scatter Plots: Continuous Relationships
To visualize the relationship between two continuous variables, such as sales_value and quantity, we can use a scatter plot. This requires specifying the x and y arguments:
df.plot.scatter(x='quantity', y='sales_value', title='Sales versus quantity', figsize=(8,4))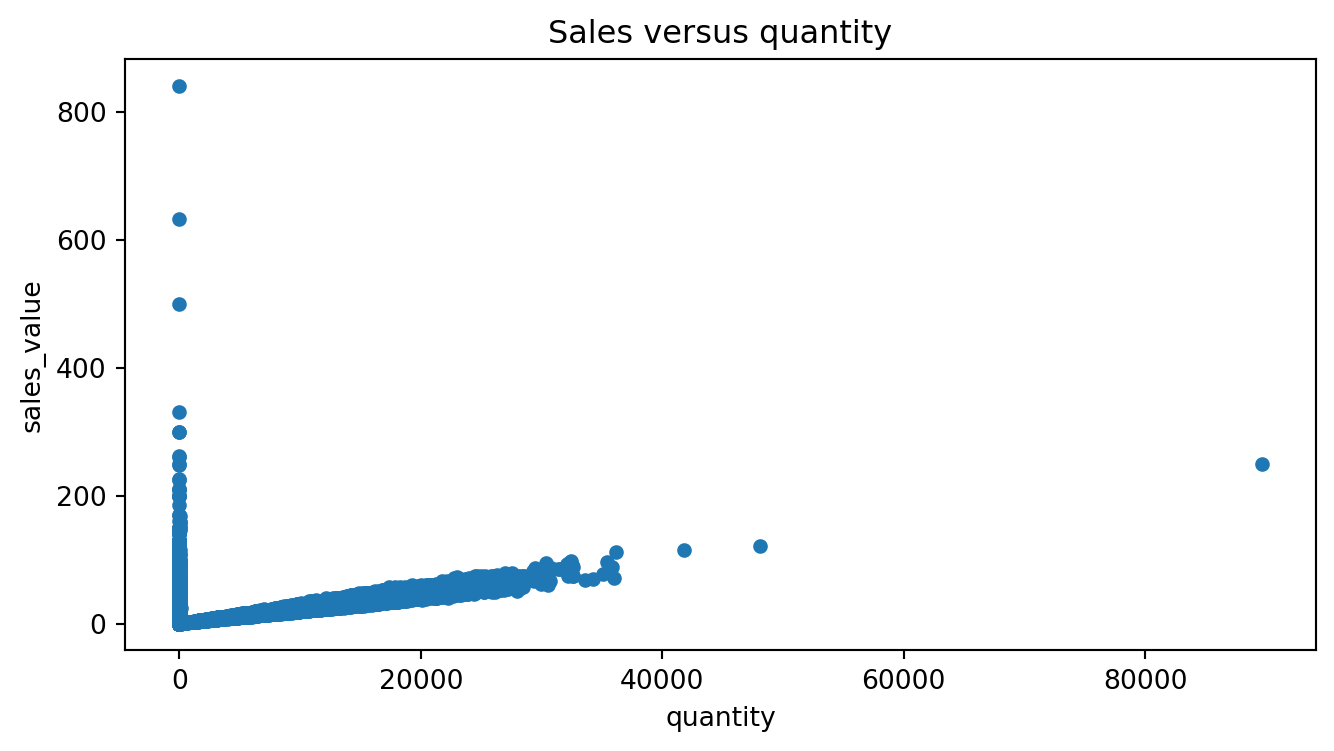
This plot helps us see whether higher quantities tend to drive higher sales values (they do — but with a lot of low-spend noise). Scatter plots are ideal for spotting correlations, clusters, and outliers.
Bar Charts: Group Comparisons
Although we previously used bar plots in a univariate context (e.g., frequency of departments), they’re just as valuable for bivariate visualizations — especially when summarizing a numeric variable across categories.
Let’s say we want to view the top 10 departments by total sales:
dept_sales = (
df
.groupby('department', as_index=False)
.agg({'sales_value': 'sum'})
.nlargest(10, 'sales_value')
.reset_index(drop=True)
)
dept_sales| department | sales_value | |
|---|---|---|
| 0 | GROCERY | 2316393.89 |
| 1 | DRUG GM | 596827.45 |
| 2 | FUEL | 329594.45 |
| 3 | PRODUCE | 322858.82 |
| 4 | MEAT | 308575.33 |
| 5 | MEAT-PCKGD | 232282.53 |
| 6 | DELI | 148344.06 |
| 7 | MISCELLANEOUS | 78858.67 |
| 8 | PASTRY | 69116.68 |
| 9 | NUTRITION | 57261.22 |
To visualize this, we plot department on the x-axis and sales_value on the y-axis:
(
dept_sales
.sort_values('sales_value')
.plot.barh(x='department', y='sales_value', color='red')
)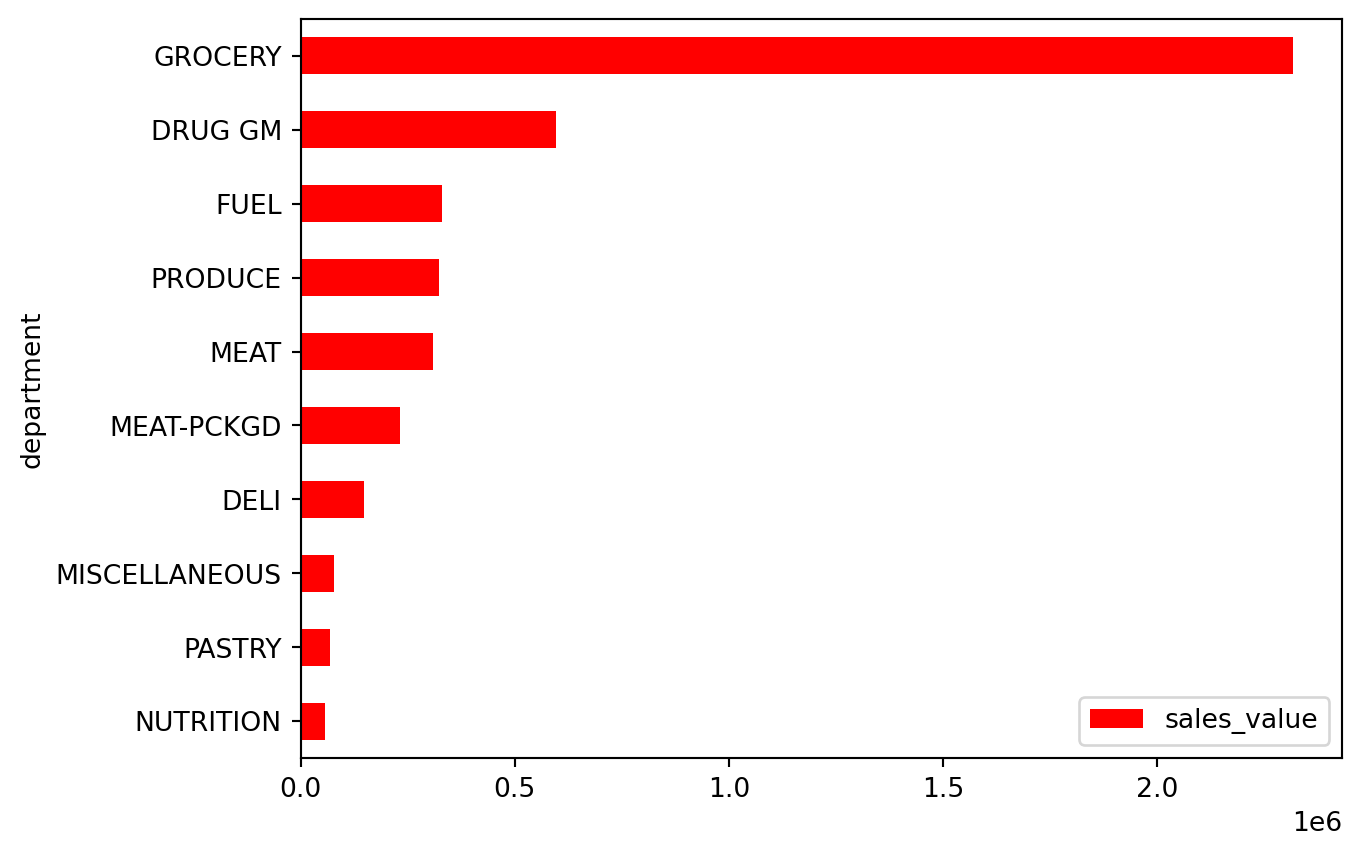
It’s common to sort values before bar plotting to produce a more readable left-to-right visual.
Multi-Series Plots
One benefit of plotting from a DataFrame is that we can visualize multiple numeric columns at once. Suppose we want to compare total sales_value and quantity per department:
dept_totals = (
df
.query("department != 'FUEL' & department != 'MISCELLANEOUS'")
.groupby('department', as_index=False)
.agg({'sales_value': 'sum', 'quantity': 'sum'})
.nlargest(10, 'sales_value')
.reset_index(drop=True)
)
dept_totals| department | sales_value | quantity | |
|---|---|---|---|
| 0 | GROCERY | 2316393.89 | 1242944 |
| 1 | DRUG GM | 596827.45 | 198635 |
| 2 | PRODUCE | 322858.82 | 185444 |
| 3 | MEAT | 308575.33 | 67526 |
| 4 | MEAT-PCKGD | 232282.53 | 83423 |
| 5 | DELI | 148344.06 | 37954 |
| 6 | PASTRY | 69116.68 | 28132 |
| 7 | NUTRITION | 57261.22 | 25024 |
| 8 | SEAFOOD-PCKGD | 35977.46 | 8028 |
| 9 | FLORAL | 22303.18 | 3160 |
We can pass both columns to the y argument to produce a grouped bar chart:
(
dept_totals
.sort_values('sales_value')
.plot.barh(x='department', y=['sales_value', 'quantity'])
.legend(loc='lower right')
)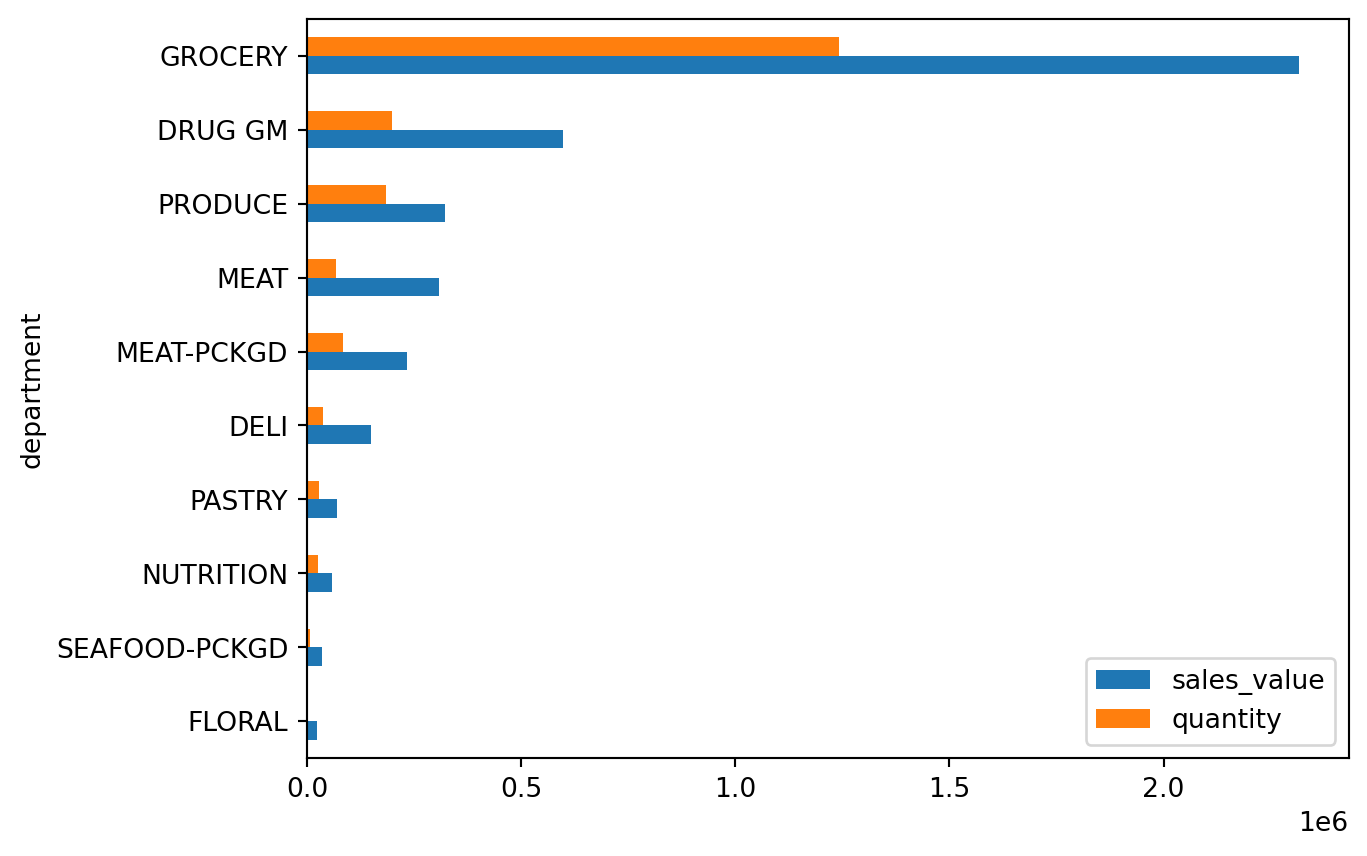
This is especially useful when comparing two related metrics across the same category.
Time Series with Multiple Columns
When your DataFrame includes a datetime index, the .plot() methods become even more powerful. For example, let’s look at daily total discounts for the GROCERY department across three types of discounts:
total_daily_discounts = (
df
.query("department == 'GROCERY'")
.set_index('transaction_timestamp')
.loc[:, ['retail_disc', 'coupon_disc', 'coupon_match_disc']]
.resample('D')
.sum()
)
total_daily_discounts.head()| retail_disc | coupon_disc | coupon_match_disc | |
|---|---|---|---|
| transaction_timestamp | |||
| 2017-01-01 | 925.84 | 15.75 | 1.90 |
| 2017-01-02 | 1158.67 | 13.14 | 4.55 |
| 2017-01-03 | 1153.42 | 13.75 | 5.84 |
| 2017-01-04 | 1266.71 | 6.10 | 2.10 |
| 2017-01-05 | 1359.38 | 30.74 | 5.64 |
Using .plot.line() will automatically generate a multi-line plot for all three columns:
total_daily_discounts.plot.line(logy=True, figsize=(10, 4));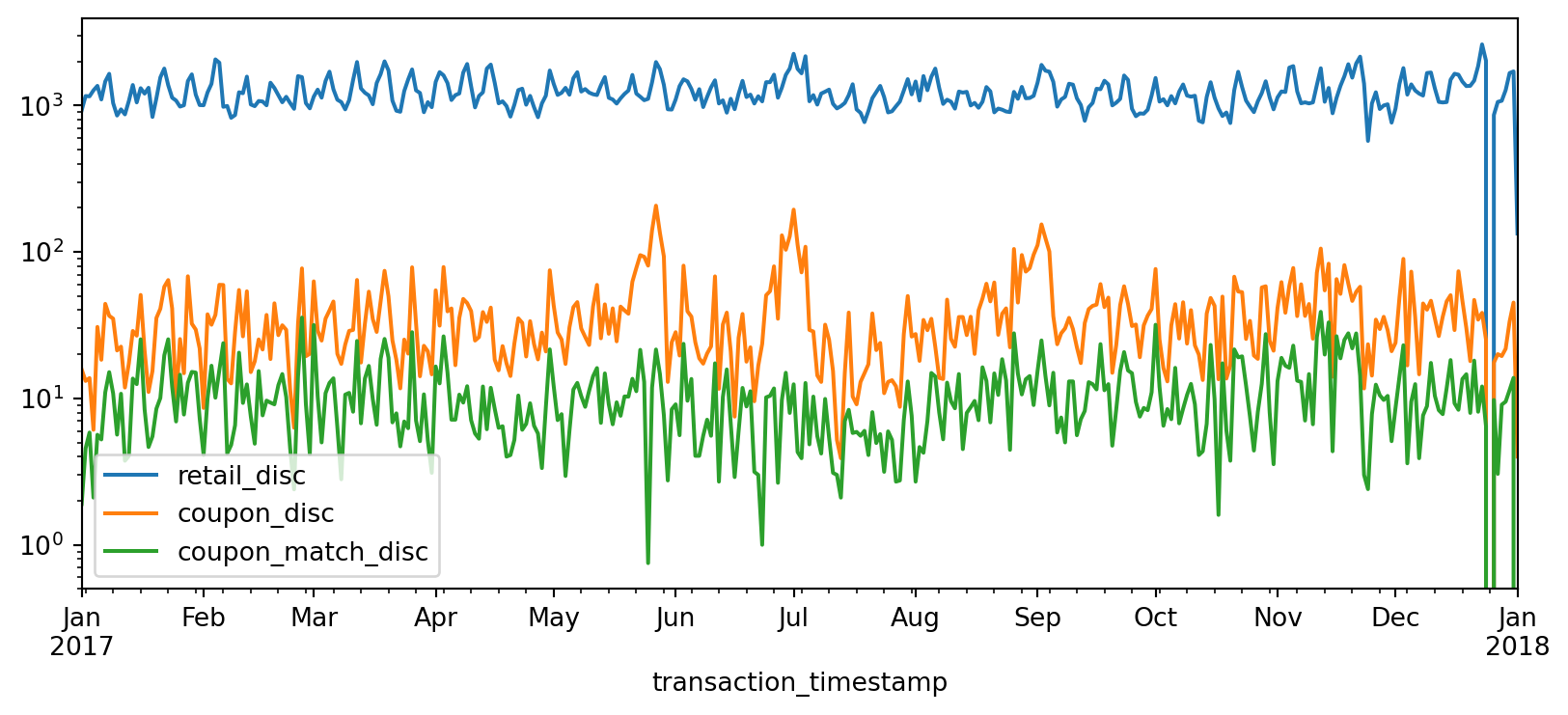
You can apply this same logic to other plot types like KDE, histogram, or box plots:
total_daily_discounts.plot.kde(logx=True);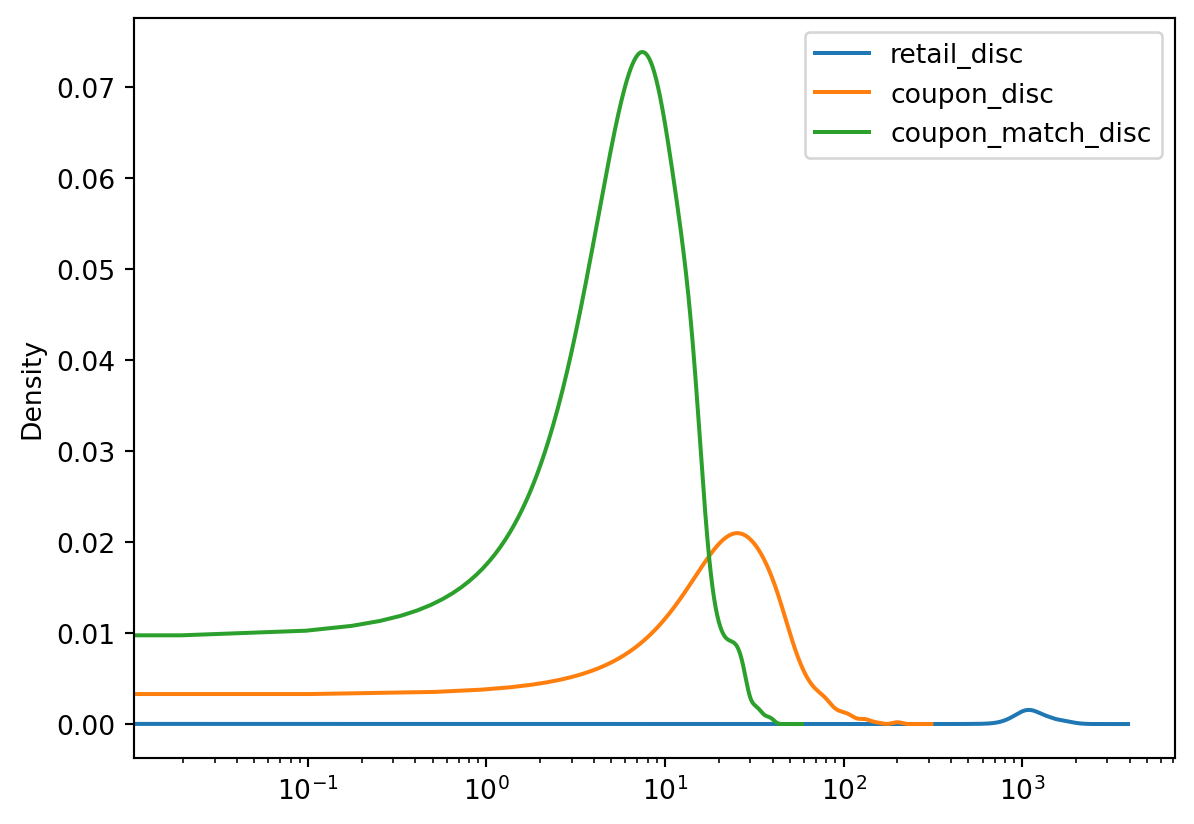
Note📚 Want to See More Pandas Plot Examples?
If you’re looking to go beyond the examples you’ve seen thus far, check out these high-quality resources:
Pandas Official Visualization Docs The most authoritative guide for all things
.plot(), with clear examples and customization options.Python Graph Gallery – Pandas Section A collection of simple, well-formatted Pandas plotting examples with explanations and visuals.
Knowledge check
13.5 Under the hood - Matplotlib
Underneath the hood Pandas is using Matplotlib to create the plots. Matplotlib is the most tried-and-true, mature plotting library in Python; however, its a bit more difficult to digest Matplotlib which is why I first introduce plotting with Pandas.
In the next lesson we will dig into Matplotlib because, with it being the most popular plotting library in the Python ecosystem, it is important for you to have a baseline understanding of its capabilities. But one thing I want to point out here is, since Pandas builds plots based on Matplotlib, we can actually use Matplotlib in conjunction with Pandas to advance our plots.
For example, Matplotlib provides many style options that can be used to beautify our plots. If you are familiar with fivethirtyeight.com you’ll know that most of their visualizations have a consistent theme. We can use Matplotlib to change the style of our plots to look like fivethirtyeight plots.
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
median_sales_by_weekday.plot.bar(title='Median total sales by weekday', figsize=(8,4))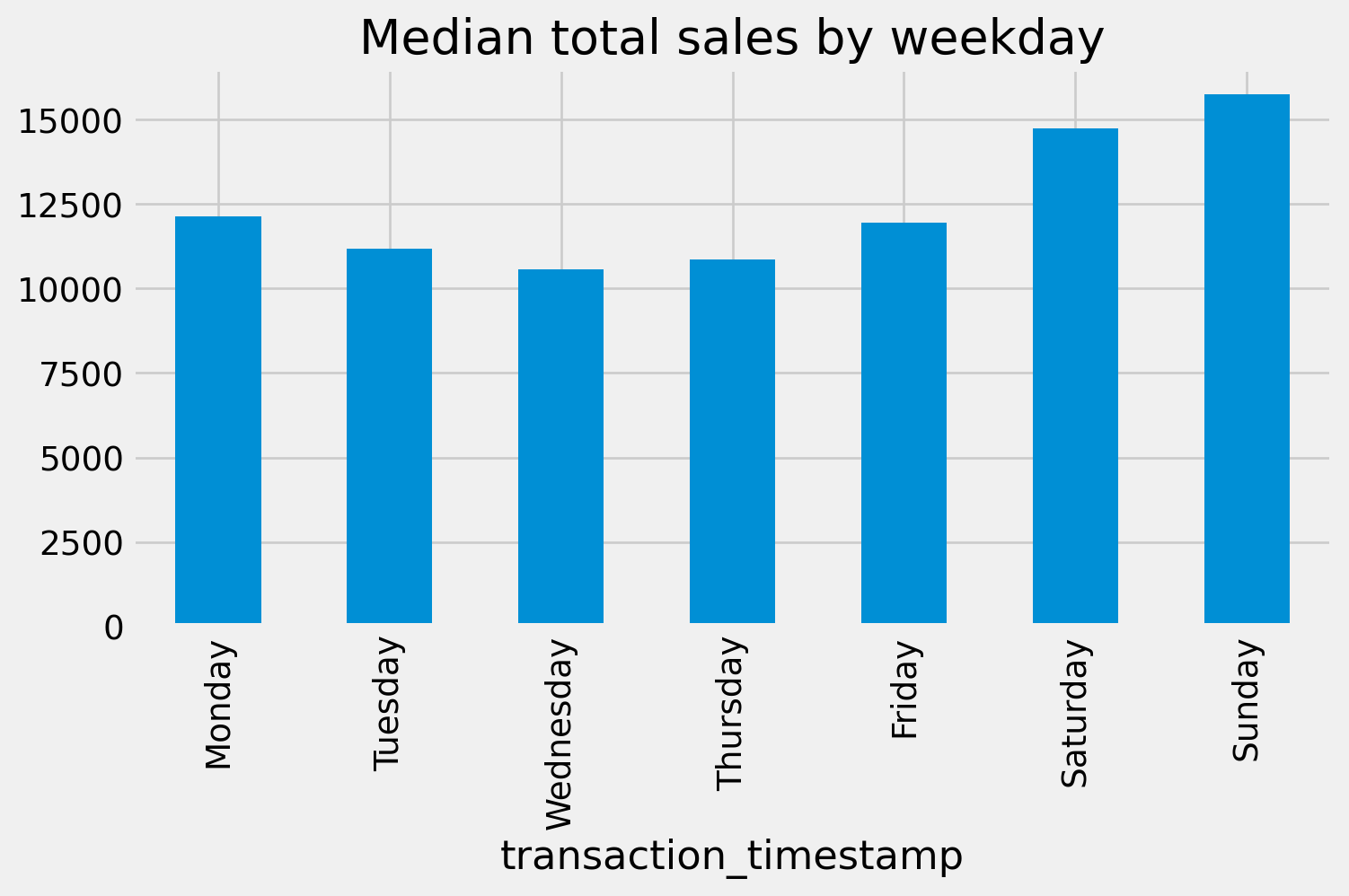
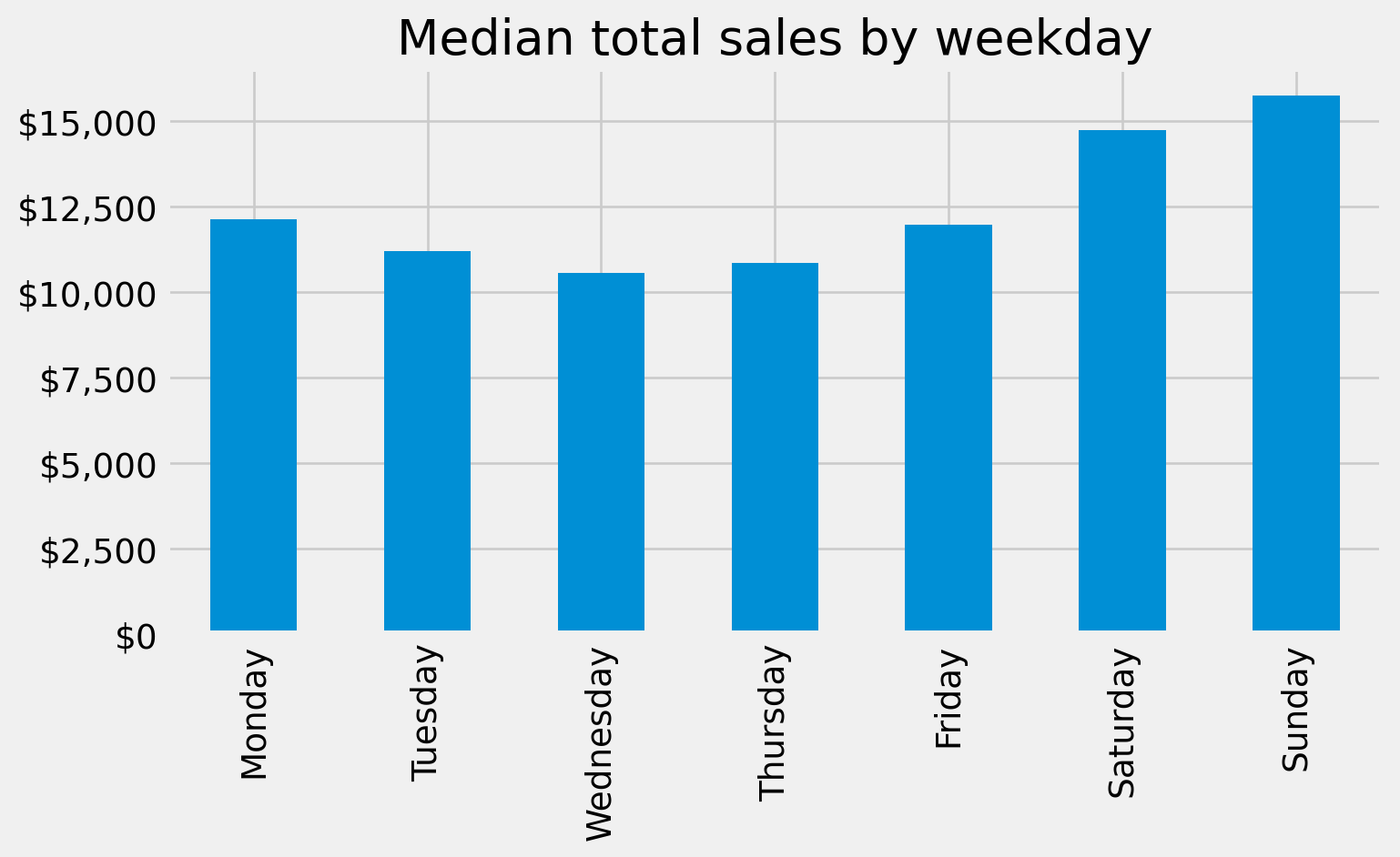
We may also want to refine our tick marks so that they are formatted in the units of interest. For example, below we use Matplotlib’s ticker module to format our y-axis to be in dollar and comma formatted units:
import matplotlib.ticker as mtick
tick_format = mtick.StrMethodFormatter('${x:,.0f}')
(
median_sales_by_weekday
.plot.bar(title='Median total sales by weekday', xlabel='', figsize=(8,4))
.yaxis.set_major_formatter(tick_format)
)
We’ll explore more Matplotlib capabilities in the next lesson but for now, happy Pandas plotting!
13.6 Summary
In this chapter, we explored how to use Pandas’ built-in .plot() functionality to quickly and effectively visualize data. Starting with univariate plots, we examined how to understand the distribution of a single variable — like sales_value — using histograms, boxplots, and KDE plots. We saw how filtering and transforming data before plotting helps surface key insights, such as frequent low-dollar transactions and outlier behavior.
We then moved into bivariate visualizations, where we analyzed how one variable changes in relation to another. We used scatter plots to assess continuous relationships, bar charts to compare grouped values (like total sales by department), and time series plots to understand trends over days, weeks, and months. Along the way, we learned how .plot() works with both Series and DataFrames, and how to create multi-series plots for deeper comparative insight.
While Pandas plots are perfect for fast exploratory analysis, they also serve as a gentle introduction to the broader Python visualization ecosystem.
What’s Next?
In the next chapter, we’ll dive deeper into the core engine behind Pandas plots — the Matplotlib library. You’ll learn how to build highly customized visualizations from scratch using Matplotlib’s object-oriented API. This will give you full control over plot styling, layout, and annotations — crucial for producing professional-grade charts.
Then, in the final chapter of this visualization module, we’ll explore Bokeh, a more advanced plotting library for building interactive, web-ready charts. These tools are especially powerful when communicating results to stakeholders, allowing you to go beyond static images to create interactive dashboards and storytelling experiences.
So far, you’ve built a strong foundation in fast, exploratory plotting with Pandas. Up next: mastering the tools that help you refine and present your story with clarity and impact.
13.7 Exercise: Visualizing Pizza Shopping Behavior
Use the datasets provided by the completejourney_py package to complete the following exercises. These tasks will help you practice filtering, grouping, and visualizing data using .plot() for both univariate and bivariate analysis.