“Every second of every day, our senses bring in way too much data than we can possibly process in our brains.” — Peter Diamandis, Founder of the X-Prize for human-AI collaboration
None✈️ Try This First
Open the planes.csv file in Excel, Google Sheets, or your preferred spreadsheet tool. Then try to answer this question:
Which aircraft were manufactured by Embraer in 2004 or later?
Use whatever approach you’re comfortable with: filtering, sorting, scrolling or even conditional formatting.
How long did it take you to find the matching rows?
Did you run into any frustration or confusion?
What would happen if the dataset had 1 million rows instead of a few hundred?
Could you repeat this process consistently if asked to do it again tomorrow?
This activity gives you a glimpse of a common task in data science: subsetting a dataset to focus on the most relevant information. Whether you’re analyzing flight records, home prices, or COVID case data, you’ll frequently need to extract specific rows and columns before you can analyze or visualize anything.
In this lesson, you’ll learn how to do this efficiently using Python and the pandas library — a skill that will save you time, reduce errors, and set the foundation for deeper analysis later.
Learning Objectives
By the end of this lesson, you’ll be able to:
Differentiate between the different ways to subset DataFrames.
Select columns of a DataFrame.
Slice and filter specific rows of a DataFrame.
9.1 Prerequisites
To illustrate selecting and filtering let’s go ahead and load the pandas library and import our planes data we’ve been using:
import pandas as pdplanes_df = pd.read_csv('../data/planes.csv')planes_df.head()
tailnum
year
type
manufacturer
model
engines
seats
speed
engine
0
N10156
2004.0
Fixed wing multi engine
EMBRAER
EMB-145XR
2
55
NaN
Turbo-fan
1
N102UW
1998.0
Fixed wing multi engine
AIRBUS INDUSTRIE
A320-214
2
182
NaN
Turbo-fan
2
N103US
1999.0
Fixed wing multi engine
AIRBUS INDUSTRIE
A320-214
2
182
NaN
Turbo-fan
3
N104UW
1999.0
Fixed wing multi engine
AIRBUS INDUSTRIE
A320-214
2
182
NaN
Turbo-fan
4
N10575
2002.0
Fixed wing multi engine
EMBRAER
EMB-145LR
2
55
NaN
Turbo-fan
Note📓 Follow Along in Colab!
As you read through this chapter, we encourage you to follow along using the companion notebook in Google Colab (or other editor of choice). This interactive notebook lets you run code examples covered in the chapter—and experiment with your own ideas.
We don’t always want all of the data in a DataFrame, so we need to take subsets of the DataFrame. In general, subsetting is extracting a small portion of a DataFrame – making the DataFrame smaller. Since the DataFrame is two-dimensional, there are two dimensions on which to subset.
Dimension 1: We may only want to consider certain variables. For example, we may only care about the year and engines variables:
We call this selecting columns/variables – this is similar to SQL’s SELECT or R’s dplyr package’s select().
Dimension 2: We may only want to consider certain cases. For example, we may only care about the cases where the manufacturer is Embraer.
We call this filtering or slicing – this is similar to SQL’s WHERE or R’s dplyr package’s filter() or slice(). And we can combine these two options to subset in both dimensions – the year and engines variables where the manufacturer is Embraer:
In the previous example, we want to do two things using planes_df:
select the year and engines variables
filter to cases where the manufacturer is Embraer
But we also want to return a new DataFrame – not just highlight certain cells. In other words, we want to turn this:
So we really have a third need: return the resulting DataFrame so we can continue our analysis:
select the year and engines variables
filter to cases where the manufacturer is Embraer
Return a DataFrame to continue the analysis
9.3 Subsetting variables
Recall that the subsetting of variables/columns is called selecting variables/columns. In a simple example, we can select a single variable using bracket subsetting notation:
Notice the head() method also works on planes_df['year'] to return the first five elements.
NonePop quiz!
What is the data type of planes_df['year']?
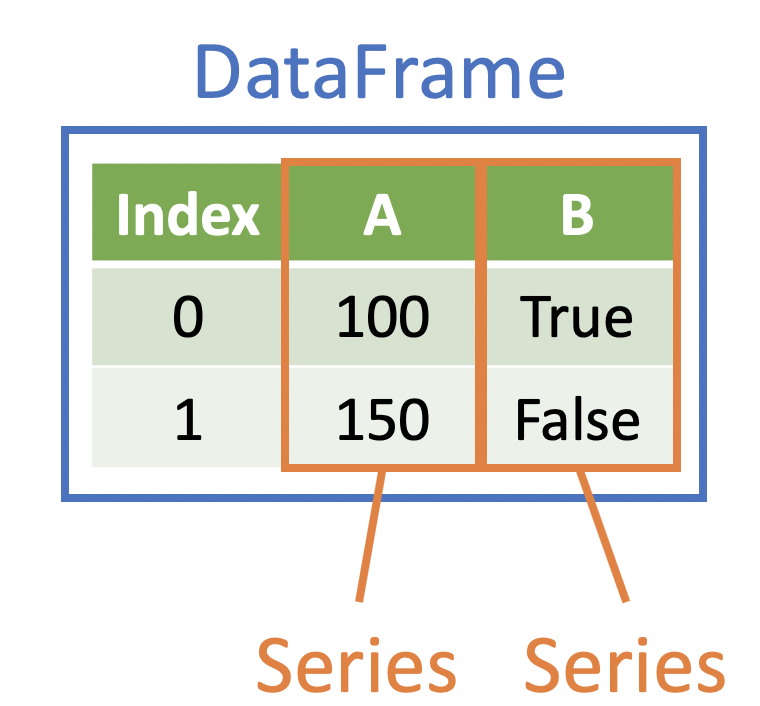
This returns pandas.core.series.Series, referred to simply as a “Series”, rather than a DataFrame.
type(planes_df['year'])
pandas.core.series.Series
This is okay – the Series is a popular data structure in Python. Recall from a previous lesson:
A Series is a one-dimensional data structure – this is similar to a Python list
Note that all objects in a Series are usually of the same type (but this isn’t a strict requirement)
Each DataFrame can be thought of as a list of equal-length Series (plus an Index)
Series can be useful, but for now, we are interested in returning a DataFrame rather than a series. We can select a single variable and return a DataFrame by still using bracket subsetting notation, but this time we will pass a list of variables names:
planes_df[['year']].head()
year
0
2004.0
1
1998.0
2
1999.0
3
1999.0
4
2002.0
And we can see that we’ve returned a DataFrame:
type(planes_df[['year']].head())
pandas.core.frame.DataFrame
NonePop quiz!
What do you think is another advantage of passing a list?
Passing a list into the bracket subsetting notation allows us to select multiple variables at once:
planes_df[['year', 'engines']].head()
year
engines
0
2004.0
2
1
1998.0
2
2
1999.0
2
3
1999.0
2
4
2002.0
2
In another example, assume we are interested in the model of plane, number of seats and engine type:
planes_df[['model', 'seats', 'engine']].head()
model
seats
engine
0
EMB-145XR
55
Turbo-fan
1
A320-214
182
Turbo-fan
2
A320-214
182
Turbo-fan
3
A320-214
182
Turbo-fan
4
EMB-145LR
55
Turbo-fan
Knowledge check
NoneTry This
______ is a common term for subsetting DataFrame variables.
What type of object is a DataFrame column?
What will be returned by the following code?
planes_df['type', 'model']
9.4 Subsetting rows
When we subset rows (aka cases, records, observations) we primarily use two names: slicing and filtering, but these are not the same:
slicing, similar to row indexing, subsets observations by the value of the Index
filtering subsets observations using a conditional test
Slicing rows
Remember that all DataFrames have an Index:
planes_df.head()
tailnum
year
type
manufacturer
model
engines
seats
speed
engine
0
N10156
2004.0
Fixed wing multi engine
EMBRAER
EMB-145XR
2
55
NaN
Turbo-fan
1
N102UW
1998.0
Fixed wing multi engine
AIRBUS INDUSTRIE
A320-214
2
182
NaN
Turbo-fan
2
N103US
1999.0
Fixed wing multi engine
AIRBUS INDUSTRIE
A320-214
2
182
NaN
Turbo-fan
3
N104UW
1999.0
Fixed wing multi engine
AIRBUS INDUSTRIE
A320-214
2
182
NaN
Turbo-fan
4
N10575
2002.0
Fixed wing multi engine
EMBRAER
EMB-145LR
2
55
NaN
Turbo-fan
We can slice cases/rows using the values in the Index and bracket subsetting notation. It’s common practice to use .loc to slice cases/rows:
planes_df.loc[0:5]
tailnum
year
type
manufacturer
model
engines
seats
speed
engine
0
N10156
2004.0
Fixed wing multi engine
EMBRAER
EMB-145XR
2
55
NaN
Turbo-fan
1
N102UW
1998.0
Fixed wing multi engine
AIRBUS INDUSTRIE
A320-214
2
182
NaN
Turbo-fan
2
N103US
1999.0
Fixed wing multi engine
AIRBUS INDUSTRIE
A320-214
2
182
NaN
Turbo-fan
3
N104UW
1999.0
Fixed wing multi engine
AIRBUS INDUSTRIE
A320-214
2
182
NaN
Turbo-fan
4
N10575
2002.0
Fixed wing multi engine
EMBRAER
EMB-145LR
2
55
NaN
Turbo-fan
5
N105UW
1999.0
Fixed wing multi engine
AIRBUS INDUSTRIE
A320-214
2
182
NaN
Turbo-fan
Note that since this is not “indexing”, the last element is inclusive.
We can also pass a list of Index values:
planes_df.loc[[0, 2, 4, 6, 8]]
tailnum
year
type
manufacturer
model
engines
seats
speed
engine
0
N10156
2004.0
Fixed wing multi engine
EMBRAER
EMB-145XR
2
55
NaN
Turbo-fan
2
N103US
1999.0
Fixed wing multi engine
AIRBUS INDUSTRIE
A320-214
2
182
NaN
Turbo-fan
4
N10575
2002.0
Fixed wing multi engine
EMBRAER
EMB-145LR
2
55
NaN
Turbo-fan
6
N107US
1999.0
Fixed wing multi engine
AIRBUS INDUSTRIE
A320-214
2
182
NaN
Turbo-fan
8
N109UW
1999.0
Fixed wing multi engine
AIRBUS INDUSTRIE
A320-214
2
182
NaN
Turbo-fan
Filtering rows
We can filter rows using a logical sequence equal in length to the number of rows in the DataFrame.
Continuing our example, assume we want to determine whether each case’s manufacturer is Embraer. We can use the manufacturer Series and a logical equivalency test to find the result for each row:
This option is more succinct and also reduces programming time. As before, as your filtering and selecting conditions get longer and/or more complex, it can make it easier to read to break it up into separate lines:
Subset planes_df to only include planes made by Boeing and only return the seats and model variables.
9.6 Views vs copies
One thing to be aware of, as you will likely experience it eventually, is the concept of returning a view (“looking” at a part of an existing object) versus a copy (making a new copy of the object in memory). This can be a bit abstract and even this section in the Pandas docs states “…it’s very hard to predict whether it will return a view or a copy.”
The main takeaway is that the most common warning you’ll encounter in Pandas is the SettingWithCopyWarning; Pandas raises it as a warning that you might not be doing what you think you’re doing or because the operation you are performing may behave unpredictably.
Let’s look at an example. Say the number of seats on this particular plane was recorded incorrectly. Instead of 55 seats it should actually be 60 seats.
Instead of using .iloc, we could actually filter and select this element in our DataFrame with the following bracket notation.
planes_df[tailnum_of_interest]['seats']
0 55
Name: seats, dtype: int64
planes_df[tailnum_of_interest]['seats'] =60
/tmp/ipykernel_3399/2190037627.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
So what’s going on? Did our DataFrame get changed?
planes_df[tailnum_of_interest]
tailnum
year
type
manufacturer
model
engines
seats
speed
engine
0
N10156
2004.0
Fixed wing multi engine
EMBRAER
EMB-145XR
2
55
NaN
Turbo-fan
No it didn’t, even though you probably thought it did. What happened above is that planes_df[tailnum_of_interest]['seats'] was executed first and returned a copy of the DataFrame, which is an entirely different object. We can confirm by using id():
print(f"The id of the original dataframe is: {id(planes_df)}")print(f" The id of the indexed dataframe is: {id(planes_df[tailnum_of_interest])}")
The id of the original dataframe is: 140571147252992
The id of the indexed dataframe is: 140571146221136
We then tried to set a value on this new object by appending ['seats'] = 60. Pandas is warning us that we are doing that operation on a copy of the original dataframe, which is probably not what we want. To fix this, you need to index in a single go, using .loc[] for example:
planes_df.loc[tailnum_of_interest, 'seats'] =60
No error this time! And let’s confirm the change:
planes_df[tailnum_of_interest]
tailnum
year
type
manufacturer
model
engines
seats
speed
engine
0
N10156
2004.0
Fixed wing multi engine
EMBRAER
EMB-145XR
2
60
NaN
Turbo-fan
The concept of views and copies is confusing and you can read more about it here.
But realize, this behavior is changing in pandas 3.0. A new system called Copy-on-Write will become the default, and it will prevent chained indexing from working at all — meaning instead of getting the SettingWithCopyWarning warning, pandas will simply raise an error.
Regardless, always use .loc[] for combined filtering and selecting!
9.7 Summary
In this chapter, you learned how to zoom in on the parts of a DataFrame that matter most. Whether you’re interested in just a few variables or a specific set of cases, being able to subset your data is a critical first step in any analysis.
We started by giving you a real-world task in Excel or Google Sheets — find aircraft built by Embraer in 2004 or later. That hands-on activity highlighted a common problem: manual filtering doesn’t scale. That’s where Python and pandas come in.
In this chapter, you learned how to use pandas for:
Selecting columns using single or multiple variable names
Slicing rows by index position
Filtering rows using conditional logic
Combining selection and filtering with .loc[] for efficient subsetting
🧾 Quick Reference: Subsetting Techniques
Task
Syntax Example
Output Type
Select one column
df["col"]
Series
Select multiple columns
df[["col1", "col2"]]
DataFrame
Slice rows by index
df.loc[0:4]
DataFrame
Filter rows by condition
df[df["year"] > 2000]
DataFrame
Combine filter + select
df.loc[df["year"] > 2000, ["col1", "col2"]]
DataFrame
Best practice for assignment
df.loc[cond, "col"] = value
Safe, avoids warnings
🔁 Revisit the Challenge
Now that you’ve learned how to subset data using pandas, go back to the original question:
Which aircraft were manufactured by Embraer in 2004 or later?
This time, solve it using Python instead of a spreadsheet. Use what you’ve learned in this chapter — filtering rows by conditions, and selecting only the columns you need — to create a clean, focused DataFrame.
When you’re done, try to answer:
How many rows matched the condition?
What columns did you choose to keep?
Could you reuse your code later for different conditions?
This is how data scientists work: writing reusable, scalable code to extract insights from large datasets.
9.8 Exercise: Subsetting COVID College Data
In this exercise, you’ll apply what you learned to subset the New York Times college COVID-19 dataset. The dataset tracks COVID cases reported by colleges across the U.S.
📂 Download the data from this GitHub link or load it directly from a local copy if provided.
NoneStep 1: Load the Data
import pandas as pddata_url ="https://raw.githubusercontent.com/nytimes/covid-19-data/refs/heads/master/colleges/colleges.csv"college_df = pd.read_csv(data_url)college_df.head()
date
state
county
city
ipeds_id
college
cases
cases_2021
notes
0
2021-05-26
Alabama
Madison
Huntsville
100654
Alabama A&M University
41
NaN
NaN
1
2021-05-26
Alabama
Montgomery
Montgomery
100724
Alabama State University
2
NaN
NaN
2
2021-05-26
Alabama
Limestone
Athens
100812
Athens State University
45
10.0
NaN
3
2021-05-26
Alabama
Lee
Auburn
100858
Auburn University
2742
567.0
NaN
4
2021-05-26
Alabama
Montgomery
Montgomery
100830
Auburn University at Montgomery
220
80.0
NaN
This dataset includes many columns, but for this exercise, we’re going to focus only on:
state
city
college
cases
NoneStep 2: Subsetting Practice
Select only the columns: state, city, college, and cases.
Filter the dataset to show only colleges in Ohio (state == "OH") that reported more than 100 cases.
How many Ohio colleges reported more than 100 cases? (Hint: Use .shape or len())
NoneStep 3: Dig Into a Specific School
Filter the dataset to find records where the college is “University of Cincinnati” (case sensitive).
How many cases were reported by the University of Cincinnati?
NoneMake It Dynamic
Try making your filtering logic more flexible by defining parameters at the top of your notebook:
my_state ="OH"threshold =100
Then write code that will:
Filter for all colleges in my_state with cases greater than threshold
Return only the college and cases columns
Test your code with a few different states and thresholds. Can you reuse it to answer different questions (i.e. How many colleges in California reported more than 500 Covid cases?)