In business, we rarely care about a single number in isolation. Instead, leaders ask questions like:
Does increasing marketing spend actually increase sales?
Are higher salaries associated with better employee retention?
Do customers in certain regions spend more per transaction than others?
NoteExperiential Learning
Think about a situation where you suspected two things were related. Maybe you noticed that days with more advertising seemed to bring higher sales, or that studying longer before exams often resulted in better grades.
Write down one example from your work, studies, or daily life where you think two variables are connected. By the end of this chapter, you’ll have the tools to test whether your intuition is correct.
Answering these questions requires analyzing relationships between variables. This chapter introduces two fundamental tools for that: correlation (a descriptive statistic) and linear regression (a predictive model).
By the end of this chapter, you will be able to:
Explain what correlation measures and interpret its values (positive, negative, weak, strong)
Visualize and estimate the strength of relationships between variables
Calculate and interpret simple correlation coefficients in Python
Build and interpret simple linear regression models with one predictor
Extend regression models to include multiple numeric and categorical predictors
Connect regression coefficients to meaningful business insights
Recognize the limitations of correlation and regression with respect to causality
Note📓 Follow Along in Colab!
As you read through this chapter, we encourage you to follow along using the companion notebook in Google Colab (or another editor of your choice). This interactive notebook lets you run all the code examples covered here—and experiment with your own ideas.
21.1 Correlation: Measuring the Strength of a Relationship
Correlation measures how strongly two variables move together in a straight-line (linear) relationship.
Let’s See This in Action
Imagine you are working for a regional grocery chain. The marketing director has been steadily increasing the advertising budget over the last couple years and wants to know if these additional dollars are truly paying off. Do higher ad spends actually translate into higher weekly sales? This is a common business scenario where correlation can help us quickly explore whether a relationship exists between two key variables.
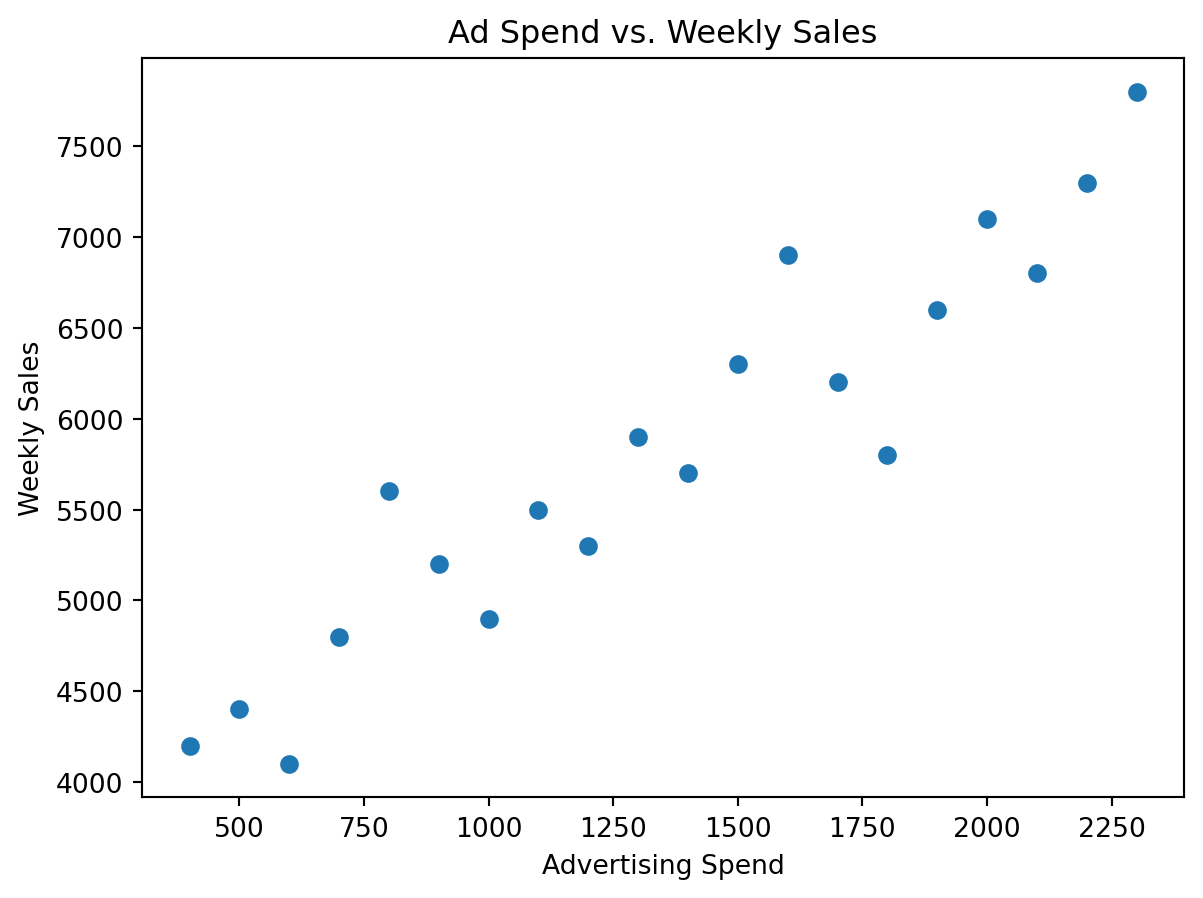
But before you even compute the correlation you would probably visualize the relationship as below.
import pandas as pdimport matplotlib.pyplot as plt# Example dataset: advertising spend vs. weekly salesdata = pd.DataFrame({"ad_spend": [400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2000, 2100, 2200, 2300],"weekly_sales": [4200, 4400, 4100, 4800, 5600, 5200, 4900, 5500, 5300, 5900, 5700, 6300, 6900, 6200, 5800, 6600, 7100, 6800, 7300, 7800]})# First look at the relationship visuallyplt.scatter(data["ad_spend"], data["weekly_sales"])plt.xlabel("Advertising Spend")plt.ylabel("Weekly Sales")plt.title("Ad Spend vs. Weekly Sales")plt.show()
It appears from the scatterplot that there is some relationship between advertising spend and weekly sales. However, the natural next question is: how do we measure this relationship? Is there a way to quantify it? This is where correlation comes in. Correlation provides a single number to summarize the strength and direction of the association.
# Now compute the correlation to quantify the relationshipdata.corr()
ad_spend
weekly_sales
ad_spend
1.000000
0.941372
weekly_sales
0.941372
1.000000
The correlation table shows us that advertising spend and weekly sales have a correlation of approximately 0.94, which indicates a strong positive linear relationship. This means that as advertising spending increases, weekly sales tend to increase as well. The diagonal values of 1.0 in the table above simply show that each variable is perfectly correlated with itself, which is always true.
What Does the Correlation Value Mean?
Correlation (often denoted \(\rho\) or \(r\) ) ranges from −1 to +1:
+1: perfect positive linear relationship
0: no linear relationship
−1: perfect negative linear relationship
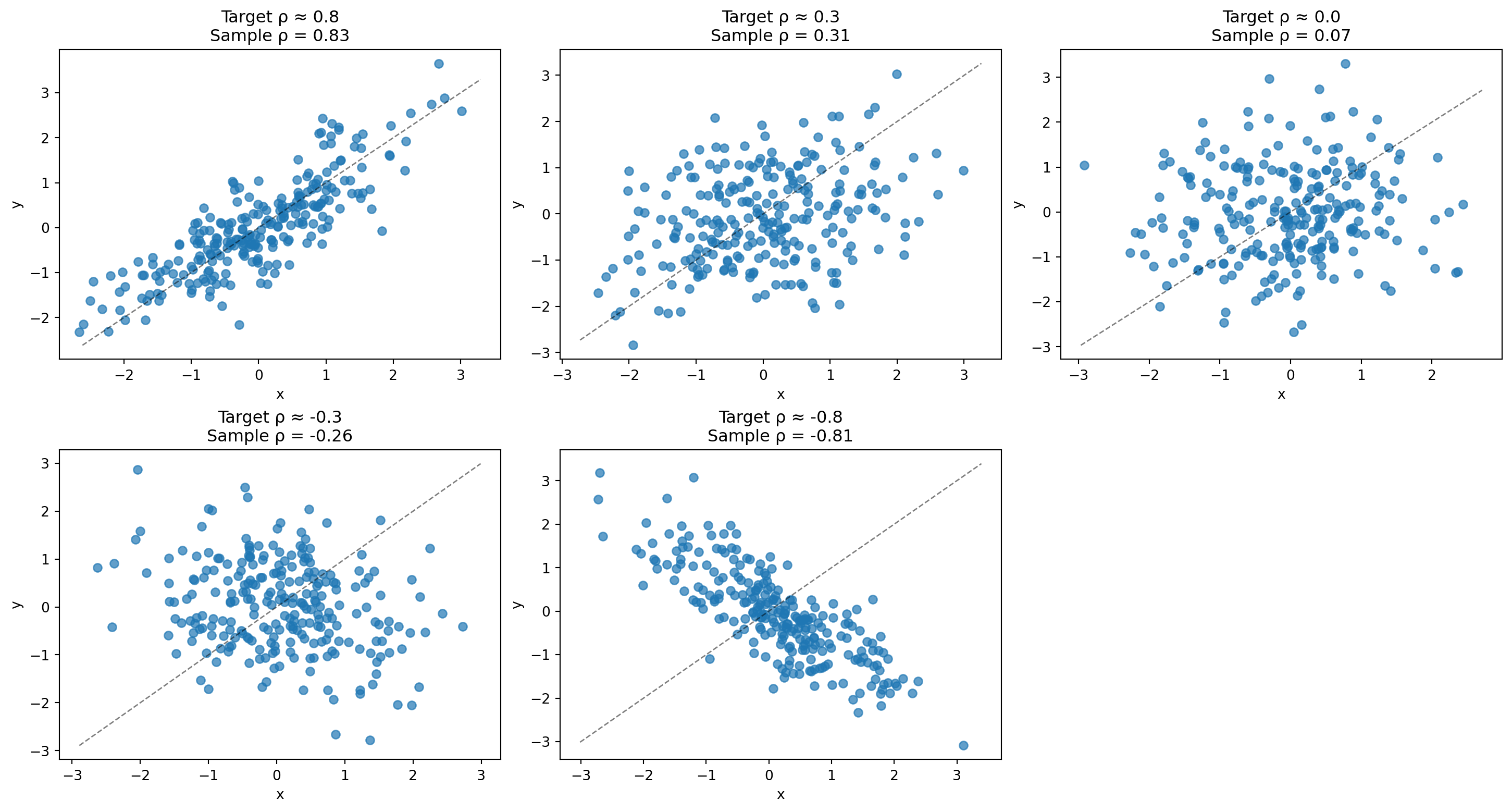
To build intuition, let’s simulate five datasets and visualize what different correlation strengths look like: strong positive (~0.8), weak positive (~0.3), no linear relationship (~0), weak negative (~−0.3), and strong negative (~−0.8). The dotted diagonal line in each plot shows what perfect positive correlation would look like.
Correlation is descriptive—it tells you variables move together, but notwhy. Treating correlation as causation can lead to costly mistakes. For example, ice cream sales and drowning deaths are positively correlated, but ice cream doesn’t cause drownings—both increase during hot summer weather. Similarly, finding that stores with more staff have higher sales doesn’t mean hiring more staff will automatically increase sales; successful stores might simply need more employees to handle existing demand. When making business decisions, always ask: could there be a third variable explaining both trends? Is the relationship truly causal, or just coincidental? Strong correlation is a starting point for investigation, not a conclusion for action.
Note🎥 Video Spotlight: Pearson’s Correlation – Clearly Explained!
In this video, StatQuest with Josh Starmer provides an excellent introduction to correlation—what it measures, how to interpret it, and why it’s such an important concept in data analysis. The video uses clear visuals and intuitive examples to show how two variables can move together in positive, negative, or no linear relationship.
As you watch, think about the following:
How does the correlation coefficient quantify the strength and direction of a relationship?
Why does correlation not necessarily imply causation?
How might correlation analysis help you make better data-driven business decisions?
Knowledge Check
NoneExplore the Advertising Data
The Advertising dataset is a classic dataset that represents a fictional company’s advertising expenditures and corresponding sales data. Variables in this data set include:
TV (continuous): Advertising budget spent on TV advertising (in thousands of dollars)
radio (continuous): Advertising budget spent on radio advertising (in thousands of dollars)
newspaper (continuous): Advertising budget spent on newspaper advertising (in thousands of dollars)
sales (continuous): Sales in thousands of units for the product in each market
Data Access: You can download the Advertising.csv dataset from the course GitHub repository here.
Create scatterplots between Sales and each channel.
Guess which predictor is strongest.
Compute correlations.
Which channels appear to have the strongest relationship to sales?
21.2 From Correlation to Regression
Correlation tells us two variables move together. Regression provides an equation to predict one variable from another. While correlation simply measures the strength of association, linear regression goes further by finding the “best-fitting line” through your data points and expressing this relationship as a mathematical equation. This equation allows you to make concrete predictions: given a specific value for your predictor variable (like advertising spend), you can estimate the expected value of your outcome variable (like weekly sales).
NoneVisualizing the Relationship Before Modeling
Go back to the data we created earlier and plot ad_spend vs weekly_sales again. Imagine drawing a straight line to represent the relationship. How steep would it be? Would all points fall close to it?
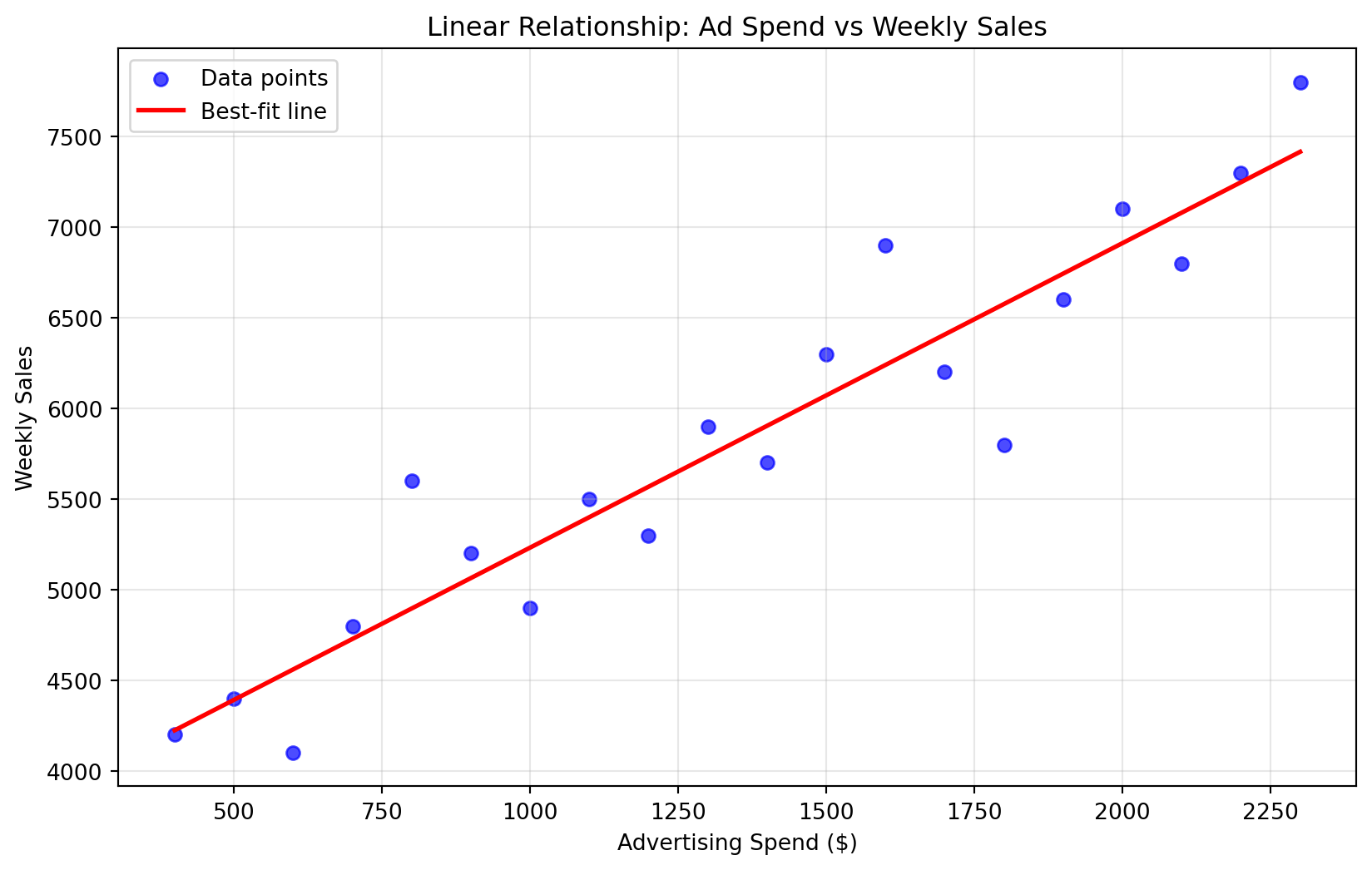
If you completed the visualization activity above, you probably imagined a line that looks something like this:
Show code for regression line visualization
# Create scatter plot with best-fit lineplt.figure(figsize=(10, 6))plt.scatter(data["ad_spend"], data["weekly_sales"], alpha=0.7, color='blue', label='Data points')# Calculate and plot the best-fit lineimport numpy as npfrom sklearn.linear_model import LinearRegression# Fit a simple linear regressionX_simple = data["ad_spend"].values.reshape(-1, 1)y_simple = data["weekly_sales"].valuesreg = LinearRegression().fit(X_simple, y_simple)# Create line points for plottingline_x = np.linspace(data["ad_spend"].min(), data["ad_spend"].max(), 100)line_y = reg.predict(line_x.reshape(-1, 1))plt.plot(line_x, line_y, color='red', linewidth=2, label='Best-fit line')plt.xlabel("Advertising Spend ($)")plt.ylabel("Weekly Sales")plt.title("Linear Relationship: Ad Spend vs Weekly Sales")plt.legend()plt.grid(True, alpha=0.3)plt.show()
This visualization captures the essence of linear regression: finding the “best-fit line” that best represents the directional relationship between two variables. While you can imagine many possible lines through these points, regression uses mathematical techniques to determine the single line that minimizes the overall distance between the line and all data points. This optimal line becomes our predictive model, allowing us to estimate weekly sales for any given advertising spend amount.
In this chapter, we’ll use scikit-learn’s LinearRegression for building our models. Scikit-learn focuses on prediction and provides clean, easy-to-interpret output that emphasizes the practical business insights we can gain from regression coefficients and predictions.
from sklearn.linear_model import LinearRegression# Prepare the dataX = data[["ad_spend"]] # Feature matrixy = data["weekly_sales"] # Target variable# Fit the modelmodel = LinearRegression()model.fit(X, y)
LinearRegression()
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
fit_intercept
True
copy_X
True
tol
1e-06
n_jobs
None
positive
False
We use the .fit() method to train our regression model, where X represents our features (predictors) - the variables we use to make predictions - and y represents our target variable - the outcome we’re trying to predict.
Once our model is fitted, there are several outputs we can extract to understand our regression results. For now, we’ll focus on the two most important ones: the intercept and the coefficient. The intercept tells us the predicted value of our target variable when all predictors equal zero, while the coefficient tells us how much our target variable changes for each one-unit increase in our predictor variable.
The regression model is simply an equation that represents the relationship between our variables. The general form of our equation is: \[ \text{Weekly Sales} = \text{Intercept} + \text{Slope} \times \text{Ad Spend} \]
As we fit our model, this equation gets updated to incorporate our specific intercept and coefficient values. Based on our model results above, our fitted equation becomes: \[ \text{Weekly Sales} = 3552 + 1.68 \times \text{Ad Spend} \]
Here’s how to interpret this model:
Intercept (3552): When ad spend is $0, we expect weekly sales of $3,552
Coefficient (1.68): For every $1 increase in ad spend, weekly sales increase by $1.68
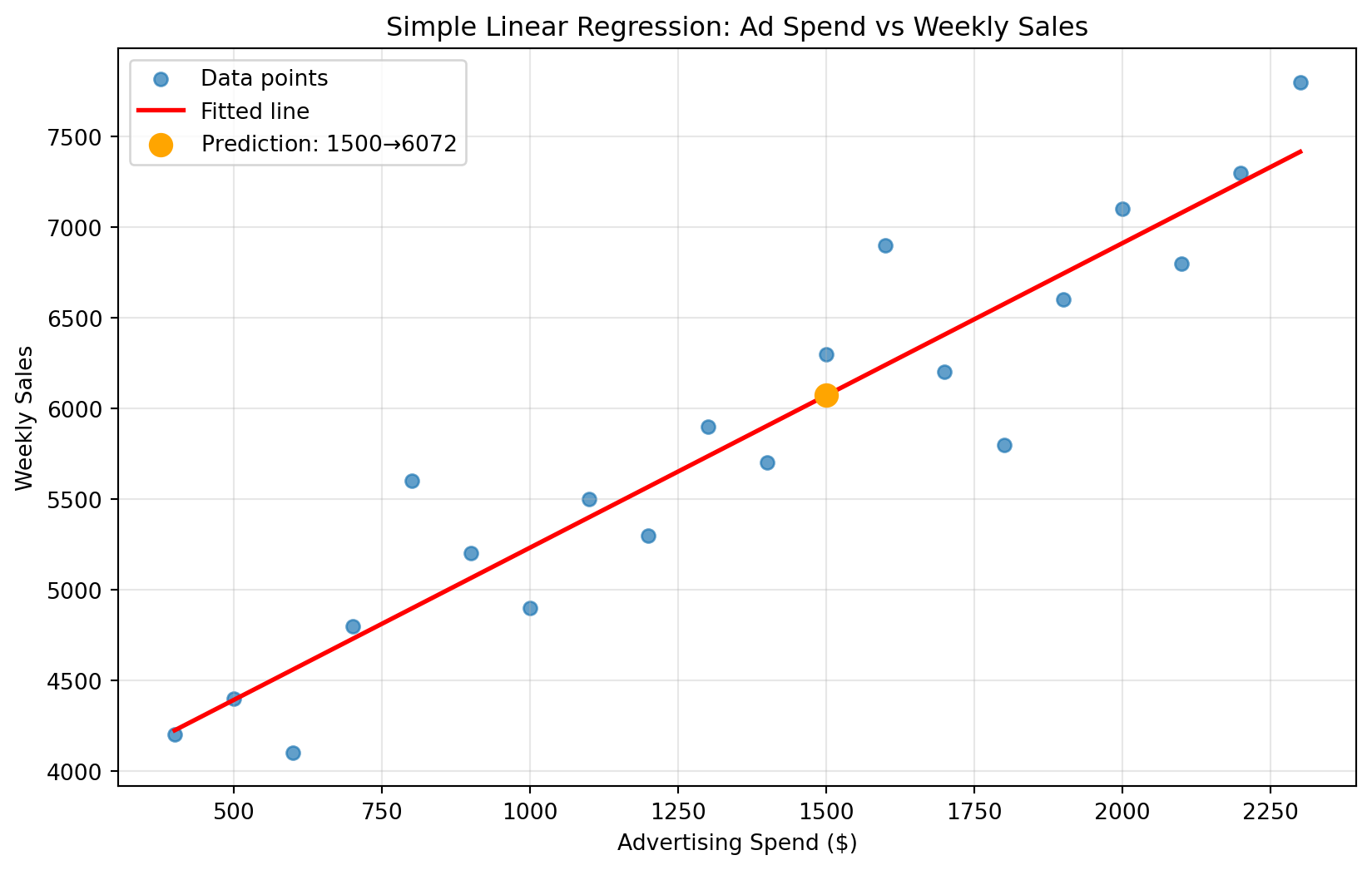
This means advertising appears to have a positive effect on sales, and we can quantify exactly how much impact each advertising dollar has. If we were to visualize this equation, it would look like the following plot. We can think of this red line as our model’s “best guess” about the relationship between advertising spend and sales—it represents the equation we just derived. For example, if we wanted to predict the expected weekly sales when advertising spend is $1,500.
Show code for regression line visualization
# Visualize the fitted regression lineplt.figure(figsize=(10, 6))plt.scatter(data["ad_spend"], data["weekly_sales"], alpha=0.7, label="Data points")plt.plot(data["ad_spend"], model.predict(X), color="red", linewidth=2, label="Fitted line")# Add prediction point for $1,500 ad spendprediction_x =1500prediction_df = pd.DataFrame({"ad_spend": [prediction_x]})prediction_y = model.predict(prediction_df)[0]plt.scatter(prediction_x, prediction_y, color="orange", s=100, zorder=5, label=f"Prediction: ${prediction_x} → ${prediction_y:.0f}")plt.xlabel("Advertising Spend ($)")plt.ylabel("Weekly Sales")plt.title("Simple Linear Regression: Ad Spend vs Weekly Sales")plt.legend()plt.grid(True, alpha=0.3)plt.show()
Note🎥 Video Spotlight: Simple Linear Regression Explained
This video introduces the goals of regression, connects the model to the basic linear equation ( \(y = \beta_0 + \beta_1x\) ), and shows how to interpret the slope and intercept using a clear, real-world example.
Making Predictions with Our Model
One of the most powerful aspects of regression is that we can use our fitted model to make predictions for new scenarios. While we could manually calculate predictions using our equation (as shown below), scikit-learn provides a convenient .predict() method that does this calculation for us automatically.
\[ \$6072 = 3552 + 1.68 \times \$1500 \]
Instead of manually calculating, we can use our fitted model’s .predict() method. This method takes new input data (in the same format as our training data) and applies our learned equation to generate predictions. This approach is especially useful when making predictions for multiple scenarios or when working with more complex models.
# Make a prediction for $1,500 in advertising spendnew_ad_spend = pd.DataFrame({"ad_spend": [1500]}) # $1500 in advertisingpredicted_sales = model.predict(new_ad_spend)print(f"Prediction: If we spend $1,500 on advertising, we expect {predicted_sales[0]:.0f} in weekly sales")
Prediction: If we spend $1,500 on advertising, we expect 6072 in weekly sales
Knowledge Check
NoneYour Turn!
Fit a simple regression using ISLP Advertising data to predict Sales from TV advertising spend.
Your Tasks:
Load the data and fit a LinearRegression model
Extract and interpret the intercept and coefficient
Make a prediction for $50k in TV advertising
How might a marketing manager use these insights?
21.4 Multiple Linear Regression
While simple linear regression uses a single predictor variable to make predictions, multiple linear regression extends this approach by incorporating multiple predictor variables simultaneously. This is much more realistic for business scenarios, where outcomes are rarely influenced by just one factor. Instead of asking “How does advertising spend affect sales?” we can ask more nuanced questions like “How do advertising spend AND number of stores AND seasonal factors together affect sales?”
The power of multiple regression lies in its ability to isolate the effect of each predictor while holding all other predictors constant. This allows us to answer questions like: “If we increase advertising spend by $100 while keeping the number of stores the same, how much will sales increase?” This type of insight is invaluable for business decision-making because it helps managers understand the independent contribution of each factor they control.
Expanding Our Scenario: Let’s return to our grocery chain example, but now imagine the marketing director realizes that sales aren’t just influenced by advertising spend—the number of stores in their network also plays a crucial role. As the company has expanded over the past few years, they’ve opened new locations, and the director suspects that having more stores amplifies the effect of their advertising efforts. They want to understand both factors simultaneously: how does advertising spend affect sales, and how does the number of stores affect sales, when we account for both factors together?
To model this scenario, we follow the same process as simple linear regression, but now we include multiple predictors in our feature matrix. All we’re really doing is expanding our simple equation to accommodate additional variables. Instead of predicting weekly sales using only advertising spend, we now predict it using both advertising spend AND number of stores:
This equation allows us to understand how each factor independently contributes to sales while accounting for the presence of the other factors.
# Prepare the data for multiple regressionX2 = data2[["ad_spend", "num_stores"]] # Multiple featuresy2 = data2["weekly_sales"]# Fit the multiple regression modelmodel2 = LinearRegression()model2.fit(X2, y2)
LinearRegression()
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
fit_intercept
True
copy_X
True
tol
1e-06
n_jobs
None
positive
False
Once our multiple regression model is fitted, we can examine the three key parameters of interest for our equation: the intercept and the two coefficients (one for each predictor variable). These parameters define our specific predictive equation and tell us how each factor influences weekly sales.
Intercept: 3843.58
Ad Spend Coefficient: 2.12
Num Stores Coefficient: -153.07
Based on our model results, our fitted multiple regression equation becomes: \[ \text{Weekly Sales} = 3843.58 + 2.12 \times \text{Ad Spend} + (-153.07) \times \text{Num Stores} \]
Here’s how to interpret each parameter:
Intercept (3843.58): When both ad spend and number of stores are 0, we expect weekly sales of $3,844
Ad Spend coefficient (2.12): For every $1 increase in ad spend, weekly sales increase by $2.12, holding number of stores constant
Num Stores coefficient (-153.07): For each additional store, weekly sales decrease by $153, holding ad spend constant
Interestingly, the negative coefficient for number of stores suggests that having more stores actually decreases weekly sales when advertising spend is held constant. This could indicate that sales are being spread across more locations, or that newer stores are still building their customer base.
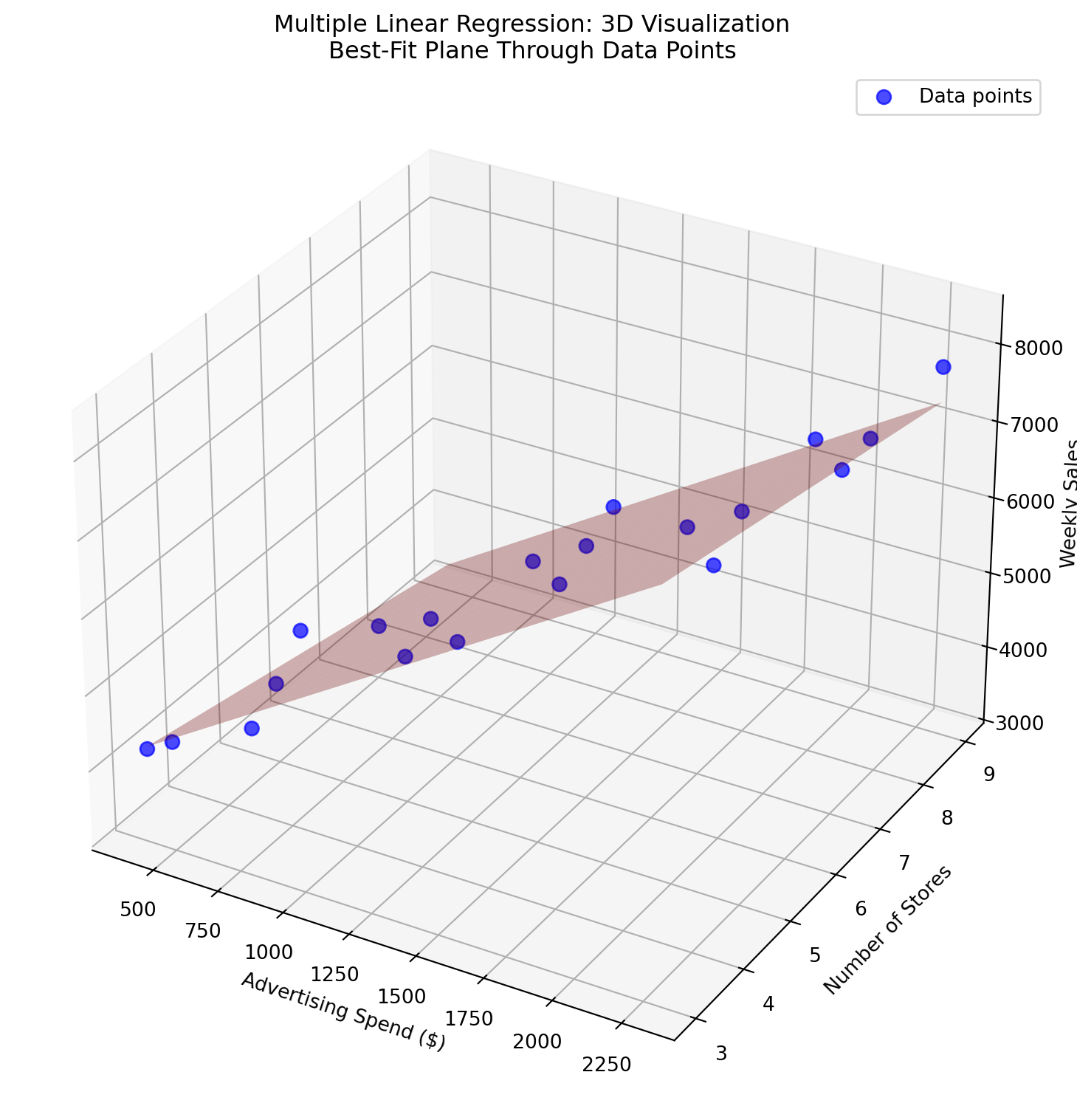
With two predictor variables, this equation now becomes a 3-dimensional problem where our “best-fit line” becomes a “best-fit plane.” Just as we could follow a line to make predictions with simple regression, we can still make predictions by following this plane in 3D space. However, as we add more predictors (creating 4, 5, or even hundreds of dimensions), visualization becomes impossible, though the mathematical principles remain the same.
Show code for 3D visualization of multiple regression plane
import matplotlib.pyplot as pltimport numpy as npimport warningsfrom mpl_toolkits.mplot3d import Axes3D# Suppress matplotlib 3D plotting warningswarnings.filterwarnings('ignore', category=RuntimeWarning, module='mpl_toolkits.mplot3d')# Create 3D plotfig = plt.figure(figsize=(12, 8))ax = fig.add_subplot(111, projection='3d')# Plot the actual data pointsax.scatter(data2["ad_spend"], data2["num_stores"], data2["weekly_sales"], color='blue', s=50, alpha=0.7, label='Data points')# Create meshgrid for the prediction planead_range = np.linspace(data2["ad_spend"].min(), data2["ad_spend"].max(), 20)stores_range = np.linspace(data2["num_stores"].min(), data2["num_stores"].max(), 20)ad_mesh, stores_mesh = np.meshgrid(ad_range, stores_range)# Calculate predictions for the planeplane_predictions = (model2.intercept_ + model2.coef_[0] * ad_mesh + model2.coef_[1] * stores_mesh)# Plot the prediction planeax.plot_surface(ad_mesh, stores_mesh, plane_predictions, alpha=0.3, color='red')# Set labels and titleax.set_xlabel('Advertising Spend ($)')ax.set_ylabel('Number of Stores')ax.set_zlabel('Weekly Sales')ax.set_title('Multiple Linear Regression: 3D Visualization\nBest-Fit Plane Through Data Points')ax.legend()plt.tight_layout()plt.show()
Making Predictions with Multiple Regression
Just as with simple linear regression, we can use our fitted multiple regression model to make predictions for new scenarios. The key advantage of multiple regression is that we can predict outcomes based on multiple input variables simultaneously, allowing us to explore different business scenarios and understand how changes in multiple factors affect our outcome of interest.
# Make predictions with multiple featuresprint("Multiple Regression Predictions:")print("Scenario 1: $1500 ad spend, 5 stores")scenario1 = pd.DataFrame({"ad_spend": [1500], "num_stores": [5]})pred1 = model2.predict(scenario1)print(f"Predicted sales: {pred1[0]:.0f}")print("\nScenario 2: $1500 ad spend, 7 stores") scenario2 = pd.DataFrame({"ad_spend": [1500], "num_stores": [7]})pred2 = model2.predict(scenario2)print(f"Predicted sales: {pred2[0]:.0f}")print(f"\nEffect of 2 additional stores: {pred2[0] - pred1[0]:.0f} change in weekly sales")
Multiple Regression Predictions:
Scenario 1: $1500 ad spend, 5 stores
Predicted sales: 6261
Scenario 2: $1500 ad spend, 7 stores
Predicted sales: 5955
Effect of 2 additional stores: -306 change in weekly sales
Knowledge Check
NoneYour Turn!
Use ISLP Advertising data to predict Sales using TV, Radio, and Newspaper advertising spend.
Your Tasks:
Fit a multiple regression model with all three advertising channels
Extract and interpret each coefficient
Write out the complete prediction equation
Which advertising channels have the strongest relationship with sales?
21.5 Categorical Predictors
So far, we’ve worked with continuous numeric predictors like advertising spend (measured in dollars) and number of stores (measured in counts). However, many important business factors are categorical rather than numeric—like customer type (Premium vs. Standard), sales region (North vs. South), product category (Electronics vs. Clothing), or marketing channel (Email vs. Social Media). These categorical variables can be just as important for predicting outcomes, but they require special handling because regression models fundamentally work with numbers, not categories.
The solution is dummy encoding (also called one-hot encoding), which converts categorical variables into numeric 0/1 indicators. While this might seem like a technical detail, it’s actually a powerful tool that allows us to quantify the impact of categorical factors on our outcomes. For instance, we can determine exactly how much more (or less) customers in the West region spend compared to those in the East, or how much premium customers differ from standard customers in their purchasing behavior.
Understanding Dummy Encoding
Suppose we have a variable region with two categories: East and West. Regression models require numeric inputs, so we need to transform this categorical variable into numbers.
Create a new variable region_West:
If a row is West → region_West = 1
If a row is East → region_West = 0
The East category becomes the baseline (reference group), and the coefficient for region_West tells us how much the West differs from East, holding other variables constant.
Here’s how dummy encoding changes the data:
ad_spend
region
weekly_sales
region_West
1000
East
5000
0
1200
West
5200
1
1500
East
6000
0
Example: Region and Sales
Let’s see this in action by creating a new simulated dataset that includes both advertising spend and regional information. For this example, we’ll generate 50 data points (25 for each region) where West region stores have consistently higher baseline sales than East region stores, but both regions respond to advertising in the same way.
Show code for simulating categorical predictor data
import numpy as np# Create 50 data points - 25 for each regionnp.random.seed(123) # For reproducible results# East region: lower baseline saleseast_ad_spend = np.linspace(500, 2000, 25)east_base_sales =3000+1.8* east_ad_spend # Same slope as Westeast_noise = np.random.normal(0, 200, 25)east_sales = east_base_sales + east_noise# West region: higher baseline sales (about $800 higher)west_ad_spend = np.linspace(500, 2000, 25)west_base_sales =3800+1.8* west_ad_spend # Same slope, higher baselinewest_noise = np.random.normal(0, 200, 25)west_sales = west_base_sales + west_noise# Combine into single DataFramedata3 = pd.DataFrame({"ad_spend": np.concatenate([east_ad_spend, west_ad_spend]),"region": ["East"] *25+ ["West"] *25,"weekly_sales": np.concatenate([east_sales, west_sales])})print("Simulated data with regional baseline differences:")print(f"East region samples: {len(data3[data3['region'] =='East'])}")print(f"West region samples: {len(data3[data3['region'] =='West'])}")data3.head()
Simulated data with regional baseline differences:
East region samples: 25
West region samples: 25
ad_spend
region
weekly_sales
0
500.0
East
3682.873879
1
562.5
East
4211.969089
2
625.0
East
4181.595700
3
687.5
East
3936.241057
4
750.0
East
4234.279950
In practice, we can use pandas’ pd.get_dummies() function to automatically perform this dummy encoding for us. This function takes categorical variables and creates new columns with 0/1 indicators for each category. The resulting dummy encoded variable (region_West) will appear as boolean values (True/False), but keep in mind that boolean values are mathematically equivalent to 1s and 0s, which is exactly what our regression model needs.
Now that we have our categorical variable properly encoded as numeric indicators, we can fit our regression model using the exact same process we’ve used before. The beauty of dummy encoding is that once the categorical variables are converted to numeric form, the regression algorithm treats them just like any other predictor variable.
y3 = data3["weekly_sales"]# Fit the model with categorical predictormodel3 = LinearRegression()model3.fit(X3_encoded, y3)# Extract key model componentsintercept = model3.intercept_ad_spend_coef = model3.coef_[0]region_west_coef = model3.coef_[1]print(f"Intercept: {intercept:.2f}")print(f"Ad Spend Coefficient: {ad_spend_coef:.2f}")print(f"Region West Coefficient: {region_west_coef:.2f}")
Intercept: 2781.30
Ad Spend Coefficient: 2.00
Region West Coefficient: 749.27
Based on our model results, region_West is coded as 1 if the store is in the West, 0 otherwise. The positive coefficient tells us that, holding advertising spend constant, West region stores average about 749 more in weekly sales compared to East region stores. This suggests that the West region may have more favorable market conditions or customer demographics that lead to higher baseline sales performance.
Interpreting in Equation Form
The regression equation with a categorical predictor takes the form:
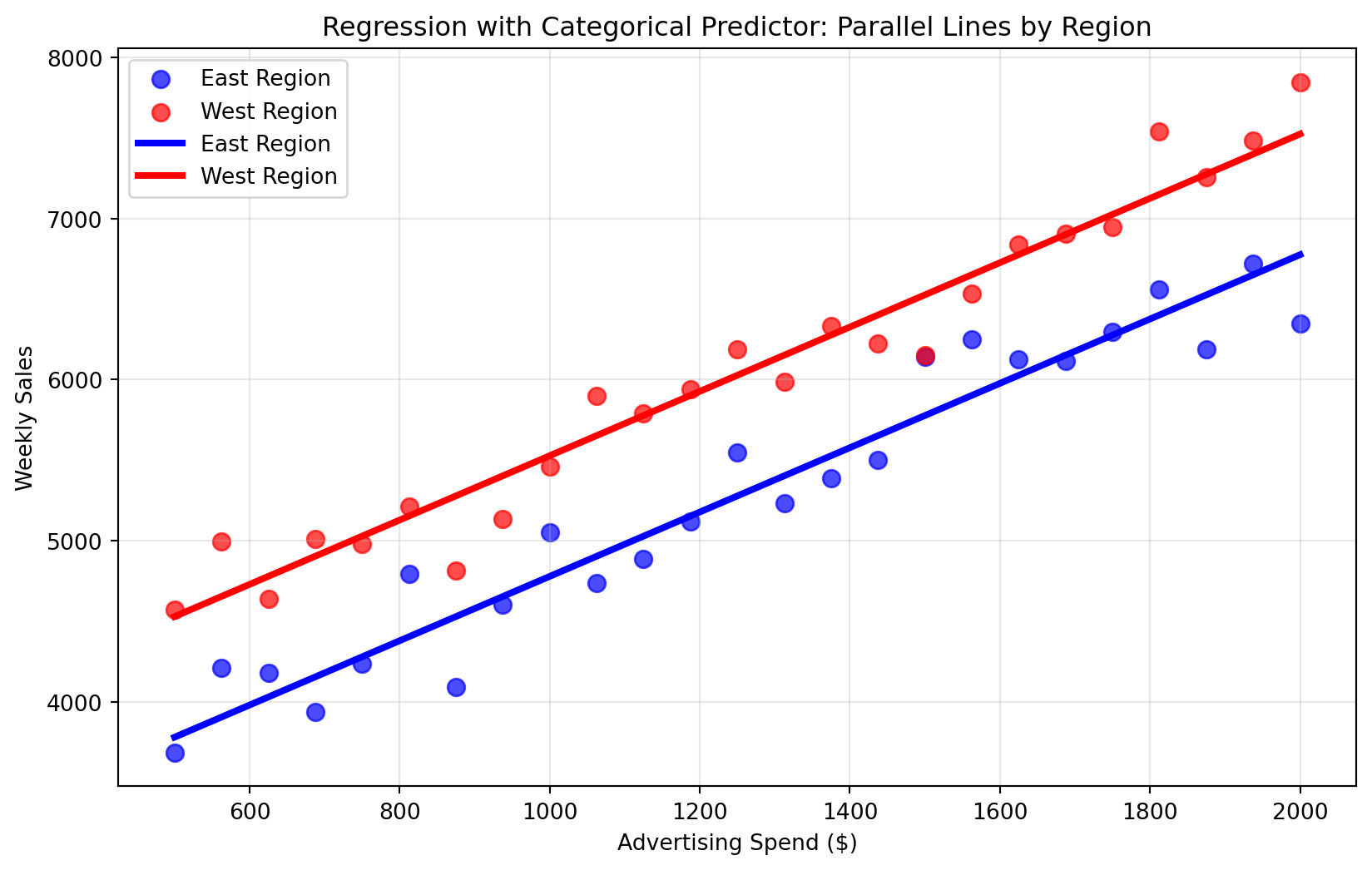
This creates parallel lines with the same slope but different intercepts—showing that advertising has the same effect in both regions, but the West region has consistently higher baseline sales.
We can visualize this model to see how the categorical predictor creates two parallel prediction lines—one for each region. The lines have the same slope (representing the consistent effect of advertising spend) but different intercepts (representing the regional baseline difference).
Show code for categorical predictor visualization
# Create visualization of categorical predictor modelplt.figure(figsize=(10, 6))# Separate data by region for plottingeast_data = data3[data3["region"] =="East"]west_data = data3[data3["region"] =="West"]# Plot data pointsplt.scatter(east_data["ad_spend"], east_data["weekly_sales"], color='blue', alpha=0.7, label='East Region', s=60)plt.scatter(west_data["ad_spend"], west_data["weekly_sales"], color='red', alpha=0.7, label='West Region', s=60)# Create parallel prediction linesad_range = np.linspace(data3["ad_spend"].min(), data3["ad_spend"].max(), 100)# East region line (region_West = 0)# Formula: intercept + ad_spend_coef * ad_spend + region_coef * 0east_predictions = model3.intercept_ + model3.coef_[0] * ad_rangeplt.plot(ad_range, east_predictions, color='blue', linewidth=3, linestyle='-', label=f'East Region')# West region line (region_West = 1)# Formula: intercept + ad_spend_coef * ad_spend + region_coef * 1west_predictions = model3.intercept_ + model3.coef_[0] * ad_range + model3.coef_[1] *1plt.plot(ad_range, west_predictions, color='red', linewidth=3, linestyle='-', label=f'West Region')plt.xlabel('Advertising Spend ($)')plt.ylabel('Weekly Sales')plt.title('Regression with Categorical Predictor: Parallel Lines by Region')plt.legend()plt.grid(True, alpha=0.3)plt.show()
As before, we can make predictions with our model on new data. Let’s see how our categorical predictor model works by predicting sales for stores in both regions with the same advertising spend.
# Demonstrate predictions for both regions using DataFrame formatprint("Categorical Predictor Predictions:")print("\nEast region store with $1500 ad spend:")east_scenario = pd.DataFrame({"ad_spend": [1500], "region_West": [0]})east_pred = model3.predict(east_scenario)print(f"Predicted sales: {east_pred[0]:.0f}")print("\nWest region store with $1500 ad spend:")west_scenario = pd.DataFrame({"ad_spend": [1500], "region_West": [1]})west_pred = model3.predict(west_scenario)print(f"Predicted sales: {west_pred[0]:.0f}")print(f"\nRegional difference: {west_pred[0] - east_pred[0]:.0f}")print("(This equals the Region_West coefficient)")
Categorical Predictor Predictions:
East region store with $1500 ad spend:
Predicted sales: 5777
West region store with $1500 ad spend:
Predicted sales: 6527
Regional difference: 749
(This equals the Region_West coefficient)
Knowledge Check
NoneYour Turn! Credit Data with Categorical Variables
Using the Credit dataset from ISLP, build a regression model that includes both numeric predictors and the categorical variable Gender.
from ISLP import load_dataCredit = load_data('Credit')Credit.head()
ID
Income
Limit
Rating
Cards
Age
Education
Gender
Student
Married
Ethnicity
Balance
0
1
14.891
3606
283
2
34
11
Male
No
Yes
Caucasian
333
1
2
106.025
6645
483
3
82
15
Female
Yes
Yes
Asian
903
2
3
104.593
7075
514
4
71
11
Male
No
No
Asian
580
3
4
148.924
9504
681
3
36
11
Female
No
No
Asian
964
4
5
55.882
4897
357
2
68
16
Male
No
Yes
Caucasian
331
Your Tasks:
Dummy encode the Gender variable (e.g., Female = 1, Male = 0).
Fit a regression model with Balance as the outcome and include Income, Limit, Age, and Gender as predictors.
Write the regression equation in full.
Interpret the Gender coefficient: how does being Male vs Female affect balance, holding all else constant?
Business reflection: How might a bank use this information?
Ethical reflection: Are there fairness or ethical concerns with using demographic variables like Gender in credit models?
21.6 Assumptions of Linear Regression
Linear regression is a powerful and widely used technique, but it relies on certain assumptions. Understanding these assumptions is important because when they are violated, your model’s predictions and interpretations may become unreliable. Here’s what each assumption means and why it matters in a business context:
Linearity: The relationship between predictors and the outcome is assumed to be linear. If the true relationship is curved or more complex, a linear model will oversimplify and potentially mislead decisions. Example: Assuming sales increase linearly with ad spend might overlook diminishing returns at higher spending levels.
Independence of errors: The residuals (errors) should not be correlated with each other. When errors are dependent, the model can give a false sense of confidence. Example: In time-series sales data, yesterday’s error often relates to today’s error—ignoring this can lead to poor forecasts.
Constant variance (homoscedasticity): The spread of residuals should be roughly the same across all levels of the predictor(s). If variance grows with the predictor, your model’s predictions will be more uncertain for certain groups. Example: Predicting customer spend may be reliable for average-income customers but wildly variable for high-income ones.
Normality of errors: Residuals should follow a roughly normal distribution. This assumption matters most for statistical inference (like confidence intervals and hypothesis tests). Example: If errors are highly skewed, a business might underestimate the risk of extreme losses.
While these assumptions provide a useful framework, real-world data often violates them. That doesn’t mean regression is useless—it simply means you need to interpret results cautiously and sometimes transform your data, add interaction terms, or explore alternative methods.
Importantly, later in this course you will learn about algorithms (such as decision trees, random forests, and boosting methods) that do not rely on these strict assumptions. These approaches can model nonlinear patterns, handle complex interactions, and provide more flexibility when linear regression falls short.
21.7 Summary
This chapter introduced you to two fundamental techniques that bridge exploratory data analysis and predictive modeling: correlation and linear regression. You’ve moved beyond describing individual variables to understanding how variables relate to and influence each other.
Correlation serves as a powerful descriptive tool for measuring the strength and direction of linear relationships. You learned that correlation coefficients range from -1 to +1, quickly revealing patterns in your data, while remembering that correlation describes association but never implies causation.
Linear regression extends correlation by providing a mathematical framework for prediction and interpretation. You mastered the progression from simple regression (one predictor) to multiple regression (several predictors) to categorical predictors (using dummy encoding). Key skills you developed include:
Fitting models with scikit-learn’s LinearRegression using .fit() and .predict() methods
Extracting and interpreting intercepts and coefficients in business terms
Converting categorical variables with pd.get_dummies() for use in regression models
Creating effective visualizations that communicate regression results
Making predictions for new scenarios and business planning
Throughout realistic business scenarios involving advertising effectiveness and regional sales differences, you learned to translate statistical outputs into actionable business insights and maintain healthy skepticism about causal claims.
Looking ahead: The regression foundations you’ve built here are essential for all machine learning techniques you’ll encounter. In the next chapter, you’ll learn how to measure how well your models are performing through various evaluation metrics—a critical skill for determining when your models are ready for real-world deployment. The concepts of feature-target relationships, model fitting, and prediction interpretation you’ve mastered will transfer directly to any modeling framework in your data science career.
21.8 End of Chapter Exercise
For these exercises, you’ll work with three different datasets from the ISLP package. Each scenario mirrors a real-world decision context where regression can guide insights.
NoneScenario 1: Credit Risk Analysis
Company: A regional bank Goal: Understand what drives customers’ credit card balances to inform risk management and marketing strategies Dataset: Credit dataset from ISLP package
from ISLP import load_dataCredit = load_data('Credit')Credit.head()
ID
Income
Limit
Rating
Cards
Age
Education
Gender
Student
Married
Ethnicity
Balance
0
1
14.891
3606
283
2
34
11
Male
No
Yes
Caucasian
333
1
2
106.025
6645
483
3
82
15
Female
Yes
Yes
Asian
903
2
3
104.593
7075
514
4
71
11
Male
No
No
Asian
580
3
4
148.924
9504
681
3
36
11
Female
No
No
Asian
964
4
5
55.882
4897
357
2
68
16
Male
No
Yes
Caucasian
331
Your Tasks:
Fit a regression model predicting Balance using Income, Limit, Age, and Gender.
Interpret the coefficients: What does each variable suggest about customer balances, holding the others constant?
Convert the model into equation form.
Ethical reflection: Should Gender be used in credit risk models? What fairness concerns arise if it is?
Based on your model, how might the bank adjust its marketing or risk strategies?
NoneScenario 2: Baseball Salary Analysis
Company: A professional baseball team Goal: Better understand the drivers of player salaries to inform contract negotiations and player evaluation Dataset: Hitters dataset from ISLP package
Hitters = load_data('Hitters')Hitters.head()
AtBat
Hits
HmRun
Runs
RBI
Walks
Years
CAtBat
CHits
CHmRun
CRuns
CRBI
CWalks
League
Division
PutOuts
Assists
Errors
Salary
NewLeague
0
293
66
1
30
29
14
1
293
66
1
30
29
14
A
E
446
33
20
NaN
A
1
315
81
7
24
38
39
14
3449
835
69
321
414
375
N
W
632
43
10
475.0
N
2
479
130
18
66
72
76
3
1624
457
63
224
266
263
A
W
880
82
14
480.0
A
3
496
141
20
65
78
37
11
5628
1575
225
828
838
354
N
E
200
11
3
500.0
N
4
321
87
10
39
42
30
2
396
101
12
48
46
33
N
E
805
40
4
91.5
N
Data Cleaning Hint: The Hitters dataset contains some missing values in the Salary column. You may need to remove rows with missing salary data before fitting your regression model. Consider using dropna() or similar methods to clean the data first.
Your Tasks:
Fit a regression model predicting Salary using Years (experience), Hits (recent batting performance), and League (categorical: American or National).
Interpret the coefficients: How do performance and experience impact salaries? What does the league dummy variable suggest?
Convert the regression results into equation form.
Business reflection: If you were a player agent, how could you use this model to advocate for higher salaries for your clients?
NoneScenario 3: College Application Drivers
Company: Higher education consulting firm Goal: Analyze what factors drive the number of applications a college receives to advise institutions on strategic positioning Dataset: College dataset from ISLP package
College = load_data('College')College.head()
Private
Apps
Accept
Enroll
Top10perc
Top25perc
F.Undergrad
P.Undergrad
Outstate
Room.Board
Books
Personal
PhD
Terminal
S.F.Ratio
perc.alumni
Expend
Grad.Rate
0
Yes
1660
1232
721
23
52
2885
537
7440
3300
450
2200
70
78
18.1
12
7041
60
1
Yes
2186
1924
512
16
29
2683
1227
12280
6450
750
1500
29
30
12.2
16
10527
56
2
Yes
1428
1097
336
22
50
1036
99
11250
3750
400
1165
53
66
12.9
30
8735
54
3
Yes
417
349
137
60
89
510
63
12960
5450
450
875
92
97
7.7
37
19016
59
4
Yes
193
146
55
16
44
249
869
7560
4120
800
1500
76
72
11.9
2
10922
15
Your Tasks:
Fit a regression model predicting Apps (applications received) using Top10perc (percent of students from top 10% of high school class), Outstate (out-of-state tuition), and Private (categorical: private vs. public).
Interpret the coefficients: How do academics, price, and private/public status influence applications?
Convert the model into equation form.
Reflection: If you were advising a college president, what strategies might you recommend based on this model? Are there any risks of oversimplifying the decision with this model?