import numpy as np
import pandas as pd
from completejourney_py import get_data
df = get_data()['transactions']18 Writing Your Own Functions
In data science and data mining, writing your own functions is critical. As your analyses grow in complexity, so do your code bases. Functions allow you to:
- Simplify repetitive tasks
- Increase the clarity of your logic
- Minimize bugs and errors
- Make your code easier to test and maintain
This chapter will show you how to write your own functions—from the basics of syntax to more advanced ideas like type hints and anonymous functions. Whether you’re preparing data, building machine learning models, or conducting statistical analyses, writing custom functions will make you a more effective data scientist.
By the end of this lesson you will be able to:
- Explain when to write functions
- Discuss the difference between functions and methods
- Define your own functions that includes:
- Default arguments
- Type hints
- Exception handling
- Docstrings
- Discuss how Python scopes for variables to use in functions
- Apply
lambda(anonymous) functions
Note📓 Follow Along in Colab!
As you read through this chapter, we encourage you to follow along using the companion notebook in Google Colab (or other editor of choice). This interactive notebook lets you run code examples covered in the chapter—and experiment with your own ideas.
👉 Open the Writing Functions Notebook in Colab.
18.1 Prerequisites
18.2 When to write functions
You should consider writing a function whenever you’ve copied and pasted a block of code more than twice (i.e. you now have three copies of the same code). For example, take a look at this code. What does it do?
# array containing 4 sets of 10 random numbers
x = np.random.random_sample((4, 10))
x[0] = (x[0] - x[0].min()) / (x[0].max() - x[0].min())
x[1] = (x[1] - x[1].min()) / (x[1].max() - x[1].min())
x[2] = (x[2] - x[2].min()) / (x[1].max() - x[2].min())
x[3] = (x[3] - x[3].min()) / (x[3].max() - x[3].min())You might be able to puzzle out that this rescales each array to have a range from 0 to 1. But did you spot the mistake? I made an error when copying-and-pasting the code for the third array: I forgot to change an x[1] to an x[2]. Writing a function reduces the chance of this error and makes it more explicit regarding our intentions since we can name our action (rescale) that we want to perform:
x = np.random.random_sample((4, 10))
def rescale(array):
for index, vector in enumerate(array):
array[index] = (vector - vector.min()) / (vector.max() - vector.min())
return(array)
rescale(x)array([[0.1053176 , 0.78024728, 0.79438553, 0. , 0.45409699,
0.73020635, 0.51628004, 0.00921086, 1. , 0.10712669],
[0.18238515, 0.85701789, 0.13731599, 0.64246881, 0.85546177,
1. , 0. , 0.31942023, 0.1947654 , 0.73970015],
[0. , 0.0098188 , 0.47851887, 0.43565211, 1. ,
0.30810188, 0.26162198, 0.35899796, 0.56693932, 0.49383145],
[0.03537048, 0.57247047, 0.10650619, 0.79828125, 0.64625604,
0.45326109, 0.89472605, 0.00665015, 1. , 0. ]])18.3 Functions vs methods
Functions and methods are very similar, and beginners to object oriented programming languages such as Python often refer to them synonymously. Although they are very similar, it is always good to distinguish between the two as it will help you explain code situations more explicitly.
A method refers to a function which is part of a class. You access it with an instance or object of the class. A function doesn’t have this restriction: it just refers to a standalone function. This means that all methods are functions, but not all functions are methods.
# stand alone function
sum(x)array([0.32307323, 2.21955444, 1.51672658, 1.87640218, 2.9558148 ,
2.49156932, 1.67262806, 0.6942792 , 2.76170472, 1.34065829])# method
x.sum(axis = 0)array([0.32307323, 2.21955444, 1.51672658, 1.87640218, 2.9558148 ,
2.49156932, 1.67262806, 0.6942792 , 2.76170472, 1.34065829])As illustrated above, there can be functions and methods that behave in a similar manner. However, often, methods have special parameters that allow them to behave uniquely to the object they are attached to. For example, the sum() method for the Numpy array allows you to get the overall sum, sum of each column, and sum of each row. This would take more effort to compute with the stand alone function.
# overall sum
x.sum()np.float64(17.852410823350727)# sum of each column
x.sum(axis = 0)array([0.32307323, 2.21955444, 1.51672658, 1.87640218, 2.9558148 ,
2.49156932, 1.67262806, 0.6942792 , 2.76170472, 1.34065829])# sum of each row
x.sum(axis = 1)array([4.49687134, 4.9285354 , 3.91348237, 4.51352171])Nonetheless, being able to create stand alone functions is a critical task. And, if you delve into building your own object classes down the road, defining methods is a piece of cake if you know how to define stand alone functions.
18.4 Defining functions
There are four main steps to defining a function:
- Use the keyword
defto declare the function and follow this up with the function name. - Add parameters to the function: they should be within the parentheses of the function. End your line with a colon.
- Add statements that the functions should execute.
- End your function with a return statement if the function should output something. Without the return statement, your function will return an object
None.
def yell(text):
new_text = text.upper()
return new_text
yell('hello world!')'HELLO WORLD!'Of course, your functions will get more complex as you go along: you can add for loops, flow control, and more to it to make it more finegrained. Let’s build a function that finds the total sales for a store, for a given day. The parameters required for the function are the data frame being analyzed, the store_id, and the specific week for which we need the sales.
def store_sales(data, store, week):
filt = (data['store_id'] == store) & (data['week'] == week)
total_sales = data['sales_value'][filt].sum()
return total_sales
store_sales(data=df, store=309, week=48)np.float64(395.6)Knowledge check
18.5 Parameters vs arguments
People often refer to function parameters and arguments synonymously but, technically, they represent two different things. Parameters are the names used when defining a function or a method, and into which arguments will be mapped. In other words, arguments are the things which are supplied to any function or method call, while the function or method code refers to the arguments by their parameter names.
Being specific about the term ‘parameters’ versus ‘arguments’ can be helpful when discussing specific details regarding a function or inputs, especially during debugging.
Python accepts a variety of parameter-argument calls. The following discusses some of the more common implementations you’ll see.
Keyword arguments
Keyword arguments are simply named arguments in the function call. Consider our store_sales() function, we can specify parameter arguments in two different ways. The first is positional, in which we supply our arguments in the same position as the parameter. However, this is less explicit and if we happen to switch our store and week argument placement then we may get different results then anticipated.
# implicitly computing store sales for store 46 during week 43
store_sales(df, 46, 43)np.float64(60.39)# implicitly computing store sales for store 43 (does not exist) during week 46
store_sales(df, 43, 46)np.float64(0.0)Using keyword, rather than positional, arguments makes your function call more explicit and allows you to specify them in different orders.
Per the Zen of Python, ‘explicit is better than implicit’.
# explicitly computing store sales for store 46 during week 43
store_sales(data=df, week=43, store=46)np.float64(60.39)Default arguments
Default arguments are those that take a default value if no argument value is passed during the function call. You can assign this default value by with the assignment operator =, just like in the below example. For example, if your analysis routinely analyzes transactions for all quantities but sometimes you only focus on sales for when quantity purchased meets some threshold, you could add a new parameter with a default value.
Default arguments should be placed after parameters with no defaults assigned in the function call.
def store_sales(data, store, week, qty_greater_than=0):
filt = (data['store_id'] == store) & (data['week'] == week) & (data['quantity'] > qty_greater_than)
total_sales = data['sales_value'][filt].sum()
return total_sales
# you do not need to specify an input for qty_greater_than
store_sales(data=df, store=309, week=48)np.float64(395.6)# but you can if you want to change it from the default
store_sales(data=df, store=309, week=48, qty_greater_than=2)np.float64(92.73)*args and **kwargs
*args and **kwargs allow you to pass a variable number of arguments to a function. This can be usefule when you do not know before hand how many arguments will be passed to your function by the user or if you want to allow users to pass arguments through to an embedded function.
Just an FYI that it is not necessary to write *args or **kwargs. Only the * (asterisk) is necessary. You could have also written *var and **vars. Writing *args and **kwargs is just a convention established in the Python community.
*args is used to send a non-keyworded variable length argument list to the function. When the function is called, Python collects the *args values as a tuple, which can be used in a similar manner as any other tuple functionality (i.e. indexing, for looped) For example, we can let the user supply as many string inputs to the very useful yell() function by using *args.
def yell(*args):
new_text = ' '.join(args).upper()
return new_text
yell('hello world!', 'I', 'love', 'Python!!')'HELLO WORLD! I LOVE PYTHON!!'The special syntax **kwargs in function definitions in python is used to pass a keyworded, variable-length argument list. The reason is because the double star allows us to pass through keyword arguments (and any number of them). Python collects the **kwargs into a new dictionary, which can be used for any normal dictionary functionality.
# **kwargs just creates a dictionary
def students(**kwargs):
print(kwargs)
students(student1='John', student2='Robert', student3='Sally'){'student1': 'John', 'student2': 'Robert', 'student3': 'Sally'}# we can use this dictionary however necessary
def print_student_names(**kwargs):
for key, value in kwargs.items():
print(f'{key} = {value}')
print_student_names(student1='John', student2='Robert', student3='Sally')student1 = John
student2 = Robert
student3 = SallyType hints
Python 3.5 added a new library called typing that adds type hinting to Python. Type hinting is part of a larger functionality called Type Checking (see this tutorial for a comprehensive Type Checking guide). Type hinting provides a way to help users better understand what type of arguments a function takes and the expected output.
For example, let’s look at a simple function:
def some_function(name, age):
return f'{name} is {age} years old'
some_function('Tom', 27)'Tom is 27 years old'In the above function we simply expect the user to insert the proper type of arguments and to realize the output will be a string. Now, this isn’t that challenging because its a small and simple function but as our functions get more complex it is not always easy to decipher what type of arguments should be passed and what the output will be.
We can hint to the user this information with type hints by re-writing the function as below. Here, we are hinting that the name argument should be a string, age should be an integer, and the output will be a string (-> str).
def some_function(name: str, age: int) -> str:
return f'{name} is {age} years old'
some_function('Tom', 27)'Tom is 27 years old'Now, when you look at the function documentation, you can quickly see the type hints (we’ll see additional ways to improve function documentation in the Docstrings section).
help(some_function)Help on function some_function in module __main__:
some_function(name: str, age: int) -> str
Even better, most IDEs support type hints so that they can give you feedback as you are typing:
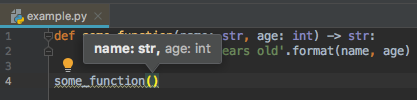
When declaring types, you can use any of the built-in Python data types. This includes, but is not limited to:
int,float,str,booltuple,list,set,dict,arrayfrozensetOptionalIterable,Iterator- and many more!
You can also declare non-built-in data types such as Pandas and Numpy object types. For example, we can re-write our store_sales() function with type hints where we hint that data should be a pd.DataFrame.
Note that pd.DataFrame assumes that you imported the Pandas module with the pd alias.
def store_sales(data: pd.DataFrame, store: int, week: int) -> float:
filt = (data['store_id'] == store) & (data['week'] == week)
total_sales = data['sales_value'][filt].sum()
return total_sales
store_sales(data=df, store=309, week=48)np.float64(395.6)Knowledge check
18.6 Docstrings
Type hints are great for guiding users; however, they only provide small hints. Python docstrings are a much more robust way to document a Python function (docstrings can also be used to document modules, classes, and methods). Docstrings are used to provide users with descriptive information about the function, required inputs, expected outputs, example usage and more. Also, it is a common practice to generate online (html) documentation automatically from docstrings using tools such as Sphinx.
See the Pandas API reference for the various Pandas functions/methods/class for example Sphinx documentation that is built from docstrings.
Docstrings typically consist of a multi-line character string description that follows the header line of a function definition. The following provides an example for a simple addition function. Note how the docstring provides a summary of what the function does, information regarding expected parameter inputs, what the returned output will be, a “see also” section that lets users know about related functions/methods (this can be skipped if not applicable), and some examples of implementing the function.
def store_sales(data: pd.DataFrame, store: int, week: int) -> float:
"""
Compute total store sales.
This function computes the total sales for a given
store and week based on a user supplied DataFrame that
contains sales in a column named `sales_value`.
Parameters
----------
data : DataFrame
Pandas DataFrame
store : int
Integer value representing store number
week : int
Integer value representing week of year
Returns
-------
float
A float object representing total store sales
See Also
--------
store_visits : Computes total store visits
Examples
--------
>>> store_sales(data=df, store=309, week=48)
395.6
>>> store_sales(data=df, store=46, week=43)
60.39
"""
filt = (data['store_id'] == store) & (data['week'] == week)
total_sales = data['sales_value'][filt].sum()
return total_salesKnowledge check
18.7 Errors and exceptions
For functions that will be used over and over again, and especially for those used by someone other than the creator of the function, it is good to include procedures to check for errors that may derail function execution. This may include ensuring the user supplies proper argument types, the computation can perform with the values supplied, or even that execution can be performed in a reasonable amount of time.
This falls under the umbrella of exception handling and is actually far broader than what we can cover here. In this section, we’ll demonstrate some of the basics.
Validating arguments
A common problem is when the user supplies invalid argument types or values. Although we have seen how to use type hints and docstrings to inform users, we can also include useful exception calls for when users supply improper argument types and values. For example, the following will check if the arguments of the correct type by using isinstance and, if they are not, we raise an Exception and include an informative error.
def store_sales(data: pd.DataFrame, store: int, week: int) -> float:
# argument validation
if not isinstance(data, pd.DataFrame): raise Exception('`data` should be a Pandas DataFrame')
if not isinstance(store, int): raise Exception('`store` should be an integer')
if not isinstance(week, int): raise Exception('`week` should be an integer')
# computation
filt = (data['store_id'] == store) & (data['week'] == week)
total_sales = data['sales_value'][filt].sum()
return total_sales
store_sales(data=df, store='309', week=48)--------------------------------------------------------------------------- Exception Traceback (most recent call last) Cell In[24], line 12 9 total_sales = data['sales_value'][filt].sum() 10 return total_sales ---> 12 store_sales(data=df, store='309', week=48) Cell In[24], line 4, in store_sales(data, store, week) 1 def store_sales(data: pd.DataFrame, store: int, week: int) -> float: 2 # argument validation 3 if not isinstance(data, pd.DataFrame): raise Exception('`data` should be a Pandas DataFrame') ----> 4 if not isinstance(store, int): raise Exception('`store` should be an integer') 5 if not isinstance(week, int): raise Exception('`week` should be an integer') 7 # computation Exception: `store` should be an integer
Note that Exception() is used to create a generic exception object/output. Python has many built-in exception types that can be used to indicate a specific error has occured. For example, we could replace Exception() with TypeError() in the previous example to make it more specific that the error is due to an invalid argument type.
def store_sales(data: pd.DataFrame, store: int, week: int) -> float:
# argument validation
if not isinstance(data, pd.DataFrame): raise TypeError('`data` should be a Pandas DataFrame')
if not isinstance(store, int): raise TypeError('`store` should be an integer')
if not isinstance(week, int): raise TypeError('`week` should be an integer')
# computation
filt = (data['store_id'] == store) & (data['week'] == week)
total_sales = data['sales_value'][filt].sum()
return total_sales
store_sales(data=df, store='309', week=48)--------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In[25], line 12 9 total_sales = data['sales_value'][filt].sum() 10 return total_sales ---> 12 store_sales(data=df, store='309', week=48) Cell In[25], line 4, in store_sales(data, store, week) 1 def store_sales(data: pd.DataFrame, store: int, week: int) -> float: 2 # argument validation 3 if not isinstance(data, pd.DataFrame): raise TypeError('`data` should be a Pandas DataFrame') ----> 4 if not isinstance(store, int): raise TypeError('`store` should be an integer') 5 if not isinstance(week, int): raise TypeError('`week` should be an integer') 7 # computation TypeError: `store` should be an integer
We can expand this as much as necessary. For example, say we want to ensure users only use a store value that exists in our data. Currently, if the user supplies a store value that does not exist (i.e. 35), they simply get a return value of 0.
store_sales(data=df, store=35, week=48)np.float64(0.0)We can add an if statement to check if the store number exists and supply an error message to the user if it does not:
def store_sales(data: pd.DataFrame, store: int, week: int) -> float:
# argument validation
if not isinstance(data, pd.DataFrame): raise TypeError('`data` should be a Pandas DataFrame')
if not isinstance(store, int): raise TypeError('`store` should be an integer')
if not isinstance(week, int): raise TypeError('`week` should be an integer')
if store not in data.store_id.unique():
raise ValueError(f'`store` {store} does not exist in the supplied DataFrame')
# computation
filt = (data['store_id'] == store) & (data['week'] == week)
total_sales = data['sales_value'][filt].sum()
return total_sales
store_sales(data=df, store=35, week=48)--------------------------------------------------------------------------- ValueError Traceback (most recent call last) Cell In[27], line 15 12 total_sales = data['sales_value'][filt].sum() 13 return total_sales ---> 15 store_sales(data=df, store=35, week=48) Cell In[27], line 7, in store_sales(data, store, week) 5 if not isinstance(week, int): raise TypeError('`week` should be an integer') 6 if store not in data.store_id.unique(): ----> 7 raise ValueError(f'`store` {store} does not exist in the supplied DataFrame') 10 # computation 11 filt = (data['store_id'] == store) & (data['week'] == week) ValueError: `store` 35 does not exist in the supplied DataFrame
Assert statements
Python’s assert statement is a debugging aid that tests a condition. If the condition is true, it does nothing and your program just continues to execute. But if the assert condition evaluates to false, it raises an AssertionError exception with an optional error message. This seems very similar to the example in the last section where we checked if the supplied store ID exists. However, the proper use of assertions is to inform users about unrecoverable errors in a program. They’re not intended to signal expected error conditions, like “store ID not found”, where a user can take corrective action or just try again.
Another way to look at it is to say that assertions are internal self-checks for your program. They work by declaring some conditions as impossible in your code. If one of these conditions doesn’t hold that means there’s a bug in the program.
For example, say you have a program that automatically applies a discount to product and you eventually write the following apply_discount function:
def apply_discount(product, discount):
price = round(product['price'] * (1.0 - discount), 2)
assert 0 <= price <= product['price']
return priceNotice the assert statement in there? It will guarantee that, no matter what, discounted prices cannot be lower than $0 and they cannot be higher than the original price of the product.
Let’s make sure this actually works as intended. You can see that the second example throws an AssertionError
# 25% off 3.50 should equal 2.62
milk = {'name': 'Chocolate Milk', 'price': 3.50}
apply_discount(milk, 0.25)2.62# 200% discount is not allowed
apply_discount(milk, 2.00)--------------------------------------------------------------------------- AssertionError Traceback (most recent call last) Cell In[30], line 2 1 # 200% discount is not allowed ----> 2 apply_discount(milk, 2.00) Cell In[28], line 3, in apply_discount(product, discount) 1 def apply_discount(product, discount): 2 price = round(product['price'] * (1.0 - discount), 2) ----> 3 assert 0 <= price <= product['price'] 4 return price AssertionError:
In the above example, we simply got an AssertionError but no message to help us understand what caused the error. The assert statement follows the syntax of assert condition, message so we can add an informative message at the end of our assert statement.
def apply_discount(product, discount):
price = round(product['price'] * (1.0 - discount), 2)
assert 0 <= price <= product['price'], 'Invalid discount applied'
return price
apply_discount(milk, 2.00)--------------------------------------------------------------------------- AssertionError Traceback (most recent call last) Cell In[31], line 6 3 assert 0 <= price <= product['price'], 'Invalid discount applied' 4 return price ----> 6 apply_discount(milk, 2.00) Cell In[31], line 3, in apply_discount(product, discount) 1 def apply_discount(product, discount): 2 price = round(product['price'] * (1.0 - discount), 2) ----> 3 assert 0 <= price <= product['price'], 'Invalid discount applied' 4 return price AssertionError: Invalid discount applied
Try and except
In the prior sections, we looked at ways to identify errors that may occur. The result of our exception handling is to signal an error occurred and stop the program. However, there are often times when we do not want to stop the program. For example, if the program has a database connection that should be closed after execution then we need our program to continue running even if an error occurs to ensure the connection is closed.
The try except procedure allows us to try execute code. If it works, great! If not, rather than just throw an exception error, we define what the program should continue to do. For example, the following tries the apply_discount() function with a pre-defined discount value. If it throws and exception then we adjust the discount value (if discount is greater than 100% of product price we adjust it to the largest acceptable value, if its less than 0 we just set it to 0%).
# this discount is created somewhere else in the program
discount = 2
# if discount causes an error adjust it
try:
apply_discount(milk, discount)
except Exception:
if discount > 1: discount = 0.99
if discount < 0: discount = 0
apply_discount(milk, discount)The try except procedure allows us to include as many except statements as necessary for different types of errors (think of them like elifs). For example, the following illustrates how we could have different types of code execution for a TypeError, a ValueError, and then the final else statement captures all other errors.
This procedure will run in order, consequently you want to have the most specific exception handlers first followed by more general exception handlers later on.
try:
store_sales(data=df, store=35, week=48)
except TypeError:
print('do something specific for a `TypeError`')
except ValueError:
print('do something specific for a `ValueError`')
else:
print('do something specific for all other errors')do something specific for a `ValueError`Lastly, we may have a certain piece of code that we always want to ensure gets ran in a program. For example, we may need to ensure a database connection or file is closed before an error is thrown. The following illustrates how we can add a finally at the end of our try except procedure. This finally will always be ran. If the code in the try clause runs without error, the finally code chunk will run after the try block. If an error occurse, the finally code chunk will run before the relevant except code chunk.
try:
store_sales(data=df, store=35, week=48)
except TypeError:
raise
except ValueError:
raise
finally:
print('Code to close database connection')Code to close database connection--------------------------------------------------------------------------- ValueError Traceback (most recent call last) Cell In[34], line 2 1 try: ----> 2 store_sales(data=df, store=35, week=48) 3 except TypeError: 4 raise Cell In[27], line 7, in store_sales(data, store, week) 5 if not isinstance(week, int): raise TypeError('`week` should be an integer') 6 if store not in data.store_id.unique(): ----> 7 raise ValueError(f'`store` {store} does not exist in the supplied DataFrame') 10 # computation 11 filt = (data['store_id'] == store) & (data['week'] == week) ValueError: `store` 35 does not exist in the supplied DataFrame
Knowledge check
18.8 Scoping
Scoping refers to the set of rules a programming language uses to lookup the value to variables and/or symbols. The following illustrates the basic concept behind the lexical scoping rules that Python follows. In short, Python follows a nested environment structure and uses what is commonly referred to as the LEGB search rule:
- Search local scope first,
- then the local scopes of enclosing functions,
- then the global scope,
- and finally the built-in scope
Searching for variables
What exactly does this mean? A function has its own environment and when you assign an argument in the def header of the function, the function creates a separate environment that keeps that variable separate from any variable in the global environment. This is why you can have an x variable in the global environment that won’t be confused with an x variable in your function:
x = 84
def func(x):
return x + 1
func(x = 50)51However, the function environment is only active when called and all function variables are removed from memory after being called. Consequently, you can continue using x that is contained in the global environment.
x84However, if a variable does not exist within the function, Python will look one level up to see if the variable exists. In this case, since y is not supplied in the function header, Python will look in the next environment up (global environment in this case) for that variable:
y = 'Boehmke'
def func(x):
return x + ' ' + y
func(x = 'Brad')'Brad Boehmke'The same will happen if we have nested functions. Python will search in enclosing functions in a hierarchical fashion until it finds the necessary variables. In this convoluted procedure…
yis a global variable,x&separe local variables to themy_namefunction,- and
my_pastehas no local variables, - the
my_namefunction getsyfrom the global environment, - and the
my_pastefunction gets all its inputs from themy_nameenvironment.
We do not recommend that you write functions like this. This is primarily only for explaining how Python searches for information, which can be helpful for debugging.
y = 'Boehmke'
def my_name(sep):
x = 'Brad'
def my_paste():
return x + sep + y
return my_paste()
my_name(sep=' ')'Brad Boehmke'Changing variables
It is possible to change variable values that are outside of the active environment. This is rarely necessary, and is usually not good practice, but it is good to know about. For example, the following changes the global variable y by including the keyword-variable statement global y prior to making the assignment of the new value for y.
The same can be done with changing values in nested functions; however, you would use the keyword nonlocal to change the value of an enclosing function’s local variable.
y = 8451
def convert(x):
x = str(x)
firstpart, secondpart = x[:len(x)//2], x[len(x)//2:]
global y
y = firstpart + '.' + secondpart
return y
convert(8451)'84.51'y'84.51'18.9 Anonymous functions
So far we have been discussing defined functions; however, Python allows you to generate anonymous functions on the fly. These are often referred to as lambdas. Lambdas allow for an alternative approach when creating short and simple functions that are only used once or twice.
For example, the following two functions are equivalent:
# defined function
def func(x, y, z):
return x + y + z
# lambda function
lambda x, y, z: x + y + z Note how the lambda’s body is a single expression and not a block statement. This is a requirement, which typically restricts lambdas to very short, concise function calls. The best use case for lambda functions are for when you want a simple function to be anonymously embedded within a larger expressions. For example, say we wanted to loop over each item in a list and apply a simple square function, we could accomplish this by supplying a lambda function to the map function. map just iterates over each item in an object and applies a given function (you could accomplish the exact same with a list comprehension).
nums = [48, 6, 9, 21, 1]
list(map(lambda x: x ** 2, nums))[2304, 36, 81, 441, 1]Another good example is the following one you already lesson 6a where we apply a lambda function to assign ‘high value’ for each transaction where sales_value is greater than 10 and ‘low value’ for all other transactions.
(
df['sales_value']
.apply(lambda x: 'high value' if x > 10 else 'low value')
)0 low value
1 low value
2 low value
3 low value
4 low value
...
1469302 low value
1469303 low value
1469304 low value
1469305 low value
1469306 low value
Name: sales_value, Length: 1469307, dtype: objectHere is another example where we group by basket_id and then apply a lambda function to compute the average cost per item in each basket.
(
df[['basket_id', 'sales_value', 'quantity']]
.groupby('basket_id')
.apply(lambda x: (x['sales_value'] / x['quantity']).mean())
)/tmp/ipykernel_3742/1550772873.py:4: FutureWarning:
DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
basket_id
31198437603 1.951207
31198445400 1.250000
31198445429 2.045000
31198445465 1.680000
31198452527 4.048333
...
41480008448 1.533810
41480013048 1.206667
41480018446 1.773210
41481252623 1.285556
41481282915 8.495000
Length: 155848, dtype: float64Knowledge check
18.10 Summary
Writing your own functions is one of the most essential skills for any data scientist. In this chapter, you learned how to encapsulate your logic, reduce repetition, and build cleaner, more modular code through custom function definitions.
We began by discussing when and why to write functions, especially when working on complex data analysis tasks that benefit from reusability and clarity. You saw how functions differ from methods and how they support both simple and advanced programming constructs.
You learned how to:
- Define functions using the
defkeyword, including parameters and return values. - Use keyword arguments and default arguments to make your functions more flexible and explicit.
- Leverage
*argsand**kwargsto support variable-length argument lists for more general-purpose tools. - Add type hints to clarify what types of inputs a function expects and what it returns—great for documentation and collaboration.
- Document your functions with docstrings, following common Python conventions that enhance readability and support automated documentation tools.
- Apply error handling techniques using
raise,try-except,assert, and custom error messages to make your functions more robust and user-friendly. - Understand Python’s variable scoping rules, including the LEGB rule (Local, Enclosing, Global, Built-in), and how variables are resolved when functions are nested.
- Create concise anonymous functions (a.k.a.
lambdafunctions) and apply them within higher-order functions likemap,apply, andgroupby.
Throughout the chapter, you saw realistic examples related to store sales and transaction data, reinforcing the importance of custom functions in real-world data mining and analysis workflows. Whether you’re cleaning data, transforming values, calculating metrics, or building more advanced analytics pipelines, your ability to write well-structured functions will directly improve the quality and maintainability of your work.
In short, functions are foundational to writing professional, efficient, and reusable Python code—skills that will serve you across any domain of data science.
18.11 Exercise: Practicing Function Writing and Application
In this exercise set, you’ll practice defining and applying custom Python functions, using type hints and docstrings, and leveraging methods like .apply() to work with real-world data. These tasks will help solidify your understanding of functions and how to use them in data cleaning, feature engineering, and exploratory analysis workflows.
You can run these exercises in your own Python editor or in the companion notebook.
Tip💡 Stuck or Unsure?
Use ChatGPT, GitHub Copilot, or any other AI coding assistant to debug your code or talk through your logic. It’s a great way to reinforce concepts and practice problem solving.