Lesson 2a: Packages, libraries & modules#
The Python source distribution has long maintained the philosophy of “batteries included” – having a rich and versatile standard library which is immediately available, without making the user download separate packages. This gives the Python language a head start in many projects.
- PEP 206
One feature of Python that makes it useful for a wide range of tasks is the fact that it comes “batteries included” – that is, the Python standard library contains useful tools for a wide range of tasks. On top of this, there is a broad ecosystem of third-party tools and packages that offer more specialized functionality.
Learning objectives#
By the end of this lesson you’ll be able to:
Explain the difference between the standard library and third-party libraries.
Use importing tools to install libraries.
Understand at a high-level what some commonly used third-party libraries provide.
Have a more complete picture of Python’s data science packaging ecosystem.
Terminology#
Video 🎥:
People often use the terms “package”, “library”, and “module” synonymously. If you are familiar with the R programming language you’ve probably heard some of these terms before. Although there are some semantical differences between R and Python, here is how you can think of the two terms:
A package generally refers to source code that is bundled up in a way that a package manager can host. PyPI and Anaconda are the two primary public package managers for Python. When you pip install pkg or conda install pkg you are installing the pkg package from PyPI or Anaconda, respectively, to your computer or the server you’re working on.
A library: generally refers to a centralized location on an operating system where installed package source code resides and can be imported into a current session. When you use pip list or conda list you will see a list of installed packages, which we often refer to as libraries.
Note
Below is a list of packages installed in my environment. This will differ from what you get because you likely have not installed these packages yet. Also, again notice the % symbol before pip list; we call this a magic command. If you were in a terminal you would just run pip list but in Jupyter, we can use % to tell Jupyter to run this as a terminal command but from the notebook cell.
%pip list
Package Version
----------------------------- --------------
accessible-pygments 0.0.5
alabaster 0.7.16
anyio 4.4.0
appnope 0.1.4
argon2-cffi 23.1.0
argon2-cffi-bindings 21.2.0
arrow 1.3.0
asttokens 2.4.1
async-lru 2.0.4
attrs 23.2.0
Babel 2.14.0
beautifulsoup4 4.12.3
black 21.12b0
blackcellmagic 0.0.3
bleach 6.1.0
bokeh 3.4.2
Brotli 1.1.0
cached-property 1.5.2
certifi 2024.7.4
cffi 1.16.0
charset-normalizer 3.3.2
click 8.1.7
colorama 0.4.6
colorcet 3.1.0
comm 0.2.2
completejourney-py 0.0.3
contourpy 1.2.1
cycler 0.12.1
dataclasses 0.8
debugpy 1.8.2
decorator 5.1.1
defusedxml 0.7.1
docutils 0.20.1
entrypoints 0.4
et-xmlfile 1.1.0
exceptiongroup 1.2.0
executing 2.0.1
fastjsonschema 2.20.0
fonttools 4.53.1
fqdn 1.5.1
ghp-import 2.1.0
greenlet 3.0.3
h11 0.14.0
h2 4.1.0
hpack 4.0.0
httpcore 1.0.5
httpx 0.27.0
hyperframe 6.0.1
idna 3.7
imagesize 1.4.1
importlib_metadata 8.0.0
importlib_resources 6.4.0
ipykernel 6.29.5
ipython 8.26.0
ipywidgets 8.1.3
iqplot 0.3.6
isoduration 20.11.0
jedi 0.19.1
Jinja2 3.1.4
joblib 1.4.2
json5 0.9.25
jsonpointer 3.0.0
jsonschema 4.23.0
jsonschema-specifications 2023.12.1
jupyter 1.0.0
jupyter_bokeh 4.0.5
jupyter-book 1.0.2
jupyter-cache 1.0.0
jupyter_client 8.6.2
jupyter-console 6.6.3
jupyter_core 5.7.2
jupyter-events 0.10.0
jupyter-lsp 2.2.5
jupyter_server 2.14.1
jupyter_server_terminals 0.5.3
jupyterlab 4.2.3
jupyterlab_pygments 0.3.0
jupyterlab_server 2.27.2
jupyterlab-spellchecker 0.8.4
jupyterlab_widgets 3.0.11
kiwisolver 1.4.5
latexcodec 2.0.1
linkify-it-py 2.0.3
markdown-it-py 3.0.0
MarkupSafe 2.1.5
matplotlib 3.8.4
matplotlib-inline 0.1.7
mdit-py-plugins 0.4.1
mdurl 0.1.2
mistune 3.0.2
munkres 1.1.4
mypy-extensions 1.0.0
myst-nb 1.1.1
myst-parser 2.0.0
nbclient 0.10.0
nbconvert 7.16.4
nbformat 5.10.4
nest_asyncio 1.6.0
notebook 7.2.1
notebook_shim 0.2.4
numpy 2.0.0
openpyxl 3.1.2
overrides 7.7.0
packaging 24.1
pandas 2.2.2
pandocfilters 1.5.0
parso 0.8.4
pathspec 0.12.1
patsy 0.5.6
pexpect 4.9.0
pickleshare 0.7.5
pillow 10.4.0
pip 24.0
pkgutil_resolve_name 1.3.10
platformdirs 4.2.2
plotly 5.22.0
prometheus_client 0.20.0
prompt_toolkit 3.0.47
psutil 6.0.0
ptyprocess 0.7.0
pure-eval 0.2.2
pyarrow 16.1.0
pybtex 0.24.0
pybtex-docutils 1.0.3
pycparser 2.22
pydata-sphinx-theme 0.15.4
Pygments 2.18.0
pyobjc-core 10.3.1
pyobjc-framework-Cocoa 10.3.1
pyparsing 3.1.2
PySocks 1.7.1
python-dateutil 2.9.0
python-json-logger 2.0.7
pytz 2024.1
PyYAML 6.0.1
pyzmq 26.0.3
qtconsole 5.5.2
QtPy 2.4.1
referencing 0.35.1
requests 2.32.3
rfc3339-validator 0.1.4
rfc3986-validator 0.1.1
rpds-py 0.19.0
scikit-learn 1.5.1
scipy 1.14.0
seaborn 0.13.2
Send2Trash 1.8.3
setuptools 70.1.1
six 1.16.0
sniffio 1.3.1
snowballstemmer 2.2.0
soupsieve 2.5
Sphinx 7.3.7
sphinx-book-theme 1.1.3
sphinx-comments 0.0.3
sphinx-copybutton 0.5.2
sphinx_design 0.6.0
sphinx_external_toc 1.0.1
sphinx-jupyterbook-latex 1.0.0
sphinx-multitoc-numbering 0.1.3
sphinx-thebe 0.3.1
sphinx-togglebutton 0.3.2
sphinxcontrib-applehelp 1.0.8
sphinxcontrib-bibtex 2.6.2
sphinxcontrib-devhelp 1.0.6
sphinxcontrib-htmlhelp 2.0.5
sphinxcontrib-jsmath 1.0.1
sphinxcontrib-qthelp 1.0.7
sphinxcontrib-serializinghtml 1.1.10
SQLAlchemy 2.0.31
stack-data 0.6.2
statsmodels 0.14.2
tabulate 0.9.0
tenacity 8.2.2
terminado 0.18.1
threadpoolctl 3.5.0
tinycss2 1.3.0
tomli 1.2.3
tornado 6.4.1
traitlets 5.14.3
types-python-dateutil 2.9.0.20240316
typing_extensions 4.12.2
typing-utils 0.1.0
tzdata 2024.1
uc-micro-py 1.0.3
uri-template 1.3.0
urllib3 2.2.2
watermark 2.4.3
wcwidth 0.2.13
webcolors 24.6.0
webencodings 0.5.1
websocket-client 1.8.0
wheel 0.43.0
widgetsnbextension 4.0.11
xarray 2024.6.0
xyzservices 2024.6.0
zipp 3.19.2
zstandard 0.22.0
Note: you may need to restart the kernel to use updated packages.
When you run sys.path you will get the path to the library where your installed packages are stored. Again, your paths will differ but just realize that these are the locations that Python will search for a library when you run import some_package.
import sys
sys.path
['/opt/anaconda3/envs/bana6043/lib/python312.zip',
'/opt/anaconda3/envs/bana6043/lib/python3.12',
'/opt/anaconda3/envs/bana6043/lib/python3.12/lib-dynload',
'',
'/opt/anaconda3/envs/bana6043/lib/python3.12/site-packages']
A module is the broard term used for any code you are importing from outside your current script/notebook. This may include libraries installed on your computer or it may also include stand alone .py files that you created to hold support functions for your current analysis and you want to import them into your current notebook.
For example, I have a simple hello.py file that I included in my current directory with the following function:
def hello_world(name):
print(f"Hello {name}")
Don’t worry about the details of the code. The point I want to make is I can import this module and use the hello_world() function I created with the following:
from hello import hello_world
hello_world('Brad')
Hello Brad
Importing#
In the code above you saw the import statement. The import statement allows us to import code from another module. There are a few ways to use the statement, which we will mention briefly here, from most recommended to least recommended.
Video 🎥:
Explicit module import#
Explicit import of a module preserves the module’s content in a namespace. The namespace is then used to refer to its contents with a dot (“.”) between them.
Note
Everything in Python is an object, so if we want to access the methods and attributes available inside an object, we use dot syntax. This is no different when we import a module. Python treats the module as an object and we can access anything in that module via dot syntax.
For example, here we’ll import the built-in math module and compute the cosine of pi:
import math
x = math.cos(math.pi)
x
-1.0
Explicit module import by alias#
For longer module names, it’s not convenient to use the full module name each time you access some element. For this reason, we’ll commonly use the import ... as ... pattern to create a shorter alias for the namespace. For example, the NumPy (Numerical Python) package, a popular third-party package useful for data science, is by convention imported under the alias np:
import numpy as np
x = np.cos(np.pi)
x
np.float64(-1.0)
Explicit import of module contents#
Sometimes rather than importing the module namespace, you would just like to import a few particular items from the module. This can be done with the from ... import ... pattern. For example, we can import just the cos function and the pi constant from the math module:
from math import cos, pi
x = cos(pi)
x
-1.0
Implicit import of module contents#
Finally, it is sometimes useful to import the entirety of the module contents into the local namespace. This can be done with the from ... import * pattern:
from math import *
x = sin(pi) ** 2 + cos(pi) ** 2
x
1.0
Warning
This pattern should be used sparingly, if at all. The problem is that such imports can sometimes overwrite function names that you do not intend to overwrite, and the implicitness of the statement makes it difficult to determine what has changed.
For example, Python has a built-in sum function that can be used for various operations:
sum(range(5), -1)
9
Now observe what happens if we make the exact same function call after importing * (everything) from numpy:
from numpy import *
sum(range(5), -1)
np.int64(10)
The result is off by one! The reason for this is that the import * statement replaces the built-in sum function with the numpy.sum function, which has a different call signature.
Tip
Implicit module importing is generally frowned upon and in this class I expect you to use one of the three explicit importing approaches
Standard library#
Video 🎥:
In the above code we’ve seen a few different libraries installed (math and numpy). These libraries represent two of the many readily available libraries at your disposal. However, we refer to the math library is part of the standard library and the numpy library is considered a third party library.
So far we’ve seen several data types that Python offers out-of-the-box. However, to keep things organized, some Python functionality is stored in standalone packages, or libraries of code. The word “module” is generally synonymous with package; you will hear both in discussions of Python.
Some packages, like math, are bundled with every Python install; downloading Python guarantees you’ll have these packages.
Collectively, this group of packages is known as the standard library.
Python’s standard library contains many useful built-in modules, which you can read about fully in Python’s documentation. Any of these can be imported with the import statement, and then explored using the help function seen in the previous module. Here is an extremely incomplete list of some of the modules you might wish to explore and learn about:
osandsys: Tools for interfacing with the operating system, including navigating file directory structures and executing shell commandsmathandcmath: Mathematical functions and operations on real and complex numbersitertools: Tools for constructing and interacting with iterators and generatorsfunctools: Tools that assist with functional programmingrandom: Tools for generating pseudorandom numberspickle: Tools for object persistence: saving objects to and loading objects from diskjsonandcsv: Tools for reading JSON-formatted and CSV-formatted files.urllib: Tools for doing HTTP and other web requests.
You can find information on these, and many more, in the Python standard library documentation: https://docs.python.org/3/library/.
For example, functionality related to the operating system – such as creating files and folders – is stored in a package called os.
To use the tools in os, we import the package.
import os
Once we import it, we gain access to everything inside. With Jupyter’s autocomplete, we can type os. and hit tab to see a list of available functions. In this example I use os.getcwd() to print out the current working directory I am in.
# Move your cursor to the end of the below line and press tab.
os.getcwd()
'/Users/b294776/Desktop/workspace/training/UC/uc-bana-6043/book/02-module'
Knowledge check#
Questions:
Go to the standard library documentation and read about the
randomlibrary.Identify the function that will allow you to generate random integers.
Import this function from the
randompackage.Generate a random integer between the values 0-10.
Third-party modules#
Video 🎥:
One of the things that makes Python useful, especially within the world of data science, is its ecosystem of third-party modules. These can be imported just as the built-in modules, but first the modules must be installed on your system. As previously mentioned, Python Package Index (PyPI for short) and Anaconda are the two primary public package managers for Python. To install packages from these locations we just use the following:
# install from PyPI
pip install pkg_name
# install from Anaconda
conda install pkg_name
Note
There are currently (May 1, 2022) about 370,000 packages available through the Python Package Index, PyPI. Usually, you can ask Google about what you are trying to do, and there is often a third party module to help you do it. The most useful (for scientific computing) and thoroughly tested packages and modules are available using conda. Others can be installed using pip.
We will extensively use the Numpy, SciPy, Pandas, and Bokeh packages, among others, in this class, and I’m sure you will also use them beyond. Let’s look at some examples of these third party packages to give you a flavor of what they do. Don’t worry, we’ll go into some of these more thoroughly in later lessons!
NumPy#
NumPy provides an efficient way to store and manipulate multi-dimensional dense arrays in Python. The important features of NumPy are:
It provides an ndarray structure, which allows efficient storage and manipulation of vectors, matrices, and higher-dimensional datasets.
It provides a readable and efficient syntax for operating on this data, from simple element-wise arithmetic to more complicated linear algebraic operations.
In the simplest case, NumPy arrays look a lot like Python lists. For example, here is an array containing the range of numbers 1 to 9:
import numpy as np
x = np.arange(1, 10)
x
array([1, 2, 3, 4, 5, 6, 7, 8, 9])
Tip
Standard convention is to import numpy as the np alias.
NumPy’s arrays offer both efficient storage of data, as well as efficient element-wise operations on the data. For example, to square each element of the array, we can apply the “**” operator to the array directly:
x ** 2
array([ 1, 4, 9, 16, 25, 36, 49, 64, 81])
This element-wise operation capability (commonly referred to as vectorization) is extremely useful but is not available in base Python. In base Python, if you had a list of these same numbers you would have to loop through each element in the list and compute the square of each number:
x_list = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# not supported
x_list ** 2
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[14], line 4
1 x_list = [1, 2, 3, 4, 5, 6, 7, 8, 9]
3 # not supported
----> 4 x_list ** 2
TypeError: unsupported operand type(s) for ** or pow(): 'list' and 'int'
We would need to use a non-vectorized approach that iterates through each element and computes the square. The below illustrates the much more verbose non-vectorized approach that produces the same result:
Note
Don’t worry about the syntax, you will learn about this in a later lesson. Just note how the above approach with Numpy is far more convenient!
x_squared = [val ** 2 for val in x_list]
x_squared
[1, 4, 9, 16, 25, 36, 49, 64, 81]
Numpy also provides a host of other vectorized arithmetic capabilities. For example, we can compute the mean of a list with the following:
np.mean([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
5.5
Unlike Python lists (which are limited to one dimension), NumPy arrays can be multi-dimensional. For example, here we will reshape our x array into a 3x3 matrix:
m = x.reshape((3, 3))
m
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
A two-dimensional array is one representation of a matrix, and NumPy knows how to efficiently do typical matrix operations. For example, you can compute the transpose using .T:
m.T
array([[1, 4, 7],
[2, 5, 8],
[3, 6, 9]])
or a matrix-vector product using np.dot:
np.dot(m, [5, 6, 7])
array([ 38, 92, 146])
and even more sophisticated operations like eigenvalue decomposition:
np.linalg.eigvals(m)
array([ 1.61168440e+01, -1.11684397e+00, -1.30367773e-15])
Note
Such linear algebraic manipulation underpins much of modern data analysis, particularly when it comes to the fields of machine learning and data mining.
Pandas#
Pandas is a much newer package than Numpy, and is in fact built on top of it. What Pandas provides is a labeled interface to multi-dimensional data, in the form of a DataFrame object that will feel very familiar to users of R and related languages. DataFrames in Pandas look something like the following.
Tip
It is a common convention to import Pandas with the pd alias.
import pandas as pd
df = pd.DataFrame({'label': ['A', 'B', 'C', 'A', 'B', 'C'],
'value': [1, 2, 3, 4, 5, 6]})
Note
In practice, rarely do we create a DataFrame in this manner; most of the time we are importing data from a tabular file (i.e. CSV) into a DataFrame. However, this is only for the purpose of providing some simple examples
The Pandas interface allows you to do things like select columns by name:
df['label']
0 A
1 B
2 C
3 A
4 B
5 C
Name: label, dtype: object
Apply string operations across string entries:
df['label'].str.lower()
0 a
1 b
2 c
3 a
4 b
5 c
Name: label, dtype: object
Compute statistical aggregations for numerical columns:
df['value'].sum()
21
And, perhaps most importantly, do efficient database-style joins and groupings:
df.groupby('label').sum()
| value | |
|---|---|
| label | |
| A | 5 |
| B | 7 |
| C | 9 |
Here in one line we have computed the sum of all objects sharing the same label, something that is much more verbose (and much less efficient) using tools provided in Numpy and core Python.
Note
In future lessons we will go much deeper into Pandas and you’ll also see a large dependency on using Pandas as we start exploring other parts of the statistical computing ecosystem (i.e. visualization, machine learning).
Matplotlib#
Matplotlib is currently the most popular scientific visualization packages in Python. Even proponents admit that its interface is sometimes overly verbose, but it is a powerful library for creating a large range of plots.
Tip
It is a common convention to import Matplotlib with the plt alias.
import matplotlib.pyplot as plt
plt.style.use('ggplot') # make graphs in the style of R's ggplot
Now let’s create some data and plot the results:
x = np.linspace(0, 10) # range of values from 0 to 10
y = np.sin(x) # sine of these values
plt.plot(x, y); # plot as a line
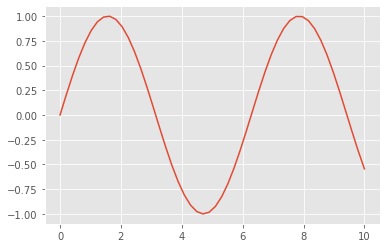
This is the simplest example of a Matplotlib plot; for ideas on the wide range of plot types available, see Matplotlib’s online gallery.
Note
Although you’ll be exposed to some Matplotlib throughout this course, we will tend to focus on other third-party visualization packages that are simpler to use.
SciPy#
SciPy is a collection of scientific functionality that is built on Numpy. The package began as a set of Python wrappers to well-known Fortran libraries for numerical computing, and has grown from there. The package is arranged as a set of submodules, each implementing some class of numerical algorithms. Here is an incomplete sample of some of the more important ones for data science:
scipy.fftpack: Fast Fourier transforms
scipy.integrate: Numerical integration
scipy.interpolate: Numerical interpolation
scipy.linalg: Linear algebra routines
scipy.optimize: Numerical optimization of functions
scipy.sparse: Sparse matrix storage and linear algebra
scipy.stats: Statistical analysis routines
For example, let’s take a look at interpolating a smooth curve between some data
from scipy import interpolate
# choose eight points between 0 and 10
x = np.linspace(0, 10, 8)
y = np.sin(x)
# create a cubic interpolation function
func = interpolate.interp1d(x, y, kind='cubic')
# interpolate on a grid of 1,000 points
x_interp = np.linspace(0, 10, 1000)
y_interp = func(x_interp)
# plot the results
plt.figure() # new figure
plt.plot(x, y, 'o')
plt.plot(x_interp, y_interp);
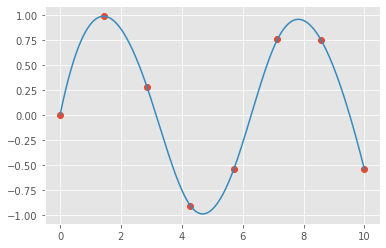
What we see is a smooth interpolation between the points.
Other Data Science Packages#
Built on top of these tools are a host of other data science packages, including general tools like Scikit-Learn for machine learning, Scikit-Image for image analysis, Seaborn for statistical visualization, and Statsmodels for statistical modeling; as well as more domain-specific packages like AstroPy for astronomy and astrophysics, NiPy for neuro-imaging, and many, many more.
No matter what type of scientific, numerical, or statistical problem you are facing, it’s likely there is a Python package out there that can help you solve it.
Exercises#
Tasks:
Spend some time familiarizing yourself with the Pandas documentation.
Watch the Pandas in 10 minutes video on the Getting Started page.
Computing environment#
Show code cell source
%load_ext watermark
%watermark -v -p jupyterlab,numpy,pandas,matplotlib,scipy
Python implementation: CPython
Python version : 3.9.4
IPython version : 7.26.0
jupyterlab: 3.1.4
numpy : 1.19.5
pandas : 1.2.4
matplotlib: 3.4.3
scipy : 1.7.1