Lesson 2c: Deeper dive on DataFrames#
Now that we know how to import data as a DataFrame, let’s spend a little time discussing DataFrames and what they are made up of. This should create a stronger foundation of Pandas and DataFrames.
Learning objectives#
At the end of this lesson you should be able to:
Explain the difference between DataFrames and Series
Set and manipulate index values
To illustrate our points throughout this lesson, we’ll use the following airlines data which simply includes the name of the airline carrier and the airline carrier code:
import pandas as pd
df = pd.read_csv('../data/airlines.csv')
df.head()
| carrier | name | |
|---|---|---|
| 0 | 9E | Endeavor Air Inc. |
| 1 | AA | American Airlines Inc. |
| 2 | AS | Alaska Airlines Inc. |
| 3 | B6 | JetBlue Airways |
| 4 | DL | Delta Air Lines Inc. |
What Are DataFrames Made of?#
Video 🎥:
Accessing an individual column of a DataFrame can be done by passing the column name as a string, in brackets ([]).
carrier_column = df['carrier']
carrier_column
0 9E
1 AA
2 AS
3 B6
4 DL
5 EV
6 F9
7 FL
8 HA
9 MQ
10 OO
11 UA
12 US
13 VX
14 WN
15 YV
Name: carrier, dtype: object
Individual columns are pandas Series objects.
type(carrier_column)
pandas.core.series.Series
A Series is like a NumPy array but with labels. They are strictly 1-dimensional and can contain any data type (integers, strings, floats, objects, etc), including a mix of them. Series can be created from a scalar, a list, ndarray or dictionary using pd.Series() (note the captial “S”). Here are some example series:
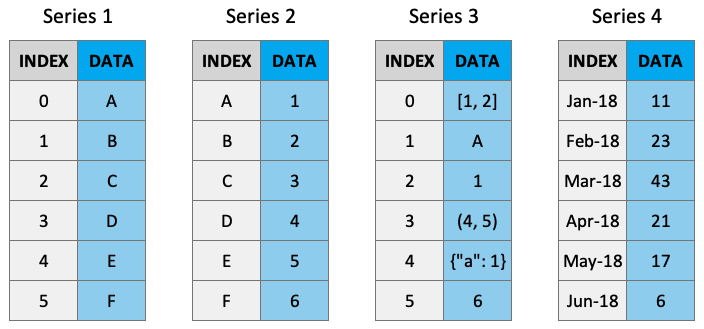
Source: Python Programming for Data Science
How are Series different from DataFrames?
They’re always 1-dimensional
They have different attributes & methods than DataFrames
For example, Series have a
to_listmethod – which doesn’t make sense to have on DataFrames
They don’t print in the pretty format of DataFrames, but in plain text (see above)
# A Series only has one dimension (number of elements)
carrier_column.shape
(16,)
# Whereas a DataFrame has two (rows and columns)
df.shape
(16, 2)
As mentioned above, Series will have different attributes & methods than DataFrames. For example, Series have a to_list method which converts the single array of values into a list. This is a common practice in a lot of workflows. However, a DataFrame does not have this method.
# A unique method to Series
carrier_column.to_list()
['9E',
'AA',
'AS',
'B6',
'DL',
'EV',
'F9',
'FL',
'HA',
'MQ',
'OO',
'UA',
'US',
'VX',
'WN',
'YV']
# DataFrames don't have this method so we'll get an error!
df.to_list()
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/var/folders/8f/c06lv6q17tjbyjv2nkt0_s4s1sh0tg/T/ipykernel_4260/33797969.py in ?()
1 # DataFrames don't have this method so we'll get an error!
----> 2 df.to_list()
/opt/anaconda3/envs/bana6043/lib/python3.12/site-packages/pandas/core/generic.py in ?(self, name)
6295 and name not in self._accessors
6296 and self._info_axis._can_hold_identifiers_and_holds_name(name)
6297 ):
6298 return self[name]
-> 6299 return object.__getattribute__(self, name)
AttributeError: 'DataFrame' object has no attribute 'to_list'
It’s important to be familiar with Series because they are fundamentally the core of DataFrames.
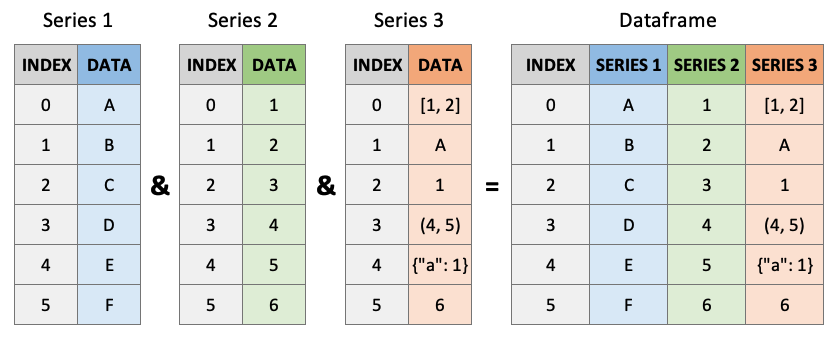
Source: Python Programming for Data Science
Not only are columns represented as Series, but so are rows!
df.head(1)
| carrier | name | |
|---|---|---|
| 0 | 9E | Endeavor Air Inc. |
# Fetch the first row of the DataFrame
first_row = df.loc[0]
first_row
carrier 9E
name Endeavor Air Inc.
Name: 0, dtype: object
type(first_row)
pandas.core.series.Series
Note
Whenever you select individual columns or rows, you’ll get Series objects.
What Can You Do with a Series?#
Video 🎥:
First, let’s create our own Series object from scratch – they don’t need to come from a DataFrame. Here, we pass a list in as an argument and it will be converted to a Series.
s = pd.Series([10, 20, 30, 40, 50])
s
0 10
1 20
2 30
3 40
4 50
dtype: int64
There are 3 things to notice about this Series:
The values (10, 20, 30…)
The dtype, short for data type.
The index (0, 1, 2…)
Values are fairly self-explanatory; we chose them in our input list.
Data types are also straightforward. Series are often homogeneous, holding only integers, floats, or generic Python objects (called just object); however, they actually can hold a mix of data types (though this is quite rare and we’ll stay away from doing this for the most part). As we mentioned in the last lesson, string elements in DataFrames are often labeled as having an object dtype. Because a Python object is general enough to contain any other type, any Series holding strings or other non-numeric data will typically default to be of type object.
For example, going back to our carriers DataFrame, note that the carrier column is of type object.
df['carrier']
0 9E
1 AA
2 AS
3 B6
4 DL
5 EV
6 F9
7 FL
8 HA
9 MQ
10 OO
11 UA
12 US
13 VX
14 WN
15 YV
Name: carrier, dtype: object
Indexes are more interesting. Every Series has an index, a way to reference each element. The index of a Series is a lot like the keys of a dictionary: each index element corresponds to a value in the Series, and can be used to look up that element.
# Our index is a range from 0 (inclusive) to 5 (exclusive).
s.index
RangeIndex(start=0, stop=5, step=1)
s
0 10
1 20
2 30
3 40
4 50
dtype: int64
As we learned to index other data structures in the previous module, we can continue to use [] for indexing Series. When we specify below, we are stating to get the 4th element in our Series located at index value 3.
s[3]
40
In our example, the index is just the integers 0-4, so right now it looks no different that referencing elements of a regular Python list. But indexes can be changed to something different – like the letters a-e, for example.
s.index = ['a', 'b', 'c', 'd', 'e']
s
a 10
b 20
c 30
d 40
e 50
dtype: int64
Now to look up the value 40, we reference 'd'.
s['d']
40
We saw earlier that rows of a DataFrame are Series. In such cases, the flexibility of Series indexes comes in handy; the index is set to the DataFrame column names.
df.head()
| carrier | name | |
|---|---|---|
| 0 | 9E | Endeavor Air Inc. |
| 1 | AA | American Airlines Inc. |
| 2 | AS | Alaska Airlines Inc. |
| 3 | B6 | JetBlue Airways |
| 4 | DL | Delta Air Lines Inc. |
# Note that the index is ['carrier', 'name']
first_row = df.loc[0]
first_row
carrier 9E
name Endeavor Air Inc.
Name: 0, dtype: object
This is particularly handy because it means you can extract individual elements based on a column name.
first_row['carrier']
'9E'
DataFrame Indexes#
Video 🎥:
It’s not just Series that have indexes! DataFrames have them too. Take a look at the carrier DataFrame again and note the bold numbers on the left.
df.head()
| carrier | name | |
|---|---|---|
| 0 | 9E | Endeavor Air Inc. |
| 1 | AA | American Airlines Inc. |
| 2 | AS | Alaska Airlines Inc. |
| 3 | B6 | JetBlue Airways |
| 4 | DL | Delta Air Lines Inc. |
These numbers are an index, just like the one we saw on our example Series. And DataFrame indexes support similar functionality.
# Our index is a range from 0 (inclusive) to 16 (exclusive).
df.index
RangeIndex(start=0, stop=16, step=1)
When loading in a DataFrame, the default index will always be 0 to N-1, where N is the number of rows in your DataFrame.
This is called a RangeIndex. Selecting individual rows by their index is done with the .loc accessor.
Tip
An accessor is an attribute designed specifically to help users reference something else (like rows within a DataFrame).
# Get the row at index 4 (the fifth row).
df.loc[4]
carrier DL
name Delta Air Lines Inc.
Name: 4, dtype: object
As with Series, DataFrames support reassigning their index. However, with DataFrames it often makes sense to change one of your columns into the index. This is analogous to a primary key in relational databases: a way to rapidly look up rows within a table.
In our case, maybe we will often use the carrier code (carrier) to look up the full name of the airline. In that case, it would make sense set the carrier column as our index.
df = df.set_index('carrier')
df.head()
| name | |
|---|---|
| carrier | |
| 9E | Endeavor Air Inc. |
| AA | American Airlines Inc. |
| AS | Alaska Airlines Inc. |
| B6 | JetBlue Airways |
| DL | Delta Air Lines Inc. |
Now the RangeIndex has been replaced with a more meaningful index, and it’s possible to look up rows of the table by passing carrier code to the .loc accessor.
df.loc['AA']
name American Airlines Inc.
Name: AA, dtype: object
Warning
Pandas does not require that indexes have unique values (that is, no duplicates) although many relational databases do have that requirement of a primary key. This means that it is possible to create a non-unique index, but highly inadvisable. Having duplicate values in your index can cause unexpected results when you refer to rows by index – but multiple rows have that index. Don’t do it if you can help it!
When starting to work with a DataFrame, it’s often a good idea to determine what column makes sense as your index and to set it immediately. This will make your code nicer – by letting you directly look up values with the index – and also make your selections and filters faster, because Pandas is optimized for operations by index. If you want to change the index of your DataFrame later, you can always reset_index (and then assign a new one).
df.head()
| name | |
|---|---|
| carrier | |
| 9E | Endeavor Air Inc. |
| AA | American Airlines Inc. |
| AS | Alaska Airlines Inc. |
| B6 | JetBlue Airways |
| DL | Delta Air Lines Inc. |
df = df.reset_index()
df.head()
| carrier | name | |
|---|---|---|
| 0 | 9E | Endeavor Air Inc. |
| 1 | AA | American Airlines Inc. |
| 2 | AS | Alaska Airlines Inc. |
| 3 | B6 | JetBlue Airways |
| 4 | DL | Delta Air Lines Inc. |
Exercises#
Questions:
Import the airports data as airports. The data contains the airport code, airport name, and some basic facts about the airport location.
What kind of index is the current index of
airports?Is this a good choice for the DataFrame’s index? If not, what column or columns would be a better candidate?
Set the
faacolumn as your new index.Using your new index, look up “Pittsburgh-Monroeville Airport”, which has FAA code 4G0. What is its altitude?
Reset your index in case you want to make a different column your index in the future.
Computing environment#
Show code cell source
%load_ext watermark
%watermark -v -p jupyterlab,pandas
Python implementation: CPython
Python version : 3.9.4
IPython version : 7.26.0
jupyterlab: 3.1.4
pandas : 1.2.4