Lesson 7d: Model Evaluation & Selection#
The last few lessons gave you a good introduction to applying Scikit-learn models. This lesson is going to go deeper into the idea of assessing model performance. We’ll discuss how to incoporate cross-validation procedures to give you a more robust assessment of model performance. We’ll also look at how to incorporate different evaluation metrics for scoring your models. And finally, we will discuss the concept of hyperparameter tuning, the bias-variance tradeoff, and how to implement a tuning strategy to find a model the maximizes generalizability.
Learning objectives#
By the end of this lesson you will be able to:
Perform cross-validation procedures for more robust model performance assessment.
Apply different evaluation metrics for scoring your model.
Execute hyperparameter tuning to find optimal model parameter settings.
Quick refresher#
But first, let’s review a few things that we learned in the previous modules.
Data prep#
In lesson 7b we discussed how we typically separate our features and target into distinct data objects and that we create a train-test split so we can measure model performance on data that our model was not trained on.
# packages used
import pandas as pd
from sklearn.model_selection import train_test_split
# import data
adult_census = pd.read_csv('../data/adult-census.csv')
# separate feature & target data
target = adult_census['class']
features = adult_census.drop(columns='class')
# drop the duplicated column `"education-num"` as stated in the data exploration notebook
features = features.drop(columns='education-num')
# split into train & test sets
X_train, X_test, y_train, y_test = train_test_split(features, target, random_state=123)
Feature engineering#
In lesson 7c we looked at how we can apply common feature engineering tasks to numeric and categorical features and how we can combine these tasks with ColumnTransformer.
# packages used
from sklearn.compose import make_column_selector as selector
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
# create selector object based on data type
numerical_columns_selector = selector(dtype_exclude=object)
categorical_columns_selector = selector(dtype_include=object)
# get columns of interest
numerical_columns = numerical_columns_selector(features)
categorical_columns = categorical_columns_selector(features)
# preprocessors to handle numeric and categorical features
numerical_preprocessor = StandardScaler()
categorical_preprocessor = OneHotEncoder(handle_unknown="ignore")
# transformer to associate each of these preprocessors with their respective columns
preprocessor = ColumnTransformer([
('one-hot-encoder', categorical_preprocessor, categorical_columns),
('standard_scaler', numerical_preprocessor, numerical_columns)
])
Modeling#
And we also discussed how we can combine feature engineering steps with modeling steps using a pipeline object.
# packages used
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
# Pipeline object to chain together modeling processes
model = make_pipeline(preprocessor, LogisticRegression(max_iter=500))
model
# fit our model
_ = model.fit(X_train, y_train)
# score on test set
model.score(X_test, y_test)
0.8502170174432888
Resampling & cross-validation#
In lesson 7b we split our data into training and testing sets and we assessed the performance of our model on the test set. Unfortunately, there are a few pitfalls to this approach:
If our dataset is small, a single test set may not provide realistic expectations of our model’s performance on unseen data.
A single test set does not provide us any insight on variability of our model’s performance.
Using our test set to drive our model building process can bias our results via data leakage.
Resampling methods provide an alternative approach by allowing us to repeatedly fit a model of interest to parts of the training data and test its performance on other parts of the training data.

Fig. 22 Illustration of resampling.#
Note
This allows us to train and validate our model entirely on the training data and not touch the test data until we have selected a final “optimal” model.
The two most commonly used resampling methods include k-fold cross-validation and bootstrap sampling. This lesson focuses on using k-fold cross-validation.
K-fold cross-validation#
Cross-validation consists of repeating the procedure such that the training and testing sets are different each time. Generalization performance metrics are collected for each repetition and then aggregated. As a result we can get an estimate of the variability of the model’s generalization performance.
k-fold cross-validation (aka k-fold CV) is a resampling method that randomly divides the training data into k groups (aka folds) of approximately equal size.
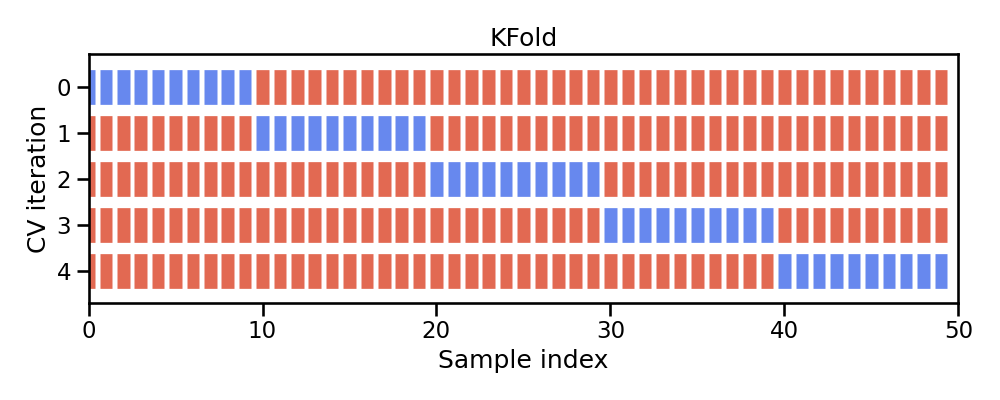
Fig. 23 Illustration of k-fold sampling across a data sets index.#
The model is fit on \(k-1\) folds and then the remaining fold is used to compute model performance. This procedure is repeated k times; each time, a different fold is treated as the validation set.
This process results in k estimates of the generalization error (say \(\epsilon_1, \epsilon_2, \dots, \epsilon_k\)). Thus, the k-fold CV estimate is computed by averaging the k test errors, providing us with an approximation of the error we might expect on unseen data.

Fig. 24 Illustration of a 5-fold cross validation procedure.#
In scikit-learn, the function cross_validate allows us to perform cross-validation and you need to pass it the model, the data, and the target. Since there exists several cross-validation strategies, cross_validate takes a parameter cv which defines the splitting strategy.
Tip
In practice, one typically uses k=5 or k=10. There is no formal rule as to the size of k; however, as k gets larger, the difference between the estimated performance and the true performance to be seen on the test set will decrease.
%%time
from sklearn.model_selection import cross_validate
cv_result = cross_validate(model, X_train, y_train, cv=5)
cv_result
CPU times: user 1.11 s, sys: 31.3 ms, total: 1.15 s
Wall time: 1.15 s
{'fit_time': array([0.19941282, 0.20152712, 0.20312715, 0.18794799, 0.19561172]),
'score_time': array([0.02464485, 0.02264285, 0.02281284, 0.0229888 , 0.0230484 ]),
'test_score': array([0.85246349, 0.84575485, 0.85790336, 0.85066885, 0.85544636])}
The output of cross_validate is a Python dictionary, which by default contains three entries:
fit_time: the time to train the model on the training data for each fold,score_time: the time to predict with the model on the testing data for each fold, andtest_score: the default score on the testing data for each fold.
scores = cv_result["test_score"]
print("The mean cross-validation accuracy is: "
f"{scores.mean():.3f} +/- {scores.std():.3f}")
The mean cross-validation accuracy is: 0.852 +/- 0.004
Knowledge check#
Question:
Using KNeighborsClassifier(), run a 5 fold cross validation procedure and compare the accuracy and standard deviation to the LogisticRegression model we just ran. Which model has a better CV score?
Evaluation metrics#
Evaluation metrics allow us to measure the predictive accuracy of our model – the difference between the predicted value (\(\hat{y}_i\)) and the actual value (\(y_i\)).
We often refer to evaluation metrics as loss functions: \(f(y_{i} - \hat{y}_i)\)
Scikit-Learn provides multiple ways to compute evaluation metrics and refers to this concept as scoring.
Estimator scoring method
Individual scoring functions
Scoring parameters
Estimator scoring method#
Every estimator (regression/classification model) has a default scoring method. Most classifiers return the mean accuracy of the model on the supplied \(X\) and \(y\):
# toy data
from sklearn.datasets import load_breast_cancer
X_cancer, y_cancer = load_breast_cancer(return_X_y=True)
# fit model
clf = LogisticRegression(solver='liblinear').fit(X_cancer, y_cancer)
# score
clf.score(X_cancer, y_cancer)
0.9595782073813708
While most regressors return the \(R^2\) metric:
# toy data
from sklearn.datasets import load_diabetes
X_diabetes, y_diabetes = load_diabetes(return_X_y=True)
# fit model
from sklearn.linear_model import LinearRegression
reg = LinearRegression().fit(X_diabetes, y_diabetes)
# score
reg.score(X_diabetes, y_diabetes)
0.5177484222203499
Individual scoring functions#
However, these default evaluation metrics are often not the metrics most suitable to the business problem.
There are many loss functions to choose from; each with unique characteristics that can be beneficial for certain problems.
Regression problems
Mean squared error (MSE)
Root mean squared error (RMSE)
Mean absolute error (MAE)
etc.
Classification problems
Area under the curve (AUC)
Cross-entropy (aka Log loss)
Precision
etc.
Scikit-Learn provides many scoring functions to choose from.
from sklearn import metrics
The functions take actual y values and predicted y values – \(f(y_{i} - \hat{y}_i)\)
Example regression metrics:
y_pred = reg.predict(X_diabetes)
# Mean squared error
metrics.mean_squared_error(y_diabetes, y_pred)
np.float64(2859.69634758675)
# Mean absolute percentage error
metrics.mean_absolute_percentage_error(y_diabetes, y_pred)
np.float64(0.38786179217948247)
Example classification metrics:
y_pred = clf.predict(X_cancer)
# Area under the curve
metrics.roc_auc_score(y_cancer, y_pred)
np.float64(0.9543760900586651)
# F1 score
metrics.f1_score(y_cancer, y_pred)
np.float64(0.9680111265646731)
# multiple metrics at once!
print(metrics.classification_report(y_cancer, y_pred))
precision recall f1-score support
0 0.96 0.93 0.95 212
1 0.96 0.97 0.97 357
accuracy 0.96 569
macro avg 0.96 0.95 0.96 569
weighted avg 0.96 0.96 0.96 569
Scoring parameters#
And since we prefer to use cross-validation procedures, scikit-learn has incorporated a scoring parameter.
Most evaluation metrics have a predefined text string that can be supplied as a scoring argument.
# say we wanted to use AUC as our loss function while using 5-fold validation
cross_validate(model, X_train, y_train, cv=5, scoring='roc_auc')
{'fit_time': array([0.19924974, 0.20708108, 0.20136404, 0.19078708, 0.19706917]),
'score_time': array([0.02401733, 0.02259088, 0.023875 , 0.02283025, 0.02323818]),
'test_score': array([0.90490722, 0.90316435, 0.91314045, 0.90543753, 0.90815237])}
Note
The unified scoring API in scikit-learn always maximizes the score, so metrics which need to be minimized are negated in order for the unified scoring API to work correctly. Consequently, some metrics such as mean_squared_error() will use a predefined text string starting with neg_ (i.e. ‘neg_mean_squared_error’).
# applying mean squared error in a regression k-fold cross validation procedure
cross_validate(reg, X_diabetes, y_diabetes, cv=5, scoring='neg_root_mean_squared_error')
{'fit_time': array([0.00118995, 0.00080609, 0.00054407, 0.00054383, 0.00054216]),
'score_time': array([0.00039816, 0.00034213, 0.00033879, 0.00033212, 0.00033379]),
'test_score': array([-52.72497937, -55.03486476, -56.90068179, -54.85204179,
-53.94638716])}
You can even supply more than one metric or even define your own custom metric.
# example of supplying more than one metric
metrics = ['accuracy', 'roc_auc']
cross_validate(model, X_train, y_train, cv=5, scoring=metrics)
{'fit_time': array([0.20004487, 0.20231795, 0.20330286, 0.18838501, 0.19563699]),
'score_time': array([0.04691601, 0.04512501, 0.04600811, 0.04538178, 0.04471207]),
'test_accuracy': array([0.85246349, 0.84575485, 0.85790336, 0.85066885, 0.85544636]),
'test_roc_auc': array([0.90490722, 0.90316435, 0.91314045, 0.90543753, 0.90815237])}
Knowledge check#
Questions:
Using the KNeighborsClassifier() from the previous Knowledge check exercise, perform a 5 fold cross validation and compute the accuracy and ROC AUC.
Hyperparameter tuning#
Given two different models (blue line) to the same data (gray dots), which model do you prefer?
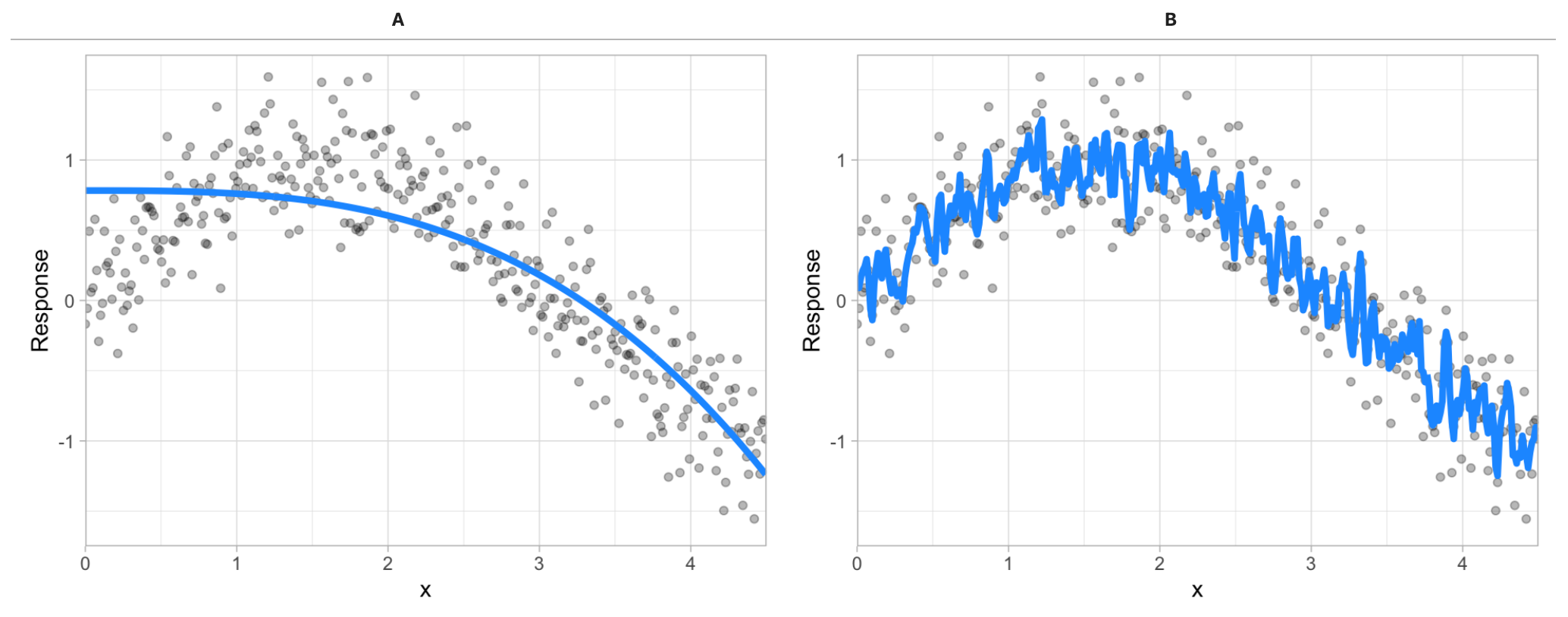
Fig. 25 Between model A and B, which do you think is better?#
The image above illustrates the fact that prediction errors can be decomposed into two main subcomponents we care about:
error due to “bias”
error due to “variance”
Bias#
Error due to bias is the difference between the expected (or average) prediction of our model and the correct value which we are trying to predict.
It measures how far off in general a model’s predictions are from the correct value, which provides a sense of how well a model can conform to the underlying structure of the data.
High bias models (i.e. generalized linear models) are rarely affected by the noise introduced by new unseen data
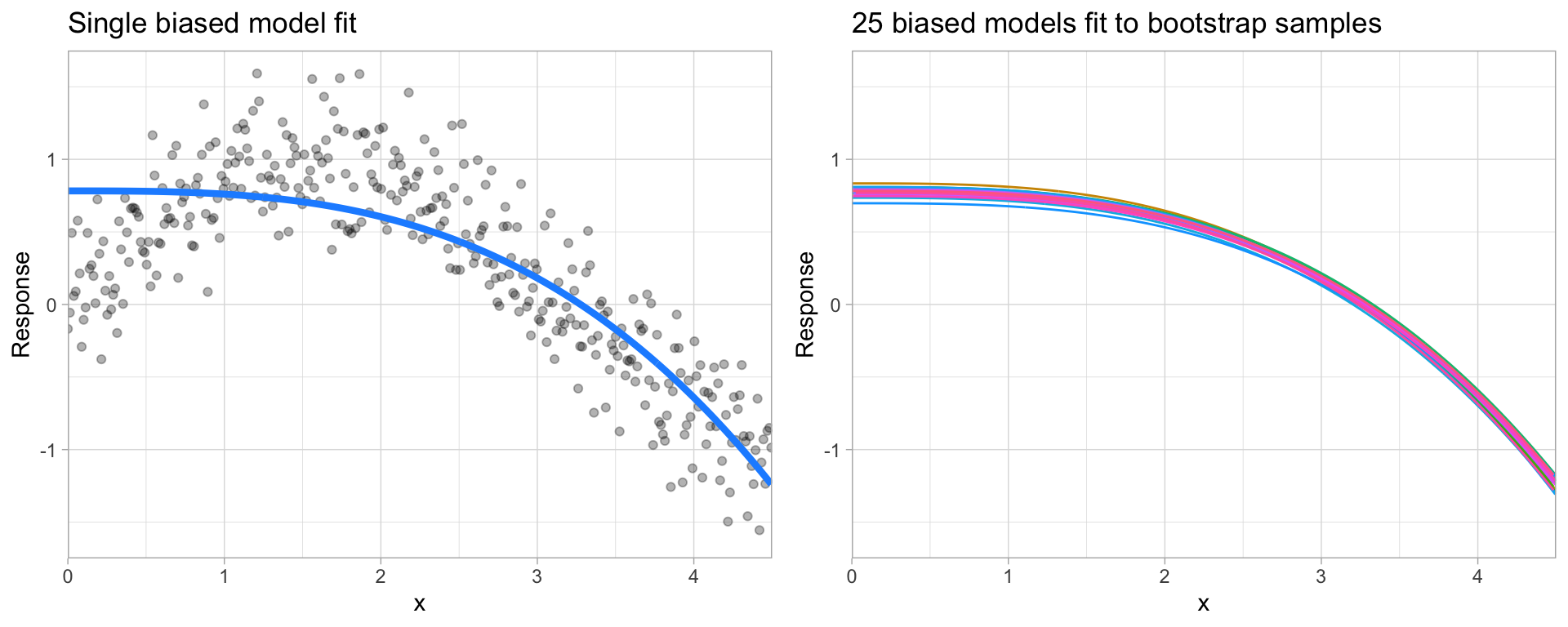
Fig. 26 A biased polynomial model fit to a single data set does not capture the underlying non-linear, non-monotonic data structure (left). Models fit to 25 bootstrapped replicates of the data are underterred by the noise and generates similar, yet still biased, predictions (right).#
Variance#
Error due to variance is the variability of a model prediction for a given data point.
Many models (e.g., k-nearest neighbor, decision trees, gradient boosting machines) are very adaptable and offer extreme flexibility in the patterns that they can fit to. However, these models offer their own problems as they run the risk of overfitting to the training data.
Although you may achieve very good performance on your training data, the model will not automatically generalize well to unseen data.
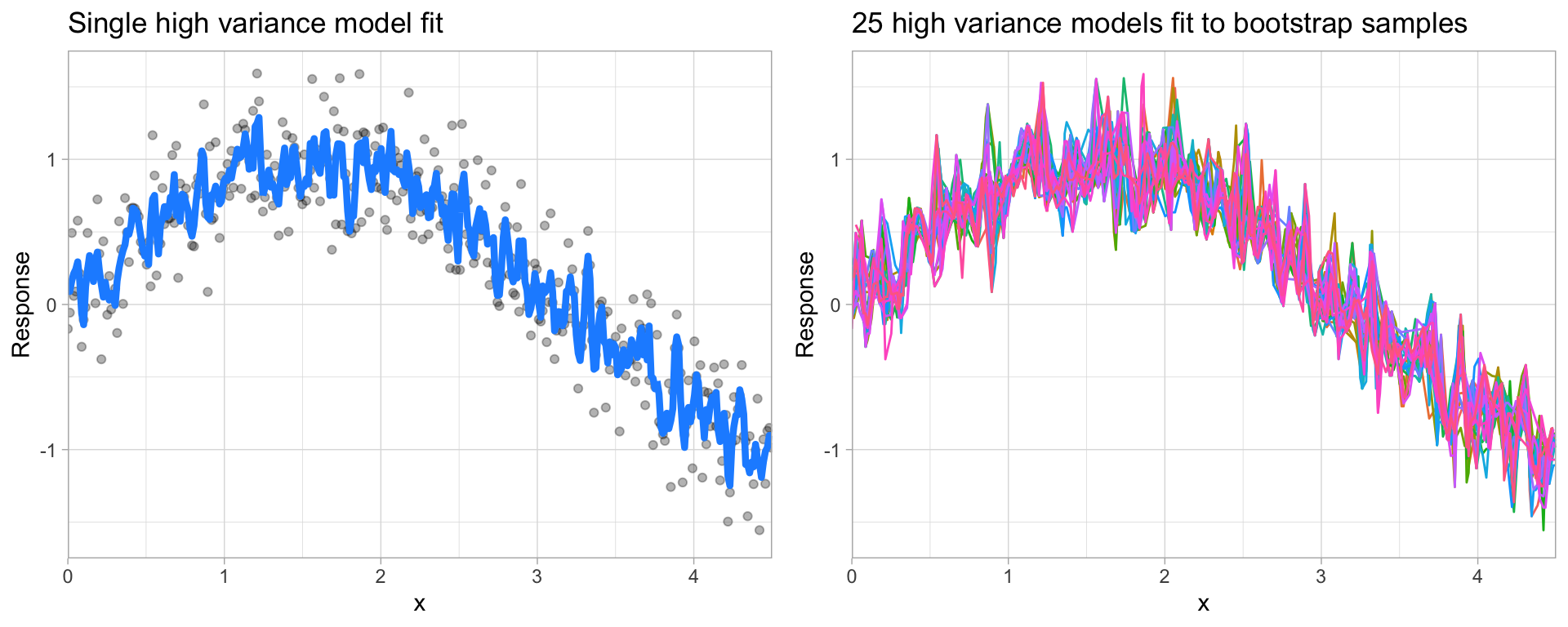
Fig. 27 A high variance k-nearest neighbor model fit to a single data set captures the underlying non-linear, non-monotonic data structure well but also overfits to individual data points (left). Models fit to 25 bootstrapped replicates of the data are deterred by the noise and generate highly variable predictions (right).#
Note
Many high performing models (i.e. random forests, gradient boosting machines, deep learning) are very flexible in the patterns they can conform to due to the many hyperparameters they have. However, this also means they are prone to overfitting (aka can have high variance error).
Hyperparameters (aka tuning parameters) are the “knobs to twiddle” to control the complexity of machine learning algorithms and, therefore, the bias-variance trade-off.
Some models have very few hyperparameters. For example in a K-nearest neighbor (KNN) model K (the number of neighbors) is the primary hyperparameter.
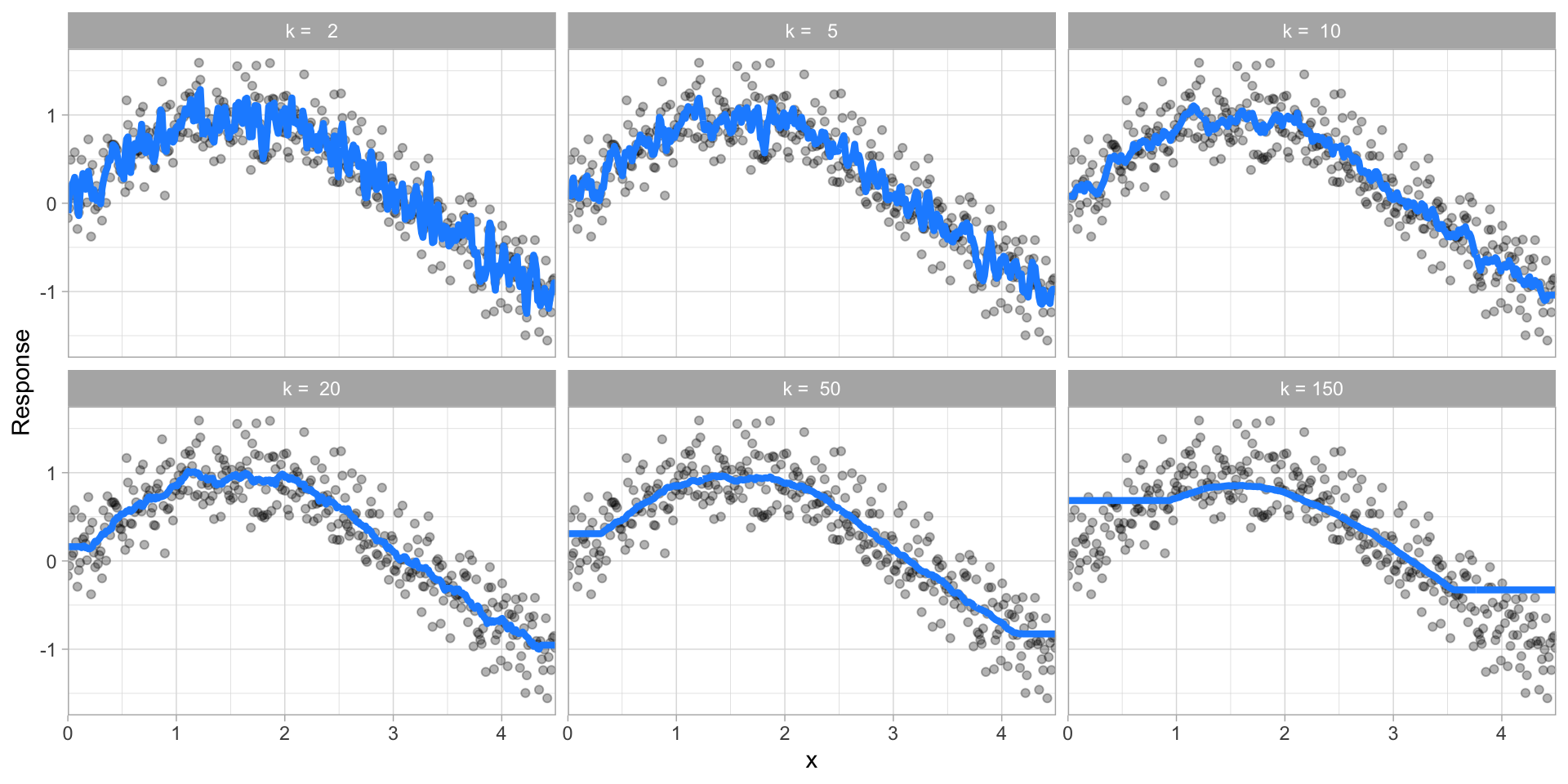
Fig. 28 k-nearest neighbor model with differing values for k.#
While other models such as gradient boosted machines (GBMs) and deep learning models can have many.
Hyperparameter tuning is the process of screening hyperparameter values (or combinations of hyperparameter values) to find a model that balances bias & variance so that the model generalizes well to unseen data.
%%time
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
# set hyperparameter in KNN model
model = KNeighborsClassifier(n_neighbors=10)
# create preprocessor & modeling pipeline
pipeline = make_pipeline(preprocessor, model)
# 5-fold cross validation using AUC error metric
results = cross_val_score(pipeline, X_train, y_train, cv=5, scoring='roc_auc')
print(f'KNN model with 10 neighbors: AUC = {np.mean(results):.3f}')
KNN model with 10 neighbors: AUC = 0.883
CPU times: user 35.3 s, sys: 7.6 s, total: 42.9 s
Wall time: 43 s
But what if we wanted to assess and compare n_neighbors = 5, 10, 15, 20, … ?
Full cartesian grid search#
For this we could use a full cartesian grid search using Scikit-Learn’s GridSearchCV():
%%time
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
# basic model object
knn = KNeighborsClassifier()
# Create grid of hyperparameter values
hyper_grid = {'knn__n_neighbors': [5, 10, 15, 20]}
# create preprocessor & modeling pipeline
pipeline = Pipeline([('prep', preprocessor), ('knn', knn)])
# Tune a knn model using grid search
grid_search = GridSearchCV(pipeline, hyper_grid, cv=5, scoring='roc_auc', n_jobs=-1)
results = grid_search.fit(X_train, y_train)
# Best model's cross validated AUC
abs(results.best_score_)
CPU times: user 1.12 s, sys: 903 ms, total: 2.02 s
Wall time: 3min 16s
np.float64(0.8937293441147304)
Tip
We use Pipeline rather than make_pipeline in the above because it allows us to name the different steps in the pipeline. This allows us to assign hyperparameters to distinct steps within the pipeline.
results.best_params_
{'knn__n_neighbors': 20}
Random search#
However, a cartesian grid-search approach has limitations.
It does not scale well when the number of parameters to tune is increasing.
It also forces regularity rather than aligning values assessed to distributions.
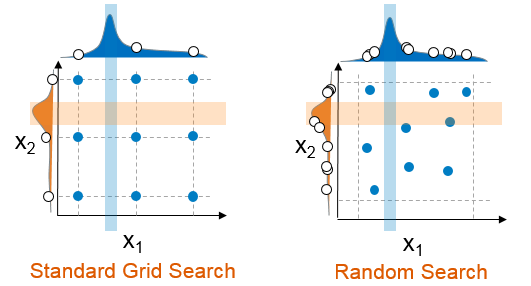
Fig. 29 Random search compared to standard grid search.#
Note
Random search based on hyperparameter distributions has proven to perform as well, if not better than, standard grid search. Learn more here.
For example, say we want to train a random forest classifier. Random forests are very flexible algorithms and can have several hyperparameters.
from sklearn.ensemble import RandomForestClassifier
# basic model object
rf = RandomForestClassifier(random_state=123)
# create preprocessor & modeling pipeline
pipeline = Pipeline([('prep', preprocessor), ('rf', rf)])
For this particular random forest algorithm we’ll assess the following hyperparameters. Don’t worry if you are not familiar with what these do.
n_estimators: number of trees in the forest,max_features: number of features to consider when looking for the best split,max_depth: maximum depth of each tree built,min_samples_leaf: minimum number of samples required in a leaf node,max_samples: number of samples to draw from our training data to train each tree.
A standard grid search would be very computationally intense.
Instead, we’ll use a random latin hypercube search using RandomizedSearchCV.
To build our grid, we need to specify distributions for our hyperparameters.
Tip
scipy.stats.loguniform can be used to generate floating numbers. To generate random values for integer-valued parameters (e.g. min_samples_leaf) we can adapt is as follows:
from scipy.stats import loguniform
class loguniform_int:
"""Integer valued version of the log-uniform distribution"""
def __init__(self, a, b):
self._distribution = loguniform(a, b)
def rvs(self, *args, **kwargs):
"""Random variable sample"""
return self._distribution.rvs(*args, **kwargs).astype(int)
# specify hyperparameter distributions to randomly sample from
param_distributions = {
'rf__n_estimators': loguniform_int(50, 1000),
'rf__max_features': loguniform(.1, .5),
'rf__max_depth': loguniform_int(4, 20),
'rf__min_samples_leaf': loguniform_int(1, 100),
'rf__max_samples': loguniform(.5, 1),
}
Now, we can define the randomized search using the different distributions.
Executing 10 iterations of 5-fold cross-validation for random parametrizations of this model on this dataset can take from 10 seconds to several minutes, depending on the speed of the host computer and the number of available processors.
%%time
from sklearn.model_selection import RandomizedSearchCV
# perform 10 random iterations
random_search = RandomizedSearchCV(
pipeline,
param_distributions=param_distributions,
n_iter=10,
cv=5,
scoring='roc_auc',
verbose=1,
n_jobs=-1,
)
results = random_search.fit(X_train, y_train)
Fitting 5 folds for each of 10 candidates, totalling 50 fits
CPU times: user 42.2 s, sys: 269 ms, total: 42.4 s
Wall time: 2min 19s
results.best_score_
np.float64(0.9142964217793036)
results.best_params_
{'rf__max_depth': np.int64(17),
'rf__max_features': np.float64(0.22731675151933078),
'rf__max_samples': np.float64(0.7340381117847631),
'rf__min_samples_leaf': np.int64(21),
'rf__n_estimators': np.int64(460)}
Exercises#
Questions:
Import the dataset blood_transfusion.csv:
The column “Class” contains the target variable. Investigate this variable. Is this a regression or classification problem?
Why is it relevant to add a preprocessing step to scale the data using a
StandardScalerwhen working with aKNeighborsClassifier?Create a scikit-learn pipeline (using
sklearn.pipeline.make_pipeline) where aStandardScalerwill be used to scale the data followed by aKNeighborsClassifier. Use the default hyperparameters. Inspect the parameters of the created pipeline. What is the value of K, the number of neighbors considered when predicting with the k-nearest neighbors?Perform a 5-fold cross validation with the pipeline you created in #3. What is your average CV score?
Now perform hyperparameter tuning to understand the effect of the parameter
n_neighborson the model score. Use the following values for the parameter range. Again, perform a 5-fold cross validation. Which hyperparameter value performed the best and what was the CV score?param_range = [1, 2, 5, 10, 20, 50, 100, 200, 500]
Computing environment#
%load_ext watermark
%watermark -v -p jupyterlab,pandas,sklearn
Python implementation: CPython
Python version : 3.12.4
IPython version : 8.26.0
jupyterlab: 4.2.3
pandas : 2.2.2
sklearn : 1.5.1