Lesson 3a: Subsetting data#
“Every second of every day, our senses bring in way too much data than we can possibly process in our brains.”
- Peter Diamandis, Founder of the X-Prize for human-AI collaboration
When performing data analysis tasks, rarely do we want to use all our data. Often, we want to focus in on specific variables of interest and/or observations of interest. This requires us to be able to subset our DataFrame in various ways, which is the emphasis of this lesson.
Learning objectives#
By the end of this lesson you’ll be able to:
Differentiate between the different ways to subset DataFrames.
Select columns of a DataFrame.
Slice and filter specific rows of a DataFrame.
Prerequisites#
To illustrate selecting and filtering let’s go ahead and load the pandas library and import some data:
import pandas as pd
planes_df = pd.read_csv('../data/planes.csv')
planes_df.head()
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 1 | N102UW | 1998.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 2 | N103US | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 3 | N104UW | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 4 | N10575 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145LR | 2 | 55 | NaN | Turbo-fan |
Subsetting dimensions#
Video 🎥:
We don’t always want all of the data in a DataFrame, so we need to take subsets of the DataFrame. In general, subsetting is extracting a small portion of a DataFrame – making the DataFrame smaller. Since the DataFrame is two-dimensional, there are two dimensions on which to subset.
Dimension 1: We may only want to consider certain variables. For example, we may only care about the year and engines variables:

We call this selecting columns/variables – this is similar to SQL’s SELECT or R’s dplyr package’s select().
Dimension 2: We may only want to consider certain cases. For example, we may only care about the cases where the manufacturer is Embraer.

We call this filtering or slicing – this is similar to SQL’s WHERE or R’s dplyr package’s filter() or slice(). And we can combine these two options to subset in both dimensions – the year and engines variables where the manufacturer is Embraer:

In the previous example, we want to do two things using planes_df:
select the
yearandenginesvariablesfilter to cases where the manufacturer is Embraer
But we also want to return a new DataFrame – not just highlight certain cells. In other words, we want to turn this:
Show code cell source
planes_df.head()
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 1 | N102UW | 1998.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 2 | N103US | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 3 | N104UW | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 4 | N10575 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145LR | 2 | 55 | NaN | Turbo-fan |
Into this:
Show code cell source
planes_df.head().loc[planes_df['manufacturer'] == 'EMBRAER', ['year', 'engines']]
| year | engines | |
|---|---|---|
| 0 | 2004.0 | 2 |
| 4 | 2002.0 | 2 |
So we really have a third need: return the resulting DataFrame so we can continue our analysis:
select the
yearandenginesvariablesfilter to cases where the manufacturer is Embraer
Return a DataFrame to continue the analysis
Subsetting variables#
Recall that the subsetting of variables/columns is called selecting variables/columns. In a simple example, we can select a single variable using bracket subsetting notation:
planes_df['year'].head()
0 2004.0
1 1998.0
2 1999.0
3 1999.0
4 2002.0
Name: year, dtype: float64
Notice the head() method also works on planes_df['year'] to return the first five elements.
Question:
What is the data type of planes_df['year']?
This returns pandas.core.series.Series, referred to simply as a “Series”, rather than a DataFrame.
type(planes_df['year'])
pandas.core.series.Series
This is okay – the Series is a popular data structure in Python. Recall from a previous lesson:
A Series is a one-dimensional data structure – this is similar to a Python
listNote that all objects in a Series are usually of the same type (but this isn’t a strict requirement)
Each DataFrame can be thought of as a list of equal-length Series (plus an Index)
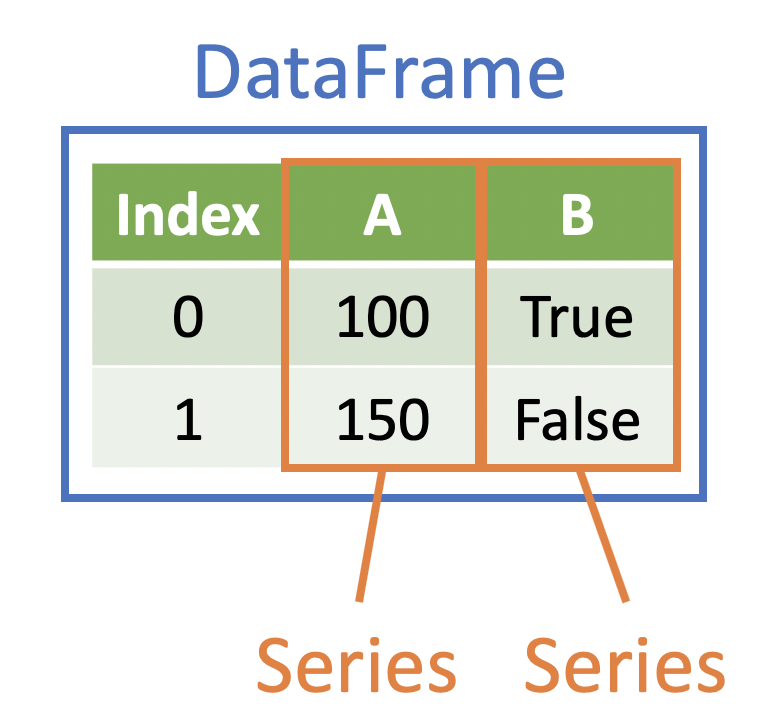
Series can be useful, but for now, we are interested in returning a DataFrame rather than a series. We can select a single variable and return a DataFrame by still using bracket subsetting notation, but this time we will pass a list of variables names:
planes_df[['year']].head()
| year | |
|---|---|
| 0 | 2004.0 |
| 1 | 1998.0 |
| 2 | 1999.0 |
| 3 | 1999.0 |
| 4 | 2002.0 |
And we can see that we’ve returned a DataFrame:
type(planes_df[['year']].head())
pandas.core.frame.DataFrame
Question:
What’s another advantage of this passing a list?
Passing a list into the bracket subsetting notation allows us to select multiple variables at once:
planes_df[['year', 'engines']].head()
| year | engines | |
|---|---|---|
| 0 | 2004.0 | 2 |
| 1 | 1998.0 | 2 |
| 2 | 1999.0 | 2 |
| 3 | 1999.0 | 2 |
| 4 | 2002.0 | 2 |
In another example, assume we are interested in the model of plane, number of seats and engine type:
planes_df[['model', 'seats', 'engine']].head()
| model | seats | engine | |
|---|---|---|---|
| 0 | EMB-145XR | 55 | Turbo-fan |
| 1 | A320-214 | 182 | Turbo-fan |
| 2 | A320-214 | 182 | Turbo-fan |
| 3 | A320-214 | 182 | Turbo-fan |
| 4 | EMB-145LR | 55 | Turbo-fan |
Knowledge check#
Questions:
______ is a common term for subsetting DataFrame variables.
What type of object is a DataFrame column?
What will be returned by the following code?
planes_df['type', 'model']
Video 🎥:
Subsetting rows#
When we subset rows (aka cases, records, observations) we primarily use two names: slicing and filtering, but these are not the same:
slicing, similar to row indexing, subsets observations by the value of the Index
filtering subsets observations using a conditional test
Slicing rows#
Remember that all DataFrames have an Index:
planes_df.head()
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 1 | N102UW | 1998.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 2 | N103US | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 3 | N104UW | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 4 | N10575 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145LR | 2 | 55 | NaN | Turbo-fan |
We can slice cases/rows using the values in the Index and bracket subsetting notation. It’s common practice to use .loc to slice cases/rows:
planes_df.loc[0:5]
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 1 | N102UW | 1998.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 2 | N103US | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 3 | N104UW | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 4 | N10575 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145LR | 2 | 55 | NaN | Turbo-fan |
| 5 | N105UW | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
Note
Note that since this is not “indexing”, the last element is inclusive.
We can also pass a list of Index values:
planes_df.loc[[0, 2, 4, 6, 8]]
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 2 | N103US | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 4 | N10575 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145LR | 2 | 55 | NaN | Turbo-fan |
| 6 | N107US | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 8 | N109UW | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
Filtering rows#
We can filter rows using a logical sequence equal in length to the number of rows in the DataFrame.
Continuing our example, assume we want to determine whether each case’s manufacturer is Embraer. We can use the manufacturer Series and a logical equivalency test to find the result for each row:
planes_df['manufacturer'] == 'EMBRAER'
0 True
1 False
2 False
3 False
4 True
...
3317 False
3318 False
3319 False
3320 False
3321 False
Name: manufacturer, Length: 3322, dtype: bool
We can use this resulting logical sequence to test filter cases – rows that are True will be returned while those that are False will be removed:
planes_df[planes_df['manufacturer'] == 'EMBRAER'].head()
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 4 | N10575 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145LR | 2 | 55 | NaN | Turbo-fan |
| 10 | N11106 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 11 | N11107 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 12 | N11109 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
This also works with .loc:
planes_df.loc[planes_df['manufacturer'] == 'EMBRAER'].head()
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 4 | N10575 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145LR | 2 | 55 | NaN | Turbo-fan |
| 10 | N11106 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 11 | N11107 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 12 | N11109 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
Any conditional test can be used to filter DataFrame rows:
planes_df.loc[planes_df['year'] > 2002].head()
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 15 | N11121 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 16 | N11127 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 17 | N11137 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 18 | N11140 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
And multiple conditional tests can be combined using logical operators:
planes_df.loc[(planes_df['year'] > 2002) & (planes_df['year'] < 2004)].head()
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 15 | N11121 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 16 | N11127 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 17 | N11137 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 18 | N11140 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 19 | N11150 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
Note
Note that each condition is wrapped in parentheses – this is required.
Often, as your condition gets more complex, it can be easier to read if you separate out the condition:
cond = (planes_df['year'] > 2002) & (planes_df['year'] < 2004)
planes_df.loc[cond].head()
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 15 | N11121 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 16 | N11127 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 17 | N11137 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 18 | N11140 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 19 | N11150 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
Knowledge check#
Questions:
What’s the difference between slicing cases and filtering cases?
Fill in the blanks to fix the following code to find planes that have more than three engines:
planes_df.loc[______['______'] > 3]
Video 🎥:
Selecting variables and filtering rows#
If we want to select variables and filter cases at the same time, we have a few options:
Sequential operations
Simultaneous operations
Sequential Operations#
We can use what we’ve previously learned to select variables and filter cases in multiple steps:
planes_df_filtered = planes_df.loc[planes_df['manufacturer'] == 'EMBRAER']
planes_df_filtered_and_selected = planes_df_filtered[['year', 'engines']]
planes_df_filtered_and_selected.head()
| year | engines | |
|---|---|---|
| 0 | 2004.0 | 2 |
| 4 | 2002.0 | 2 |
| 10 | 2002.0 | 2 |
| 11 | 2002.0 | 2 |
| 12 | 2002.0 | 2 |
This is a good way to learn how to select and filter independently, and it also reads very clearly.
Simultaneous operations#
However, we can also do both selecting and filtering in a single step with .loc:
planes_df.loc[planes_df['manufacturer'] == 'EMBRAER', ['year', 'engines']].head()
| year | engines | |
|---|---|---|
| 0 | 2004.0 | 2 |
| 4 | 2002.0 | 2 |
| 10 | 2002.0 | 2 |
| 11 | 2002.0 | 2 |
| 12 | 2002.0 | 2 |
This option is more succinct and also reduces programming time. As before, as your filtering and selecting conditions get longer and/or more complex, it can make it easier to read to break it up into separate lines:
rows = planes_df['manufacturer'] == 'EMBRAER'
cols = ['year', 'engines']
planes_df.loc[rows, cols].head()
| year | engines | |
|---|---|---|
| 0 | 2004.0 | 2 |
| 4 | 2002.0 | 2 |
| 10 | 2002.0 | 2 |
| 11 | 2002.0 | 2 |
| 12 | 2002.0 | 2 |
Knowledge check#
Question:
Subset planes_df to only include planes made by Boeing and the seats and model variables.
Video 🎥:
Views vs copies#
One thing to be aware of, as you will likely experience it eventually, is the concept of returning a view (“looking” at a part of an existing object) versus a copy (making a new copy of the object in memory). This can be a bit abstract and even this section in the Pandas docs states “…it’s very hard to predict whether it will return a view or a copy.”
Tip
The concept of views and copies is confusing and you can read more about it here.
The main takeaway is that the most common warning you’ll encounter in Pandas is the SettingWithCopyWarning; Pandas raises it as a warning that you might not be doing what you think you’re doing or because the operation you are performing may behave unpredictably.
Let’s look at an example. Say the number of seats on this particular plane was recorded incorrectly. Instead of 55 seats it should actually be 60 seats.
tailnum_of_interest = planes_df['tailnum'] == 'N10156'
planes_df[tailnum_of_interest]
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
Instead of using .iloc, we could actually filter and select this element in our DataFrame with the following bracket notation.
planes_df[tailnum_of_interest]['seats']
0 55
Name: seats, dtype: int64
If we use this approach to then assign our new value to this element we’ll get a SettingWithCopyWarning.
planes_df[tailnum_of_interest]['seats'] = 60
/var/folders/8f/c06lv6q17tjbyjv2nkt0_s4s1sh0tg/T/ipykernel_27954/2190037627.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
planes_df[tailnum_of_interest]['seats'] = 60
So what’s going on? Did our DataFrame get changed?
planes_df[tailnum_of_interest]
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
No it didn’t, even though you probably thought it did. What happened above is that planes_df[tailnum_of_interest]['seats'] was executed first and returned a copy of the DataFrame, which is an entirely different object. We can confirm by using id():
print(f"The id of the original dataframe is: {id(planes_df)}")
print(f" The id of the indexed dataframe is: {id(planes_df[tailnum_of_interest])}")
The id of the original dataframe is: 4546903744
The id of the indexed dataframe is: 4552837984
We then tried to set a value on this new object by appending ['seats'] = 60. Pandas is warning us that we are doing that operation on a copy of the original dataframe, which is probably not what we want. To fix this, you need to index in a single go, using .loc[] for example:
planes_df.loc[tailnum_of_interest, 'seats'] = 60
No error this time! And let’s confirm the change:
planes_df[tailnum_of_interest]
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 60 | NaN | Turbo-fan |
Tip
When in doubt, always use .loc[] for combined filtering and selecting!
Exercises#
Questions:
Import the heart.csv
Select the age column and return a Series. Select the age column and return a DataFrame. Select the age, sex, and max_hr columns.
Slice the DataFrame to get the first 25 rows and save as
first_25. What is the age of the last observation in this sliced DataFrame?Using the original DataFrame (not the sliced DataFrame), filter for all observations where the person is 50 years or older. How many observations are there?
Using the original DataFrame, filter for those observations that are male and 50 years or older. How many observations are there.
Using the original DataFrame, filter for those observations that are female, 50 years or younger, and have the disease (disease = 1). Select
chest_pain,chol, andmax_hrcolumns. How many rows and columns are in the resulting DataFrame?
Computing environment#
Show code cell source
%load_ext watermark
%watermark -v -p jupyterlab,pandas
Python implementation: CPython
Python version : 3.12.4
IPython version : 8.26.0
jupyterlab: 4.2.3
pandas : 2.2.2