27 Lesson 7b: Feature engineering
Data preprocessing and engineering techniques generally refer to the addition, deletion, or transformation of data. In this lesson we introduce you to another tidymodels package, recipes, which is designed to help you preprocess your data before training your model. Recipes are built as a series of preprocessing steps, such as:
- converting qualitative predictors to indicator variables (also known as dummy variables),
- transforming data to be on a different scale (e.g., taking the logarithm of a variable),
- transforming whole groups of predictors together, extracting key features from raw variables (e.g., getting the day of the week out of a date variable),
and so on. Although there is an ever-growing number of ways to preprocess your data, we’ll focus on a few common feature engineering steps applied to numeric and categorical data. This will provide you with a foundation of how to perform feature engineering.
27.1 Learning objectives
By the end of this lesson you’ll be able to:
- Explain how to apply feature engineering steps with the recipes package.
- Filter out low informative features.
- Normalize and standardize numeric features.
- Pre-process nominal and ordinal features.
- Combine multiple feature engineering steps into one recipe and train a model with it.
27.2 Prerequisites
For this lesson we’ll use the recipes package with is automatically loaded with tidymodels and we’ll use the ames housing data.
Let’s go ahead and create our train-test split:
27.3 Create a recipe
To get started, let’s create a model recipe that we will build upon and apply in a model downstream. Before training the model, we can use a recipe to create and/or modify predictors and conduct some preprocessing required by the model.
Now we can start adding steps onto our recipe using the pipe operator and applying specific feature engineering tasks. The sections that follow provide some discussion as to why we apply each feature engineering step and then we demonstrate how to add it to our recipe.
27.4 Feature filtering
In many data analyses and modeling projects we end up with hundreds or even thousands of collected features. From a practical perspective, a model with more features often becomes harder to interpret and is costly to compute. Some models are more resistant to non-informative predictors (e.g., the Lasso and tree-based methods) than others.
Although the performance of some of our models are not significantly affected by non-informative predictors, the time to train these models can be negatively impacted as more features are added. Consequently, filtering or reducing features prior to modeling may significantly speed up training time.
Zero and near-zero variance variables are low-hanging fruit to eliminate. Zero variance variables, meaning the feature only contains a single unique value, provides no useful information to a model. Some algorithms are unaffected by zero variance features. However, features that have near-zero variance also offer very little, if any, information to a model. Furthermore, they can cause problems during resampling as there is a high probability that a given sample will only contain a single unique value (the dominant value) for that feature.
A rule of thumb for detecting near-zero variance features are identifying and removing features with \(\leq 5-10\)% variance.
For the Ames data, we do not have any zero variance predictors but there are many features that meet the near-zero threshold. The following shows all features where there is less than 5% variance in distinct values.
| rowname | freqRatio | percentUnique | zeroVar | nzv |
|---|---|---|---|---|
| Street | 292.000 | 0.09751 | FALSE | TRUE |
| Alley | 23.605 | 0.14627 | FALSE | TRUE |
| Utilities | 2049.000 | 0.14627 | FALSE | TRUE |
| Land_Slope | 22.182 | 0.14627 | FALSE | TRUE |
| Land_Contour | 21.453 | 0.19503 | FALSE | TRUE |
| Kitchen_AbvGr | 21.250 | 0.19503 | FALSE | TRUE |
| Pool_QC | 680.667 | 0.24378 | FALSE | TRUE |
| Roof_Matl | 144.643 | 0.29254 | FALSE | TRUE |
| Bsmt_Cond | 20.761 | 0.29254 | FALSE | TRUE |
| Heating | 100.900 | 0.29254 | FALSE | TRUE |
| Misc_Feature | 27.403 | 0.29254 | FALSE | TRUE |
| BsmtFin_Type_2 | 25.779 | 0.34130 | FALSE | TRUE |
| Condition_2 | 202.700 | 0.39005 | FALSE | TRUE |
| Functional | 39.729 | 0.39005 | FALSE | TRUE |
| Pool_Area | 2042.000 | 0.48757 | FALSE | TRUE |
| Three_season_porch | 675.333 | 0.97513 | FALSE | TRUE |
| Low_Qual_Fin_SF | 504.500 | 1.41394 | FALSE | TRUE |
| Misc_Val | 141.000 | 1.51146 | FALSE | TRUE |
We can filter out near-zero variance features with step_nzv(). Within step_nzv() we specify which features to apply this to. There are several helper functions to make it easy to apply the step to all_predictors(), all_numeric() variables, all_nominal() variables, and more.
See the different variable selectors here.
In this example we filter out all predictor variables that have less than 10% variance in values.
The result of the above code is not to actually apply the feature engineering steps but, rather, to create an object that holds the feature engineering logic (or recipe) to be applied later on.
27.5 Numeric features
Numeric features can create a host of problems for certain models when their distributions are skewed, contain outliers, or have a wide range in magnitudes. Tree-based models are quite immune to these types of problems in the feature space, but many other models (e.g., GLMs, regularized regression, KNN, support vector machines, neural networks) can be greatly hampered by these issues. Normalizing and standardizing heavily skewed features can help minimize these concerns.
27.5.1 Skewness
Parametric models that have distributional assumptions (e.g., GLMs, and regularized models) can benefit from minimizing the skewness of numeric features. When normalizing many variables, it’s best to use the Box-Cox (when feature values are strictly positive) or Yeo-Johnson (when feature values are not strictly positive) procedures as these methods will identify if a transformation is required and what the optimal transformation will be.
Non-parametric models are rarely affected by skewed features; however, normalizing features will not have a negative effect on these models’ performance. For example, normalizing features will only shift the optimal split points in tree-based algorithms. Consequently, when in doubt, normalize.
We can normalize our numeric predictor variables with step_YeoJohnson():
27.5.2 Standardization
We must also consider the scale on which the individual features are measured. What are the largest and smallest values across all features and do they span several orders of magnitude? Models that incorporate smooth functions of input features are sensitive to the scale of the inputs. For example, \(5X+2\) is a simple linear function of the input X, and the scale of its output depends directly on the scale of the input. Many algorithms use linear functions within their algorithms, some more obvious (e.g., GLMs and regularized regression) than others (e.g., neural networks, support vector machines, and principal components analysis). Other examples include algorithms that use distance measures such as the Euclidean distance (e.g., k nearest neighbor, k-means clustering, and hierarchical clustering).
For these models and modeling components, it is often a good idea to standardize the features. Standardizing features includes centering and scaling so that numeric variables have zero mean and unit variance, which provides a common comparable unit of measure across all the variables.
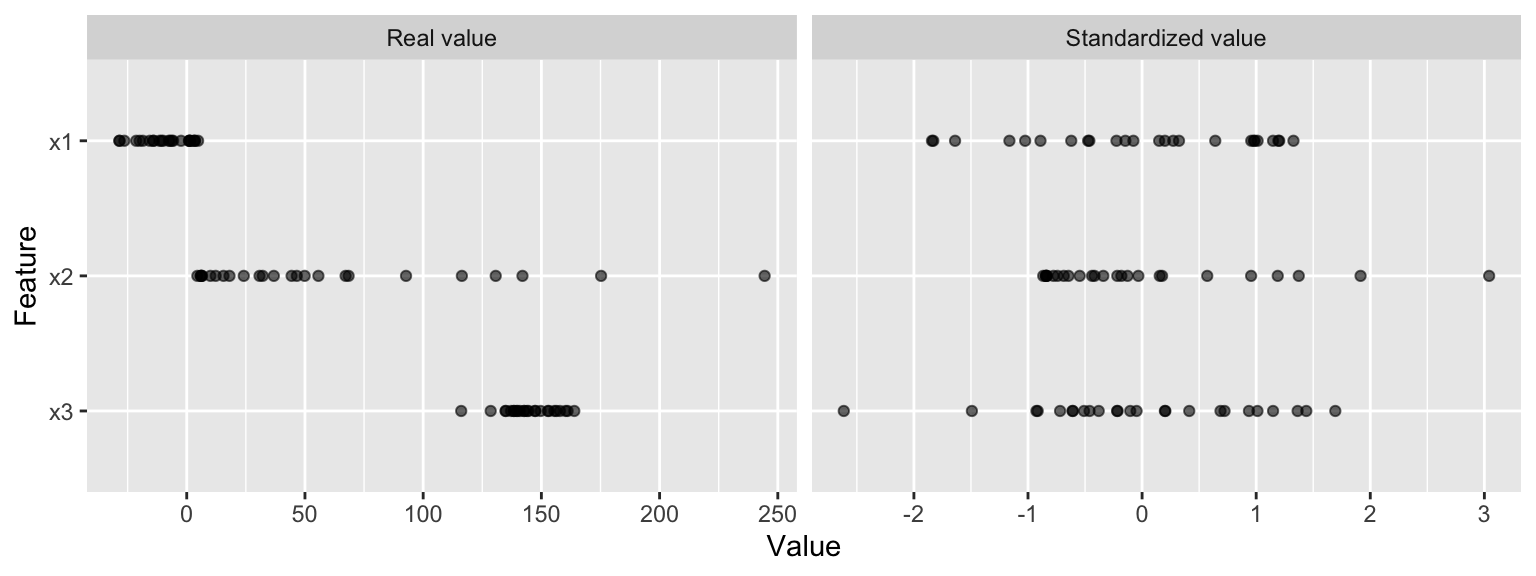
Figure 27.1: Standardizing features allows all features to be compared on a common value scale regardless of their real value differences.
We can standardize our numeric features in one of two ways – note that step_normalize() is just a wrapper that combines step_center() and step_scale().
27.6 Categorical features
Most models require that the predictors take numeric form. There are exceptions; for example, tree-based models naturally handle numeric or categorical features. However, even tree-based models can benefit from pre-processing categorical features. The following sections will discuss a few of the more common approaches to engineer categorical features.
27.6.1 One-hot & dummy encoding
There are many ways to recode categorical variables as numeric. The most common is referred to as one-hot encoding, where we transpose our categorical variables so that each level of the feature is represented as a boolean value. For example, one-hot encoding the left data frame in the below figure results in X being converted into three columns, one for each level. This is called less than full rank encoding . However, this creates perfect collinearity which causes problems with some predictive modeling algorithms (e.g., ordinary linear regression and neural networks). Alternatively, we can create a full-rank encoding by dropping one of the levels (level c has been dropped). This is referred to as dummy encoding.
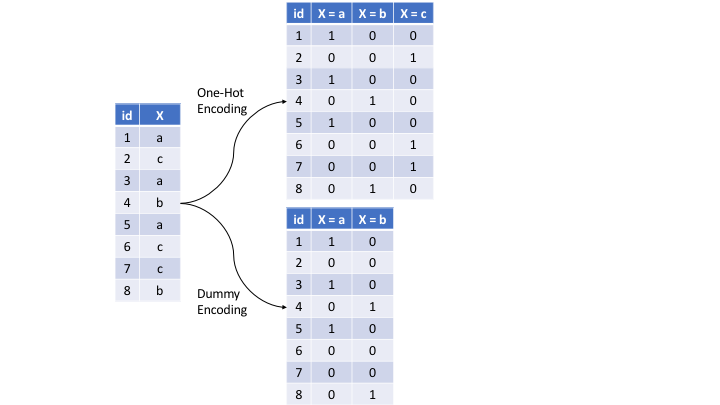
Figure 27.2: Eight observations containing a categorical feature X and the difference in how one-hot and dummy encoding transforms this feature.
We can use step_dummy() to add a one-hot or dummy encoding to our recipe:
27.6.2 Ordinal encoding
If a categorical feature is naturally ordered then numerically encoding the feature based on its order is a natural choice (most commonly referred to as ordinal encoding). For example, the various quality features in the Ames housing data are ordinal in nature (ranging from Very_Poor to Very_Excellent).
train %>% select(matches('Qual$|QC$|_Cond$'))
## # A tibble: 2,051 × 11
## Overall_Qual Overall_Cond Exter_Qual Exter_Cond Bsmt_Qual Bsmt_Cond
## <fct> <fct> <fct> <fct> <fct> <fct>
## 1 Very_Good Average Good Typical Good Good
## 2 Above_Average Average Good Typical Good Typical
## 3 Below_Average Average Typical Typical Good Typical
## 4 Very_Good Average Good Typical Good Typical
## 5 Above_Average Good Typical Typical Typical Good
## 6 Good Average Good Typical Good Typical
## 7 Above_Average Average Typical Typical Good Typical
## 8 Average Average Typical Typical Typical Typical
## 9 Average Good Typical Typical Fair Typical
## 10 Below_Average Average Typical Typical Typical Typical
## # ℹ 2,041 more rows
## # ℹ 5 more variables: Heating_QC <fct>, Kitchen_Qual <fct>,
## # Garage_Qual <fct>, Garage_Cond <fct>, Pool_QC <fct>Ordinal encoding these features provides a natural and intuitive interpretation and can logically be applied to all models.
If your features are already ordered factors then you can simply apply step_ordinalscore() to ordinal encode:
However, if we look at some of our quality features we see they are factors but their levels are not necessarily ordered. Moreover, some have a unique value that represents that feature doesn’t exist in the house (i.e. No_Basement).
train %>% pull(Bsmt_Qual) %>% levels()
## [1] "Excellent" "Fair" "Good" "No_Basement"
## [5] "Poor" "Typical"So in this case we’re going to apply several feature engineering steps to:
- convert quality features to factors with specified levels,
- convert any missed levels (i.e. No_Basement, No_Pool) to “None”,
- move “None” level to front (‘None’, ‘Very_Poor’, …, ‘Very_Excellent’),
- convert factor level to integer value (‘None’ = 0, ‘Very_Poor’ = 1, …, ‘Very_Excellent’ = 11)
# specify levels in order
lvls <- c("Very_Poor", "Poor", "Fair", "Below_Average", "Average", "Typical",
"Above_Average", "Good", "Very_Good", "Excellent", "Very_Excellent")
# apply ordinal encoding to quality features
ord_lbl <- ames_recipe %>%
# 1. convert quality features to factors with specified levels
step_string2factor(matches('Qual$|QC$|_Cond$'), levels = lvls, ordered = TRUE) %>%
# 2. convert any missed levels (i.e. No_Basement, No_Pool) to "None"
step_unknown(matches('Qual$|QC$|_Cond$'), new_level = "None") %>%
# 3. move "None" level to front ('None', 'Very_Poor', ..., 'Very_Excellent')
step_relevel(matches('Qual$|QC$|_Cond$'), ref_level = "None") %>%
# 4. convert factor level to integer value
step_integer(matches('Qual$|QC$|_Cond$'))Did this work, let’s take a look. If we want to apply a recipe to a data set we can apply:
prep: estimate feature engineering parameters based on training data.bake: apply the prepped recipe to new data.
We can see that our quality variables are now ordinal encoded.
baked_recipe <- ord_lbl %>%
prep(training = train) %>%
bake(new_data = train)
baked_recipe %>% select(matches('Qual$|QC$|_Cond$'))
## # A tibble: 2,051 × 11
## Overall_Qual Overall_Cond Exter_Qual Exter_Cond Bsmt_Qual Bsmt_Cond
## <int> <int> <int> <int> <int> <int>
## 1 9 6 4 6 4 4
## 2 7 6 4 6 4 7
## 3 5 6 5 6 4 7
## 4 9 6 4 6 4 7
## 5 7 8 5 6 7 4
## 6 8 6 4 6 4 7
## 7 7 6 5 6 4 7
## 8 6 6 5 6 7 7
## 9 6 8 5 6 3 7
## 10 5 6 5 6 7 7
## # ℹ 2,041 more rows
## # ℹ 5 more variables: Heating_QC <int>, Kitchen_Qual <int>,
## # Garage_Qual <int>, Garage_Cond <int>, Pool_QC <int>And if we want to see how the numeric values are mapped to the original data we can. Here, I just focus on the original Overall_Qual values and how they compare to the encoded values.
encoded_Overall_Qual <- baked_recipe %>%
select(Overall_Qual) %>%
rename(encoded_Overall_Qual = Overall_Qual)
train %>%
select(Overall_Qual) %>%
bind_cols(encoded_Overall_Qual) %>%
count(Overall_Qual, encoded_Overall_Qual)
## # A tibble: 10 × 3
## Overall_Qual encoded_Overall_Qual n
## <fct> <int> <int>
## 1 Very_Poor 2 3
## 2 Poor 3 9
## 3 Fair 4 30
## 4 Below_Average 5 168
## 5 Average 6 587
## 6 Above_Average 7 509
## 7 Good 8 419
## 8 Very_Good 9 235
## 9 Excellent 10 65
## 10 Very_Excellent 11 2627.6.3 Lumping
Sometimes features will contain levels that have very few observations. For example, there are 28 unique neighborhoods represented in the Ames housing data but several of them only have a few observations.
## # A tibble: 28 × 2
## Neighborhood n
## <fct> <int>
## 1 Green_Hills 1
## 2 Landmark 1
## 3 Greens 6
## 4 Blueste 8
## 5 Northpark_Villa 16
## 6 Veenker 18
## 7 Briardale 20
## 8 Bloomington_Heights 22
## 9 Meadow_Village 26
## 10 Clear_Creek 29
## # ℹ 18 more rowsSometimes we can benefit from collapsing, or “lumping” these into a lesser number of categories. In the above examples, we may want to collapse all levels that are observed in less than 1% of the training sample into an “other” category. We can use step_other() to do so. However, lumping should be used sparingly as there is often a loss in model performance (Kuhn and Johnson 2013).
Tree-based models often perform exceptionally well with high cardinality features and are not as impacted by levels with small representation.
The following lumps all neighborhoods that represent less than 1% of observations into an “other” category.
27.7 Fit a model with a recipe
Let’s combine these feature engineering tasks into one recipe and then train a model with it.
ames_recipe <- ames_recipe %>%
step_nzv(all_predictors(), unique_cut = 10) %>%
step_YeoJohnson(all_numeric_predictors()) %>%
step_normalize(all_numeric_predictors()) %>%
step_string2factor(matches('Qual$|QC$|_Cond$'), levels = lvls, ordered = TRUE) %>%
step_unknown(matches('Qual$|QC$|_Cond$'), new_level = "None") %>%
step_relevel(matches('Qual$|QC$|_Cond$'), ref_level = "None") %>%
step_integer(matches('Qual$|QC$|_Cond$')) %>%
step_other(all_nominal_predictors(), threshold = 0.01, other = "other")Let’s go ahead and build a random forest model using the ranger engine (which is the default).
We will want to use our recipe across several steps as we train and test our model. We will:
Process the recipe using the training set: This involves any estimation or calculations based on the training set. For our recipe, the training set will be used to determine which predictors will have zero-variance in the training set, and should be slated for removal, what the mean and scale is in order to standardize the numeric features, etc.
Apply the recipe to the training set: We create the final predictor set on the training set.
Apply the recipe to the test set: We create the final predictor set on the test set. Nothing is recomputed and no information from the test set is used here; the feature engineering statistics computed from the training set are applied to the test set.
To simplify this process, we can use a model workflow, which pairs a model and recipe together. This is a straightforward approach because different recipes are often needed for different models, so when a model and recipe are bundled, it becomes easier to train and test workflows. We’ll use the workflows package from tidymodels to bundle our parsnip model (rf_mod) with our recipe (ames_recipe).
rf_wflow <-
workflow() %>%
add_model(rf_mod) %>%
add_recipe(ames_recipe)
rf_wflow
## ══ Workflow ═══════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: rand_forest()
##
## ── Preprocessor ───────────────────────────────────────────────────────
## 8 Recipe Steps
##
## • step_nzv()
## • step_YeoJohnson()
## • step_normalize()
## • step_string2factor()
## • step_unknown()
## • step_relevel()
## • step_integer()
## • step_other()
##
## ── Model ──────────────────────────────────────────────────────────────
## Random Forest Model Specification (regression)
##
## Computational engine: rangerNow, there is a single function that can be used to prepare the recipe and train the model from the resulting predictors:
The rf_fit object has the finalized recipe and fitted model objects inside. You may want to extract the model or recipe objects from the workflow. To do this, you can use the helper functions extract_fit_parsnip() and extract_recipe().
rf_fit %>%
extract_fit_parsnip()
## parsnip model object
##
## Ranger result
##
## Call:
## ranger::ranger(x = maybe_data_frame(x), y = y, num.threads = 1, verbose = FALSE, seed = sample.int(10^5, 1))
##
## Type: Regression
## Number of trees: 500
## Sample size: 2051
## Number of independent variables: 59
## Mtry: 7
## Target node size: 5
## Variable importance mode: none
## Splitrule: variance
## OOB prediction error (MSE): 678431876
## R squared (OOB): 0.89461Just as in the last lesson, we can make predictions with our fit model object and evaluate the model performance. Here, we compute the RMSE on our test data and we see we have a much better performance than previous models.
rf_fit %>%
predict(test) %>%
bind_cols(test %>% select(Sale_Price)) %>%
rmse(truth = Sale_Price, estimate = .pred)
## # A tibble: 1 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 rmse standard 25330.This improved performance could be a result of using a model that fits the data better, using more features, or from the feature engineering. Or, most likely, a combination of all the above!
27.8 Exercises
Using the ames housing data…
-
Rather than ordinal encode the quality and condition features
(i.e.
step_integer(matches(“Qual|Cond|QC”))), one-hot encode these features. - What is the difference in the number of features in your training set?
- Apply this new recipe to the same random forest model and compute the test RMSE. How does the performance differ?
-
Identify three new feature engineering steps that are provided by recipes:
- Why would these feature engineering steps be applicable to the Ames data?
- Apply these feature engineering steps along with the same random forest model. How do your results change?