11 Lesson 3b: Data transformation
When wrangling data you often need to create some new variables and filter for certain observations of interest, or maybe you just want to rename the variables or reorder the observations in order to make the data a little easier to work with. You’ll learn how to do all that (and more!) in this lesson, which will teach you how to transform your data using the dplyr package
11.1 Learning objectives
Upon completing this module you will be able to:
- Filter a data frame for observations of interest.
- Select and/or rename specific variables.
- Compute summary statistics.
- Sort observations.
- Create new variables.
Note: The data used in the recorded lectures are different then those used in this chapter. If you want to follow along with the recordings be sure to download the supplementary data files, which can be found in canvas.
11.2 Prerequisites
Load the dplyr package to provide you access to the functions we’ll cover in this lesson.
Alternatively, you could load the tidyverse package, which automatically loads the dplyr package.
To illustrate various transformation tasks we will use the following customer transaction data from the completejourney package:
library(completejourney)
(df <- transactions_sample)
## # A tibble: 75,000 × 11
## household_id store_id basket_id product_id quantity sales_value
## <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 2261 309 31625220889 940996 1 3.86
## 2 2131 368 32053127496 873902 1 1.59
## 3 511 316 32445856036 847901 1 1
## 4 400 388 31932241118 13094913 2 11.9
## 5 918 340 32074655895 1085604 1 1.29
## 6 718 324 32614612029 883203 1 2.5
## 7 868 323 32074722463 9884484 1 3.49
## 8 1688 450 34850403304 1028715 1 2
## 9 467 31782 31280745102 896613 2 6.55
## 10 1947 32004 32744181707 978497 1 3.99
## # ℹ 74,990 more rows
## # ℹ 5 more variables: retail_disc <dbl>, coupon_disc <dbl>,
## # coupon_match_disc <dbl>, week <int>, transaction_timestamp <dttm>11.3 Filtering observations
Filtering data is a common task to identify and select observations in which a particular variable matches a specific value or condition. The filter() function provides this capability. The first argument is the name of the data frame. The second and subsequent arguments are the expressions that filter the data frame. For example, if we want to filter for only transactions at the store with ID 309:
filter(df, store_id == "309")
## # A tibble: 426 × 11
## household_id store_id basket_id product_id quantity sales_value
## <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 2261 309 31625220889 940996 1 3.86
## 2 519 309 32931585175 1029743 1 2.69
## 3 1073 309 40532931248 1058997 1 1.89
## 4 517 309 32989806742 5590158 1 1
## 5 1023 309 35713891195 15596520 1 4.59
## 6 1770 309 32505226867 12263600 1 1.5
## 7 1257 309 33983222000 999090 1 3.49
## 8 1509 309 32090471323 1016800 2 6.67
## 9 1167 309 34103947117 1037417 1 3.65
## 10 1836 309 40532932017 879008 1 6.99
## # ℹ 416 more rows
## # ℹ 5 more variables: retail_disc <dbl>, coupon_disc <dbl>,
## # coupon_match_disc <dbl>, week <int>, transaction_timestamp <dttm>
You can pipe data into the filter function using the following
syntax: df %>% filter(store_id == “309”)
When you run that line of code, dplyr executes the filtering operation and returns a new data frame. dplyr functions never modify their inputs, so if you want to save the result, you’ll need to use the assignment operator, <-:
store_309 <- filter(df, store_id == "309")
store_309
## # A tibble: 426 × 11
## household_id store_id basket_id product_id quantity sales_value
## <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 2261 309 31625220889 940996 1 3.86
## 2 519 309 32931585175 1029743 1 2.69
## 3 1073 309 40532931248 1058997 1 1.89
## 4 517 309 32989806742 5590158 1 1
## 5 1023 309 35713891195 15596520 1 4.59
## 6 1770 309 32505226867 12263600 1 1.5
## 7 1257 309 33983222000 999090 1 3.49
## 8 1509 309 32090471323 1016800 2 6.67
## 9 1167 309 34103947117 1037417 1 3.65
## 10 1836 309 40532932017 879008 1 6.99
## # ℹ 416 more rows
## # ℹ 5 more variables: retail_disc <dbl>, coupon_disc <dbl>,
## # coupon_match_disc <dbl>, week <int>, transaction_timestamp <dttm>To use filtering effectively, you have to know how to select the observations that you want using comparison operators. R provides the standard suite of comparison operators to include:
| Operator | Description |
|---|---|
< |
less than |
> |
greater than |
== |
equal to |
!= |
not equal to |
<= |
less than or equal to |
>= |
greater than or equal to |
%in% |
group membership |
is.na |
is NA |
!is.na |
is not NA |
We can apply several of these comparison operators in the filter function using logical operators. The primary logical operators you will use are:
| Operator | Example | Description |
|---|---|---|
& |
x & y |
intersection of x and y |
| |
x \| y |
union of x or y |
! |
x & !y |
x but exclude y and intersect of y |
xor |
xor(x, y) |
only values in x and y that are disjointed with one another |
The following visual representation helps to differentiate how these operators work with fictional x and y data:
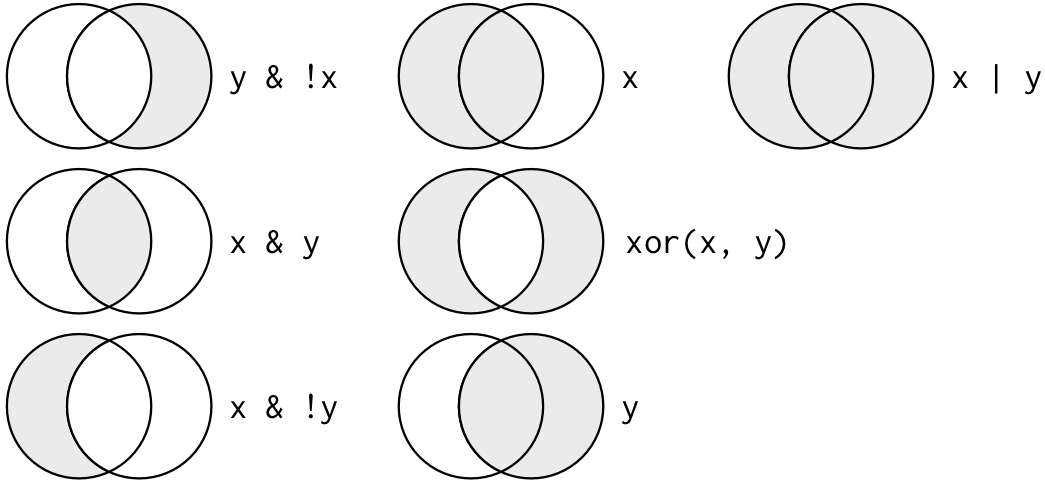
Figure 11.1: Complete set of boolean operations. x is the left-hand circle, y is the right-hand circle, and the shaded region show which parts each operator selects. R4DS
For example, we can filter for transactions for a particular store ID or household ID:
Or if we wanted to filter for transactions for a particular store ID and household ID:
A comma between comparison operators acts just like and
& operator. So
filter(df, store_id == “309”, household_id == “1762”) is
the same as
filter(df, store_id == “309” & household_id == “1762”)
We can continue to add additional operations. In this example we filter for transactions made:
- at a particular store ID,
- by a particular household,
- who purchased more than 4 of a certain product or the product cost more than $10.
df %>% filter(
store_id == "309",
household_id == "1167",
quantity > 4 | sales_value > 10
)
## # A tibble: 3 × 11
## household_id store_id basket_id product_id quantity sales_value
## <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 1167 309 34642351799 8249262 1 15.0
## 2 1167 309 31993100768 941036 1 14.9
## 3 1167 309 40341135791 1051093 6 3
## # ℹ 5 more variables: retail_disc <dbl>, coupon_disc <dbl>,
## # coupon_match_disc <dbl>, week <int>, transaction_timestamp <dttm>A useful shortcut for writing multiple or statements is to use %in%. For example, the following code finds all transactions made at store 309 or 400.
filter(df, store_id == "309" | store_id == "400")
## # A tibble: 1,203 × 11
## household_id store_id basket_id product_id quantity sales_value
## <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 2261 309 31625220889 940996 1 3.86
## 2 1113 400 34204801923 998119 1 3.19
## 3 519 309 32931585175 1029743 1 2.69
## 4 1946 400 41352204380 1120213 3 5
## 5 709 400 40911786843 923559 1 1
## 6 725 400 33106940650 1000664 1 0.34
## 7 1662 400 34258865155 1114465 2 2.08
## 8 1662 400 32065200596 1085939 1 2.19
## 9 1957 400 34338650191 933835 1 0.6
## 10 1925 400 34133653463 13072776 1 1.99
## # ℹ 1,193 more rows
## # ℹ 5 more variables: retail_disc <dbl>, coupon_disc <dbl>,
## # coupon_match_disc <dbl>, week <int>, transaction_timestamp <dttm>The %in% operator allows us to select every row where x is one of the values in y. We could use it to rewrite the code above as:
filter(df, store_id %in% c("309", "400"))
## # A tibble: 1,203 × 11
## household_id store_id basket_id product_id quantity sales_value
## <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 2261 309 31625220889 940996 1 3.86
## 2 1113 400 34204801923 998119 1 3.19
## 3 519 309 32931585175 1029743 1 2.69
## 4 1946 400 41352204380 1120213 3 5
## 5 709 400 40911786843 923559 1 1
## 6 725 400 33106940650 1000664 1 0.34
## 7 1662 400 34258865155 1114465 2 2.08
## 8 1662 400 32065200596 1085939 1 2.19
## 9 1957 400 34338650191 933835 1 0.6
## 10 1925 400 34133653463 13072776 1 1.99
## # ℹ 1,193 more rows
## # ℹ 5 more variables: retail_disc <dbl>, coupon_disc <dbl>,
## # coupon_match_disc <dbl>, week <int>, transaction_timestamp <dttm>There are additional filtering and subsetting functions that are quite useful:
# remove duplicate rows
df %>% distinct()
# random sample, 50% sample size without replacement
df %>% sample_frac(size = 0.5, replace = FALSE)
# random sample of 10 rows with replacement
df %>% sample_n(size = 10, replace = TRUE)
# select rows 3-5
df %>% slice(3:5)
# select top n entries - in this case ranks variable net_spend_amt and selects
# the rows with the top 5 values
df %>% top_n(n = 5, wt = sales_value)
11.3.1 Knowledge check
Using the completejourney sample transactions data as we did above…
- Filter for transactions with greater than 2 units.
- Filter for transactions with greater than 2 units during week 25 that occurred at store 441.
- Filter for transactions with greater than 2 units during week 25 that occurred at store 343 or 441.
- Filter for transactions with greater than 2 units during week 25 that occurred at store 343 or 441 but excludes household 253.
11.4 Selecting variables
It’s not uncommon for us to use data sets with hundreds of variables. In this case, the first challenge is often narrowing in on the variables you’re actually interested in. select allows you to rapidly zoom in on a useful subset using operations based on the names of the variables.
select is not terribly useful with our transaction data because we only have 8 variables, but you can still get the general idea:
# Select columns by name
select(df, household_id, store_id, sales_value)
## # A tibble: 75,000 × 3
## household_id store_id sales_value
## <chr> <chr> <dbl>
## 1 2261 309 3.86
## 2 2131 368 1.59
## 3 511 316 1
## 4 400 388 11.9
## 5 918 340 1.29
## 6 718 324 2.5
## 7 868 323 3.49
## 8 1688 450 2
## 9 467 31782 6.55
## 10 1947 32004 3.99
## # ℹ 74,990 more rows
# Select all columns between household_id and sales_value (inclusive)
select(df, household_id:sales_value)
## # A tibble: 75,000 × 6
## household_id store_id basket_id product_id quantity sales_value
## <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 2261 309 31625220889 940996 1 3.86
## 2 2131 368 32053127496 873902 1 1.59
## 3 511 316 32445856036 847901 1 1
## 4 400 388 31932241118 13094913 2 11.9
## 5 918 340 32074655895 1085604 1 1.29
## 6 718 324 32614612029 883203 1 2.5
## 7 868 323 32074722463 9884484 1 3.49
## 8 1688 450 34850403304 1028715 1 2
## 9 467 31782 31280745102 896613 2 6.55
## 10 1947 32004 32744181707 978497 1 3.99
## # ℹ 74,990 more rows
# Select all columns except those between household_id and sales_value
select(df, -c(household_id:sales_value))
## # A tibble: 75,000 × 5
## retail_disc coupon_disc coupon_match_disc week
## <dbl> <dbl> <dbl> <int>
## 1 0.43 0 0 5
## 2 0.9 0 0 10
## 3 0.69 0 0 13
## 4 2.9 0 0 8
## 5 0 0 0 10
## 6 0.49 0 0 15
## 7 0 0 0 10
## 8 1.79 0 0 33
## 9 4.44 0 0 2
## 10 0 0 0 16
## # ℹ 74,990 more rows
## # ℹ 1 more variable: transaction_timestamp <dttm>There are a number of helper functions you can use within select:
starts_with("abc"): matches names that begin with “abc”.ends_with("xyz"): matches names that end with “xyz”.contains("ijk"): matches names that contain “ijk”.matches("(.)\\1"): selects variables that match a regular expression. This one matches any variables that contain repeated characters. You’ll learn more about regular expressions in the character strings chapter.num_range("x", 1:3): matches x1, x2 and x3.
See ?select for more details.
For example, we can select all variables that contain “id” in their name:
select(df, contains("id"))
## # A tibble: 75,000 × 4
## household_id store_id basket_id product_id
## <chr> <chr> <chr> <chr>
## 1 2261 309 31625220889 940996
## 2 2131 368 32053127496 873902
## 3 511 316 32445856036 847901
## 4 400 388 31932241118 13094913
## 5 918 340 32074655895 1085604
## 6 718 324 32614612029 883203
## 7 868 323 32074722463 9884484
## 8 1688 450 34850403304 1028715
## 9 467 31782 31280745102 896613
## 10 1947 32004 32744181707 978497
## # ℹ 74,990 more rowsselect can be used to rename variables, but it’s rarely useful because it drops all of the variables not explicitly mentioned. Instead, use rename, which is a variant of select that keeps all the variables that aren’t explicitly mentioned:
rename(df, store = store_id, product = product_id)
## # A tibble: 75,000 × 11
## household_id store basket_id product quantity sales_value
## <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 2261 309 31625220889 940996 1 3.86
## 2 2131 368 32053127496 873902 1 1.59
## 3 511 316 32445856036 847901 1 1
## 4 400 388 31932241118 13094913 2 11.9
## 5 918 340 32074655895 1085604 1 1.29
## 6 718 324 32614612029 883203 1 2.5
## 7 868 323 32074722463 9884484 1 3.49
## 8 1688 450 34850403304 1028715 1 2
## 9 467 31782 31280745102 896613 2 6.55
## 10 1947 32004 32744181707 978497 1 3.99
## # ℹ 74,990 more rows
## # ℹ 5 more variables: retail_disc <dbl>, coupon_disc <dbl>,
## # coupon_match_disc <dbl>, week <int>, transaction_timestamp <dttm>Another option is to use select in conjunction with the everything helper. This is useful if you have a handful of variables you’d like to move to the start of the data frame.
select(df, household_id, quantity, sales_value, everything())
## # A tibble: 75,000 × 11
## household_id quantity sales_value store_id basket_id product_id
## <chr> <dbl> <dbl> <chr> <chr> <chr>
## 1 2261 1 3.86 309 31625220889 940996
## 2 2131 1 1.59 368 32053127496 873902
## 3 511 1 1 316 32445856036 847901
## 4 400 2 11.9 388 31932241118 13094913
## 5 918 1 1.29 340 32074655895 1085604
## 6 718 1 2.5 324 32614612029 883203
## 7 868 1 3.49 323 32074722463 9884484
## 8 1688 1 2 450 34850403304 1028715
## 9 467 2 6.55 31782 31280745102 896613
## 10 1947 1 3.99 32004 32744181707 978497
## # ℹ 74,990 more rows
## # ℹ 5 more variables: retail_disc <dbl>, coupon_disc <dbl>,
## # coupon_match_disc <dbl>, week <int>, transaction_timestamp <dttm>
11.5 Computing summary statistics
Obviously the goal of all this data wrangling is to be able to perform statistical analysis on our data. The summarize function allows us to perform the majority of the initial summary statistics when performing exploratory data analysis. For example, we can compute the mean sales_value across all observations:
summarise(df, avg_sales_value = mean(sales_value))
## # A tibble: 1 × 1
## avg_sales_value
## <dbl>
## 1 3.12
These data have no missing values. However, if there are missing
values you will need to use na.rm = TRUE in the function to
remove missing values prior to computing the summary statistic:
summarize(df, avg_sales_value = mean(sales_value, na.rm = TRUE))
There are a wide variety of functions you can use within summarize(). For example, the following lists just a few examples:
| Function | Description |
|---|---|
min(), max() |
min, max values in vector |
mean() |
mean value |
median() |
median value |
sum() |
sum of all vector values |
var(), sd() |
variance/std of vector |
first(), last() |
first/last value in vector |
nth() |
nth value in vector |
n() |
number of values in vector |
n_distinct() |
number of distinct values in vector |
As long as the function reduces a vector of values down to a single summarized value, you can use it in summarize().
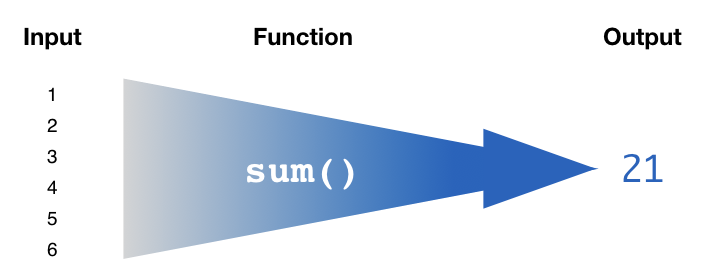
Figure 11.2: Summarize functions need to condense a vector input down to a single summarized output value.
summarize is not terribly useful unless we pair it with another function called group_by. This changes the unit of analysis from the complete data set to individual groups. Then, when you use the dplyr verbs on a grouped data frame they’ll be automatically applied “by group”. For example, if we applied exactly the same code to a data frame grouped by store_id, we get the average sales value for each store_id level:
by_store <- group_by(df, store_id)
summarize(by_store, avg_sales_value = mean(sales_value))
## # A tibble: 293 × 2
## store_id avg_sales_value
## <chr> <dbl>
## 1 108 14.0
## 2 1089 1
## 3 1098 2.28
## 4 1102 1.17
## 5 112 1.39
## 6 1132 0.71
## 7 1240 1
## 8 1247 0.39
## 9 1252 0.99
## 10 134 1.89
## # ℹ 283 more rowsA more efficient way to write this same code is to use the pipe operator:
df %>%
group_by(store_id) %>%
summarize(avg_sales_value = mean(sales_value))
## # A tibble: 293 × 2
## store_id avg_sales_value
## <chr> <dbl>
## 1 108 14.0
## 2 1089 1
## 3 1098 2.28
## 4 1102 1.17
## 5 112 1.39
## 6 1132 0.71
## 7 1240 1
## 8 1247 0.39
## 9 1252 0.99
## 10 134 1.89
## # ℹ 283 more rowsWe can compute multiple summary statistics:
df %>%
group_by(store_id) %>%
summarize(
`10%` = quantile(sales_value, .1),
`50%` = quantile(sales_value, .5),
avg_sales_value = mean(sales_value),
`90%` = quantile(sales_value, .9),
sd = sd(sales_value),
n()
)
## # A tibble: 293 × 7
## store_id `10%` `50%` avg_sales_value `90%` sd `n()`
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <int>
## 1 108 14.0 14.0 14.0 14.0 0 2
## 2 1089 1 1 1 1 NA 1
## 3 1098 2.28 2.28 2.28 2.28 NA 1
## 4 1102 0.55 0.825 1.17 2.07 0.916 4
## 5 112 0.94 1.09 1.39 2.13 0.652 6
## 6 1132 0.39 0.39 0.71 1.35 0.716 5
## 7 1240 1 1 1 1 NA 1
## 8 1247 0.39 0.39 0.39 0.39 NA 1
## 9 1252 0.99 0.99 0.99 0.99 NA 1
## 10 134 1.89 1.89 1.89 1.89 NA 1
## # ℹ 283 more rowsThere are additional summarize alternative functions that are quite useful. Test these out and see how they work:
# compute the average for multiple specified variables
df %>% summarize_at(c("sales_value", "quantity"), mean)
# compute the average for all numeric variables
df %>% summarize_if(is.numeric, mean) summarize is a very universal function that can be used on continuous and categorical variables; however, count is a great function to use to compute the number of observations for each level of a categorical variable (or a combination of categorical variables):
# number of observations in each level of store_id
count(df, store_id)
## # A tibble: 293 × 2
## store_id n
## <chr> <int>
## 1 108 2
## 2 1089 1
## 3 1098 1
## 4 1102 4
## 5 112 6
## 6 1132 5
## 7 1240 1
## 8 1247 1
## 9 1252 1
## 10 134 1
## # ℹ 283 more rows
# number of observations in each level of store_id and sort output
count(df, store_id, sort = TRUE)
## # A tibble: 293 × 2
## store_id n
## <chr> <int>
## 1 367 2129
## 2 406 1634
## 3 356 1386
## 4 292 1333
## 5 31782 1238
## 6 343 1220
## 7 381 1211
## 8 361 1149
## 9 32004 1128
## 10 321 1106
## # ℹ 283 more rows
# number of observations in each combination of sort_id & product_id
count(df, store_id, product_id, sort = TRUE)
## # A tibble: 63,652 × 3
## store_id product_id n
## <chr> <chr> <int>
## 1 367 1082185 34
## 2 375 6534178 33
## 3 422 6534178 33
## 4 429 6534178 32
## 5 343 6534178 28
## 6 406 6534178 28
## 7 367 6534178 24
## 8 361 6534178 23
## 9 406 1082185 23
## 10 31862 1082185 21
## # ℹ 63,642 more rows
11.5.1 Knowledge check
Using the completejourney sample transactions data as we did above…
- Compute the total quantity of items purchased across all transactions.
- Compute the total quantity of items purchased by household.
- Compute the total quantity of items purchased by household for only transactions at store 309 where the quantity purchased was greater than one.
11.6 Sorting observations
Often, we desire to view observations in rank order for a particular variable(s). The arrange function allows us to order data by variables in ascending or descending order. For example, we can sort our observations based on sales_value:
# default is ascending order
arrange(df, sales_value)
## # A tibble: 75,000 × 11
## household_id store_id basket_id product_id quantity sales_value
## <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 1038 340 31389956808 983659 0 0
## 2 1166 408 31969185576 5978656 0 0
## 3 1397 381 40800715180 8020001 0 0
## 4 1889 369 33433310971 903325 0 0
## 5 1241 368 31834162699 7441102 0 0
## 6 867 369 40436331223 5978656 0 0
## 7 2204 367 33397465730 887782 0 0
## 8 40 406 40085429046 5978648 0 0
## 9 1100 358 41125111338 976199 0 0
## 10 1829 445 33655105183 1014948 1 0
## # ℹ 74,990 more rows
## # ℹ 5 more variables: retail_disc <dbl>, coupon_disc <dbl>,
## # coupon_match_disc <dbl>, week <int>, transaction_timestamp <dttm>
# use desc() for descending order
arrange(df, desc(sales_value))
## # A tibble: 75,000 × 11
## household_id store_id basket_id product_id quantity sales_value
## <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 1246 334 32005986123 12484608 1 100
## 2 2318 381 31993236318 13040176 1 100.
## 3 1172 396 34338411595 15630122 1 88.9
## 4 1959 736 33510101062 5716076 30080 86.0
## 5 1959 323 34811925575 6544236 26325 75
## 6 2133 433 35727256342 6534178 32623 75
## 7 1764 327 33971056246 6534178 24583 68.8
## 8 1959 384 34103546818 6544236 23519 67.0
## 9 2312 442 41351830986 916561 1 66.1
## 10 2360 323 35463937998 12812261 8 65.6
## # ℹ 74,990 more rows
## # ℹ 5 more variables: retail_disc <dbl>, coupon_disc <dbl>,
## # coupon_match_disc <dbl>, week <int>, transaction_timestamp <dttm>This function becomes particularly useful when combining with summary statistics. For example, we can quickly find the product with the largest average sales value amount by adding arrange to the end of this sequence of functions:
df %>%
group_by(product_id) %>%
summarize(avg_sales_value = mean(sales_value)) %>%
arrange(desc(avg_sales_value))
## # A tibble: 20,902 × 2
## product_id avg_sales_value
## <chr> <dbl>
## 1 13040176 100.
## 2 15630122 88.9
## 3 5716076 86.0
## 4 1100869 63.7
## 5 904021 63.7
## 6 1775642 62.9
## 7 5668996 62.0
## 8 6544236 60.0
## 9 5571881 60.0
## 10 839075 56.0
## # ℹ 20,892 more rows
Missing values (NAs) will always be moved to the end of
the list regardless if you perform ascending or descending sorting.
11.6.1 Knowledge check
- Compute the average sales value by household and arrange in descending order to find the household with the largest average spend.
- Find the products with the largest median spend.
- Compute the total quantity of items purchased by household for only transactions at store 309 where the quantity purchased was greater than one. Which household purchased the largest quantity of items?
Check out this video to reinforce the idea of the pipe operator.
11.7 Creating new variables
Often, we want to create a new variable that is a function of the current variables in our data frame. The mutate function allows us to add new variables while preserving the existing variables. For example, we can compute the net spend per item by dividing sales_value by quantity.
mutate(df, spend_per_item = sales_value / quantity)
## # A tibble: 75,000 × 12
## household_id store_id basket_id product_id quantity sales_value
## <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 2261 309 31625220889 940996 1 3.86
## 2 2131 368 32053127496 873902 1 1.59
## 3 511 316 32445856036 847901 1 1
## 4 400 388 31932241118 13094913 2 11.9
## 5 918 340 32074655895 1085604 1 1.29
## 6 718 324 32614612029 883203 1 2.5
## 7 868 323 32074722463 9884484 1 3.49
## 8 1688 450 34850403304 1028715 1 2
## 9 467 31782 31280745102 896613 2 6.55
## 10 1947 32004 32744181707 978497 1 3.99
## # ℹ 74,990 more rows
## # ℹ 6 more variables: retail_disc <dbl>, coupon_disc <dbl>,
## # coupon_match_disc <dbl>, week <int>, transaction_timestamp <dttm>,
## # spend_per_item <dbl>
mutate always adds new columns at the end of your
dataset.
There are many functions for creating new variables that you can use with mutate. The key property is that the function must be vectorized: it must take a vector of values as input, return a vector with the same number of values as output. There’s no way to list every possible function that you might use, but here’s a selection of functions that are frequently useful:
| Function | Description |
|---|---|
+,-,*,/,^ |
arithmetic |
x / sum(x) |
arithmetic w/aggregation |
%/%, %% |
modular arithmetic |
log, exp, sqrt |
transformations |
lag, lead |
offsets |
cumsum, cumprod, cum... |
cum/rolling aggregates |
>, >=, <, <=, !=, == |
logical comparisons |
min_rank, dense_rank |
ranking |
between |
are values between a and b? |
ntile |
bin values into n buckets |
The following provides a few examples of integrating these functions with mutate.
# reduce the number of variables so you can see the transformations
df2 <- select(df, household_id, quantity, sales_value, transaction_timestamp)
# compute total net spend amount per item
df2 %>% mutate(spend_per_item = sales_value / quantity)
## # A tibble: 75,000 × 5
## household_id quantity sales_value transaction_timestamp
## <chr> <dbl> <dbl> <dttm>
## 1 2261 1 3.86 2017-01-28 14:06:53
## 2 2131 1 1.59 2017-02-28 22:31:57
## 3 511 1 1 2017-03-26 13:22:21
## 4 400 2 11.9 2017-02-18 13:13:10
## 5 918 1 1.29 2017-03-02 15:05:57
## 6 718 1 2.5 2017-04-05 18:14:17
## 7 868 1 3.49 2017-03-02 17:45:37
## 8 1688 1 2 2017-08-11 22:41:02
## 9 467 2 6.55 2017-01-06 07:47:01
## 10 1947 1 3.99 2017-04-13 17:30:04
## # ℹ 74,990 more rows
## # ℹ 1 more variable: spend_per_item <dbl>
# log transform sales_value
df2 %>% mutate(log_sales_value = log(sales_value))
## # A tibble: 75,000 × 5
## household_id quantity sales_value transaction_timestamp
## <chr> <dbl> <dbl> <dttm>
## 1 2261 1 3.86 2017-01-28 14:06:53
## 2 2131 1 1.59 2017-02-28 22:31:57
## 3 511 1 1 2017-03-26 13:22:21
## 4 400 2 11.9 2017-02-18 13:13:10
## 5 918 1 1.29 2017-03-02 15:05:57
## 6 718 1 2.5 2017-04-05 18:14:17
## 7 868 1 3.49 2017-03-02 17:45:37
## 8 1688 1 2 2017-08-11 22:41:02
## 9 467 2 6.55 2017-01-06 07:47:01
## 10 1947 1 3.99 2017-04-13 17:30:04
## # ℹ 74,990 more rows
## # ℹ 1 more variable: log_sales_value <dbl>
# order by date and compute the cumulative sum
df2 %>%
arrange(transaction_timestamp) %>%
mutate(cumsum_sales_value = cumsum(sales_value))
## # A tibble: 75,000 × 5
## household_id quantity sales_value transaction_timestamp
## <chr> <dbl> <dbl> <dttm>
## 1 906 1 1.5 2017-01-01 07:30:27
## 2 1873 1 1.88 2017-01-01 08:47:20
## 3 993 1 3.49 2017-01-01 09:16:13
## 4 1465 1 1.38 2017-01-01 09:46:04
## 5 239 1 1.59 2017-01-01 10:05:51
## 6 58 1 2.49 2017-01-01 10:14:16
## 7 1519 2 3.55 2017-01-01 10:32:09
## 8 1130 1 3.77 2017-01-01 10:38:18
## 9 2329 1 3.99 2017-01-01 10:46:03
## 10 2329 1 3.59 2017-01-01 10:46:03
## # ℹ 74,990 more rows
## # ℹ 1 more variable: cumsum_sales_value <dbl>
# compute sum of sales_value for each product and
# rank order totals across 25 bins
df %>%
group_by(product_id) %>%
summarize(total = sum(sales_value)) %>%
mutate(bins = ntile(total, 25))
## # A tibble: 20,902 × 3
## product_id total bins
## <chr> <dbl> <int>
## 1 1000002 18.4 23
## 2 1000050 33.9 24
## 3 1000106 6.47 15
## 4 1000140 3.29 9
## 5 1000148 6 15
## 6 1000165 3.34 9
## 7 1000204 6.17 15
## 8 1000205 3.98 10
## 9 1000228 2.34 6
## 10 1000236 5.39 14
## # ℹ 20,892 more rows
11.7.1 Knowledge check
Using the completejourney sample transactions data as we did above…
-
Create a new column (
total_disc) that is the sum of all discounts applied to each transaction (total_disc = coupon_disc + retail_disc + coupon_match_disc). -
Create a new column (
disc_to_sales) that computes the ratio of total discount to total sales value (total_disc/sales_value). -
Using the results from #2, create a new column
binsthat bins thedisc_to_salescolumn into 10 bins. Filter for those transactions with the highest discount to sales ratio (bin 10).
11.8 Putting it altogether
The beauty of dplyr is how it makes exploratory data analysis very simple and efficient. For example, we can combine all the above functions to:
- group the data by
store_idandproduct_id, - compute the total
sales_value, - create a rank order variable,
- filter for the top 5 products within each store with the highest total sales value,
- sort total by descending order.
df %>%
group_by(store_id, product_id) %>%
summarize(total = sum(sales_value)) %>%
mutate(rank = min_rank(desc(total))) %>%
filter(rank <= 5) %>%
arrange(desc(total))
## `summarise()` has grouped output by 'store_id'. You can override using
## the `.groups` argument.
## # A tibble: 1,064 × 4
## # Groups: store_id [293]
## store_id product_id total rank
## <chr> <chr> <dbl> <int>
## 1 375 6534178 1057. 1
## 2 429 6534178 980. 1
## 3 406 6534178 922 1
## 4 343 6534178 711. 1
## 5 422 6534178 658. 1
## 6 367 6534178 631. 1
## 7 329 6534178 582. 1
## 8 361 6534178 553. 1
## 9 429 6533889 494. 2
## 10 33923 6534178 478. 1
## # ℹ 1,054 more rows11.9 Exercises
Using what you’ve learned thus far, can you find the store and week that experienced the greatest week over week growth in the number of units sold?
The steps to follow include:
- Group by store and week
- Compute sum of the quantity of items sold
-
Create week over week percent growth in total units sold. You may
want to check out the
lag()function for this step. - Arrange in descending order
See the code chunk hint below.